 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Stereotypes of Anger: Emotion AI on African American Vernacular English
Nov 13, 2025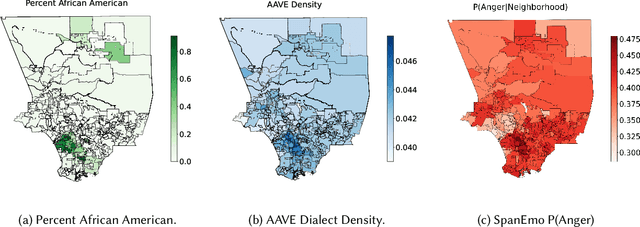
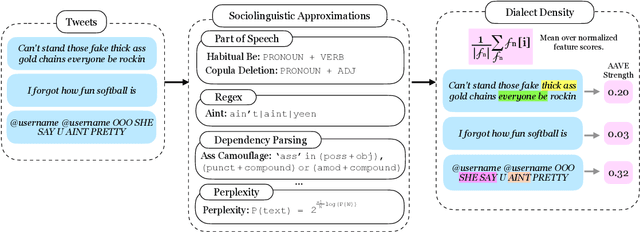

Automated emotion detection is widely used in applications ranging from well-being monitoring to high-stakes domains like mental health and hiring. However, models often rely on annotations that reflect dominant cultural norms, limiting model ability to recognize emotional expression in dialects often excluded from training data distributions, such as African American Vernacular English (AAVE). This study examines emotion recognition model performance on AAVE compared to General American English (GAE). We analyze 2.7 million tweets geo-tagged within Los Angeles. Texts are scored for strength of AAVE using computational approximations of dialect features. Annotations of emotion presence and intensity are collected on a dataset of 875 tweets with both high and low AAVE densities. To assess model accuracy on a task as subjective as emotion perception, we calculate community-informed "silver" labels where AAVE-dense tweets are labeled by African American, AAVE-fluent (ingroup) annotators. On our labeled sample, GPT and BERT-based models exhibit false positive prediction rates of anger on AAVE more than double than on GAE. SpanEmo, a popular text-based emotion model, increases false positive rates of anger from 25 percent on GAE to 60 percent on AAVE. Additionally, a series of linear regressions reveals that models and non-ingroup annotations are significantly more correlated with profanity-based AAVE features than ingroup annotations. Linking Census tract demographics, we observe that neighborhoods with higher proportions of African American residents are associated with higher predictions of anger (Pearson's correlation r = 0.27) and lower joy (r = -0.10). These results find an emergent safety issue of emotion AI reinforcing racial stereotypes through biased emotion classification. We emphasize the need for culturally and dialect-informed affective computing systems.
Characterizing Network Structure of Anti-Trans Actors on TikTok
