 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward AI Matching Policies in Homeless Services: A Qualitative Study with Policymakers
Aug 10, 2025Artificial intelligence researchers have proposed various data-driven algorithms to improve the processes that match individuals experiencing homelessness to scarce housing resources. It remains unclear whether and how these algorithms are received or adopted by practitioners and what their corresponding consequences are. Through semi-structured interviews with 13 policymakers in homeless services in Los Angeles, we investigate whether such change-makers are open to the idea of integrating AI into the housing resource matching process, identifying where they see potential gains and drawbacks from such a system in issues of efficiency, fairness, and transparency. Our qualitative analysis indicates that, even when aware of various complicating factors, policymakers welcome the idea of an AI matching tool if thoughtfully designed and used in tandem with human decision-makers. Though there is no consensus as to the exact design of such an AI system, insights from policymakers raise open questions and design considerations that can be enlightening for future researchers and practitioners who aim to build responsible algorithmic systems to support decision-making in low-resource scenarios.
Peer Disambiguation in Self-Reported Surveys using Graph Attention Networks
Mar 25, 2025Studying peer relationships is crucial in solving complex challenges underserved communities face and designing interventions. The effectiveness of such peer-based interventions relies on accurate network data regarding individual attributes and social influences. However, these datasets are often collected through self-reported surveys, introducing ambiguities in network construction. These ambiguities make it challenging to fully utilize the network data to understand the issues and to design the best interventions. We propose and solve two variations of link ambiguities in such network data -- (i) which among the two candidate links exists, and (ii) if a candidate link exists. We design a Graph Attention Network (GAT) that accounts for personal attributes and network relationships on real-world data with real and simulated ambiguities. We also demonstrate that by resolving these ambiguities, we improve network accuracy, and in turn, improve suicide risk prediction. We also uncover patterns using GNNExplainer to provide additional insights into vital features and relationships. This research demonstrates the potential of Graph Neural Networks (GNN) to advance real-world network data analysis facilitating more effective peer interventions across various fields.
OATH-Frames: Characterizing Online Attitudes Towards Homelessness with LLM Assistants
Jun 21, 2024



Warning: Contents of this paper may be upsetting. Public attitudes towards key societal issues, expressed on online media, are of immense value in policy and reform efforts, yet challenging to understand at scale. We study one such social issue: homelessness in the U.S., by leveraging the remarkable capabilities of large language models to assist social work experts in analyzing millions of posts from Twitter. We introduce a framing typology: Online Attitudes Towards Homelessness (OATH) Frames: nine hierarchical frames capturing critiques, responses and perceptions. We release annotations with varying degrees of assistance from language models, with immense benefits in scaling: 6.5x speedup in annotation time while only incurring a 3 point F1 reduction in performance with respect to the domain experts. Our experiments demonstrate the value of modeling OATH-Frames over existing sentiment and toxicity classifiers. Our large-scale analysis with predicted OATH-Frames on 2.4M posts on homelessness reveal key trends in attitudes across states, time periods and vulnerable populations, enabling new insights on the issue. Our work provides a general framework to understand nuanced public attitudes at scale, on issues beyond homelessness.
Learning Optimal and Fair Policies for Online Allocation of Scarce Societal Resources from Data Collected in Deployment