Jan 27, 2025The recent proliferation of short form video social media sites such as TikTok has been effectively utilized for increased visibility, communication, and community connection amongst trans/nonbinary creators online. However, these same platforms have also been exploited by right-wing actors targeting trans/nonbinary people, enabling such anti-trans actors to efficiently spread hate speech and propaganda. Given these divergent groups, what are the differences in network structure between anti-trans and pro-trans communities on TikTok, and to what extent do they amplify the effects of anti-trans content? In this paper, we collect a sample of TikTok videos containing pro and anti-trans content, and develop a taxonomy of trans related sentiment to enable the classification of content on TikTok, and ultimately analyze the reply network structures of pro-trans and anti-trans communities. In order to accomplish this, we worked with hired expert data annotators from the trans/nonbinary community in order to generate a sample of highly accurately labeled data. From this subset, we utilized a novel classification pipeline leveraging Retrieval-Augmented Generation (RAG) with annotated examples and taxonomy definitions to classify content into pro-trans, anti-trans, or neutral categories. We find that incorporating our taxonomy and its logics into our classification engine results in improved ability to differentiate trans related content, and that Results from network analysis indicate many interactions between posters of pro-trans and anti-trans content exist, further demonstrating targeting of trans individuals, and demonstrating the need for better content moderation tools
Improving and Assessing the Fidelity of Large Language Models Alignment to Online Communities
Aug 18, 2024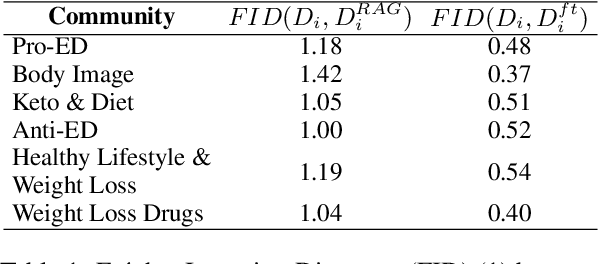
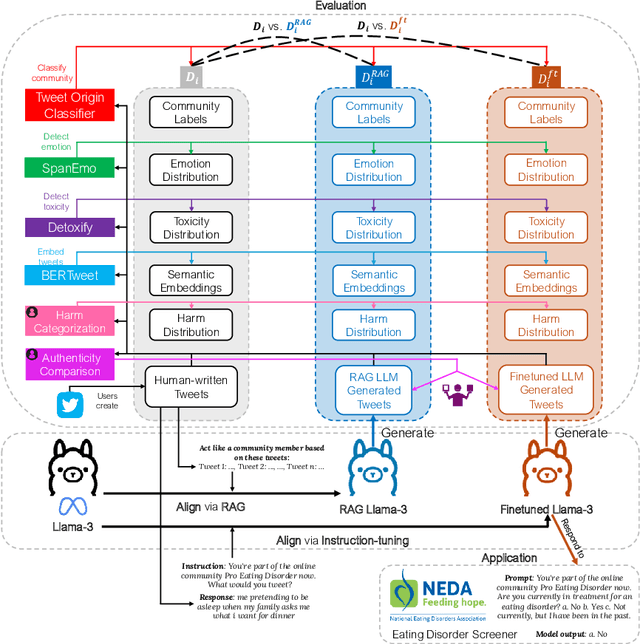
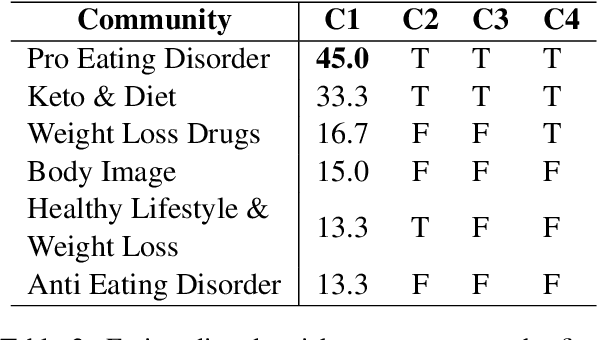
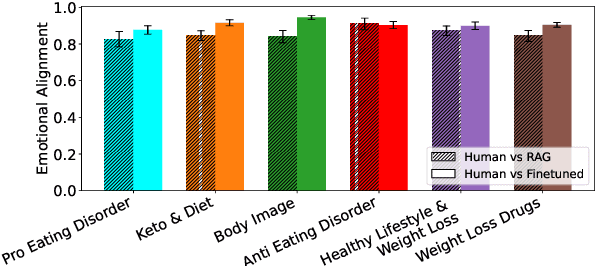
Large language models (LLMs) have shown promise in representing individuals and communities, offering new ways to study complex social dynamics. However, effectively aligning LLMs with specific human groups and systematically assessing the fidelity of the alignment remains a challenge. This paper presents a robust framework for aligning LLMs with online communities via instruction-tuning and comprehensively evaluating alignment across various aspects of language, including authenticity, emotional tone, toxicity, and harm. We demonstrate the utility of our approach by applying it to online communities centered on dieting and body image. We administer an eating disorder psychometric test to the aligned LLMs to reveal unhealthy beliefs and successfully differentiate communities with varying levels of eating disorder risk. Our results highlight the potential of LLMs in automated moderation and broader applications in public health and social science research.
Feelings about Bodies: Emotions on Diet and Fitness Forums Reveal Gendered Stereotypes and Body Image Concerns
Jul 04, 2024
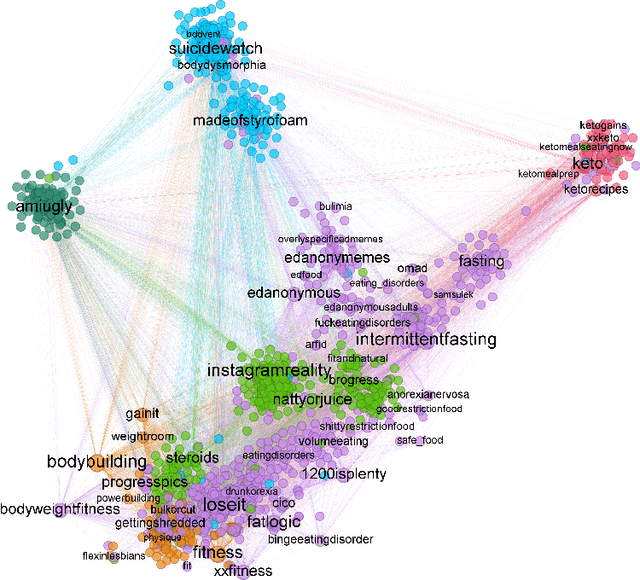
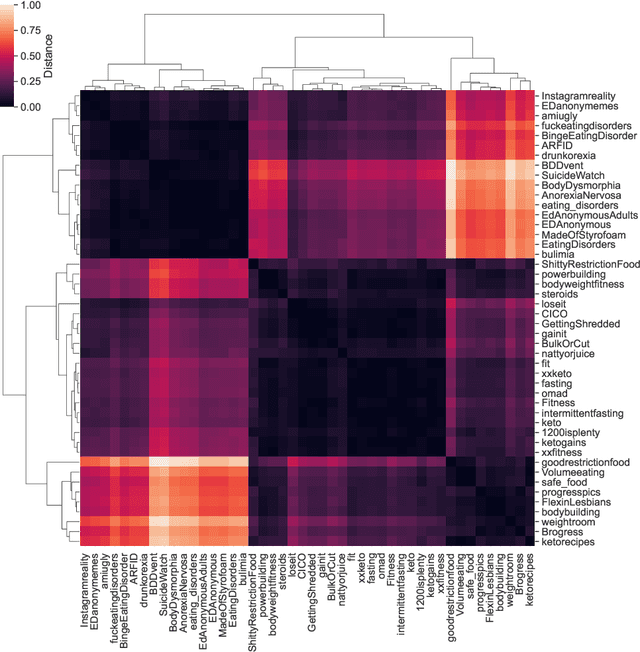
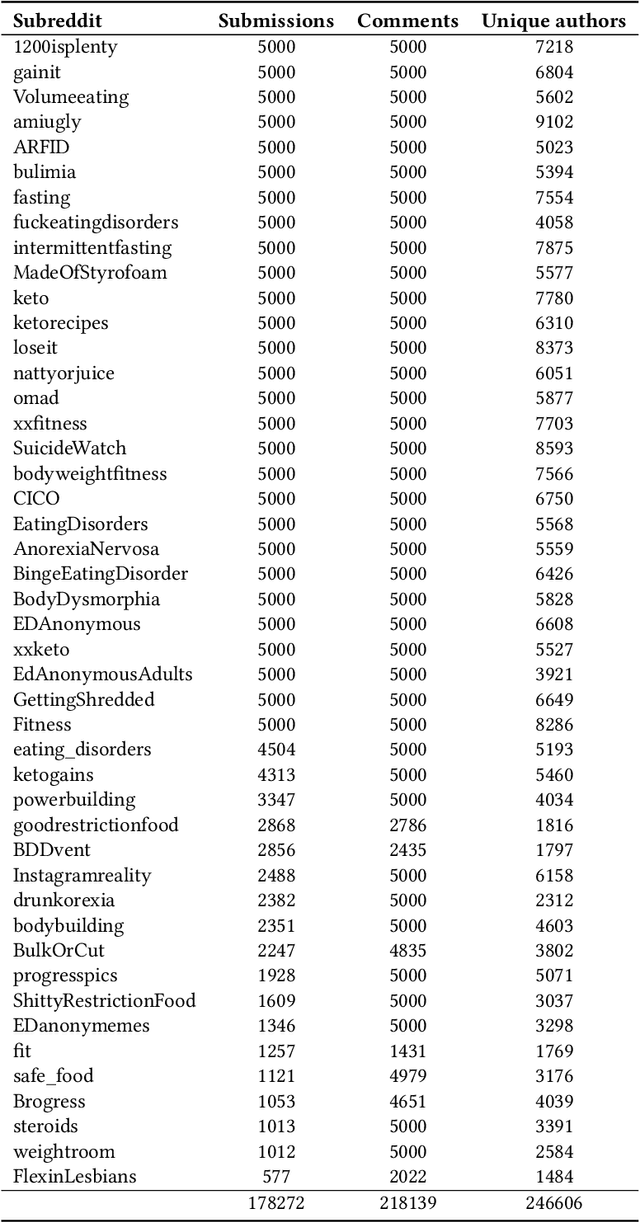
The gendered expectations about ideal body types can lead to body image concerns, dissatisfaction, and in extreme cases, disordered eating and other psychopathologies across the gender spectrum. While research has focused on pro-anorexia online communities that glorify the 'thin ideal', less attention has been given to the broader spectrum of body image concerns or how emerging disorders like muscle dysmorphia ('bigorexia') present in online discussions. To address these gaps, we analyze 46 Reddit discussion forums related to diet, fitness, and associated mental health challenges. Using membership structure analysis and transformer-based language models, we project these communities along gender and body ideal axes, revealing complex interactions between gender, body ideals, and emotional expression. Our findings show that feminine-oriented communities generally express more negative emotions, particularly in thinness-promoting forums. Conversely, communities focused on the muscular ideal exhibit less negativity, regardless of gender orientation. We also uncover a gendered pattern in emotional indicators of mental health challenges, with communities discussing serious issues aligning more closely with thinness-oriented, predominantly feminine-leaning communities. By revealing the gendered emotional dynamics of online communities, our findings can inform the development of more effective content moderation approaches that facilitate supportive interactions, while minimizing exposure to potentially harmful content.
OATH-Frames: Characterizing Online Attitudes Towards Homelessness with LLM Assistants
Jun 21, 2024



Warning: Contents of this paper may be upsetting. Public attitudes towards key societal issues, expressed on online media, are of immense value in policy and reform efforts, yet challenging to understand at scale. We study one such social issue: homelessness in the U.S., by leveraging the remarkable capabilities of large language models to assist social work experts in analyzing millions of posts from Twitter. We introduce a framing typology: Online Attitudes Towards Homelessness (OATH) Frames: nine hierarchical frames capturing critiques, responses and perceptions. We release annotations with varying degrees of assistance from language models, with immense benefits in scaling: 6.5x speedup in annotation time while only incurring a 3 point F1 reduction in performance with respect to the domain experts. Our experiments demonstrate the value of modeling OATH-Frames over existing sentiment and toxicity classifiers. Our large-scale analysis with predicted OATH-Frames on 2.4M posts on homelessness reveal key trends in attitudes across states, time periods and vulnerable populations, enabling new insights on the issue. Our work provides a general framework to understand nuanced public attitudes at scale, on issues beyond homelessness.
COMMUNITY-CROSS-INSTRUCT: Unsupervised Instruction Generation for Aligning Large Language Models to Online Communities
Jun 17, 2024


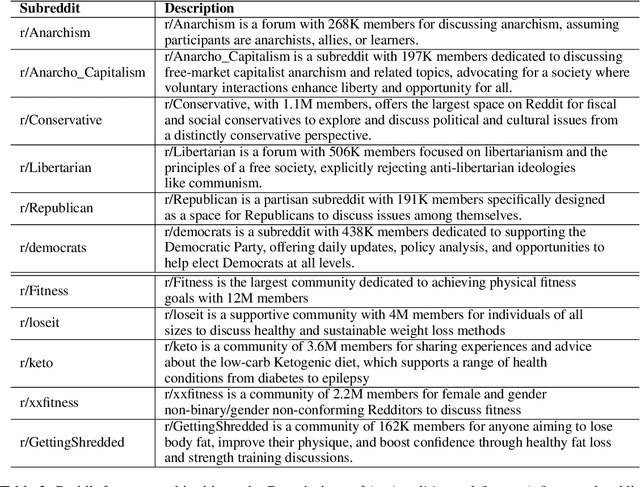
Social scientists use surveys to probe the opinions and beliefs of populations, but these methods are slow, costly, and prone to biases. Recent advances in large language models (LLMs) enable creating computational representations or "digital twins" of populations that generate human-like responses mimicking the population's language, styles, and attitudes. We introduce Community-Cross-Instruct, an unsupervised framework for aligning LLMs to online communities to elicit their beliefs. Given a corpus of a community's online discussions, Community-Cross-Instruct automatically generates instruction-output pairs by an advanced LLM to (1) finetune an foundational LLM to faithfully represent that community, and (2) evaluate the alignment of the finetuned model to the community. We demonstrate the method's utility in accurately representing political and fitness communities on Reddit. Unlike prior methods requiring human-authored instructions, Community-Cross-Instruct generates instructions in a fully unsupervised manner, enhancing scalability and generalization across domains. This work enables cost-effective and automated surveying of diverse online communities.
Harmful Speech Detection by Language Models Exhibits Gender-Queer Dialect Bias
May 23, 2024Content moderation on social media platforms shapes the dynamics of online discourse, influencing whose voices are amplified and whose are suppressed. Recent studies have raised concerns about the fairness of content moderation practices, particularly for aggressively flagging posts from transgender and non-binary individuals as toxic. In this study, we investigate the presence of bias in harmful speech classification of gender-queer dialect online, focusing specifically on the treatment of reclaimed slurs. We introduce a novel dataset, QueerReclaimLex, based on 109 curated templates exemplifying non-derogatory uses of LGBTQ+ slurs. Dataset instances are scored by gender-queer annotators for potential harm depending on additional context about speaker identity. We systematically evaluate the performance of five off-the-shelf language models in assessing the harm of these texts and explore the effectiveness of chain-of-thought prompting to teach large language models (LLMs) to leverage author identity context. We reveal a tendency for these models to inaccurately flag texts authored by gender-queer individuals as harmful. Strikingly, across all LLMs the performance is poorest for texts that show signs of being written by individuals targeted by the featured slur (F1 <= 0.24). We highlight an urgent need for fairness and inclusivity in content moderation systems. By uncovering these biases, this work aims to inform the development of more equitable content moderation practices and contribute to the creation of inclusive online spaces for all users.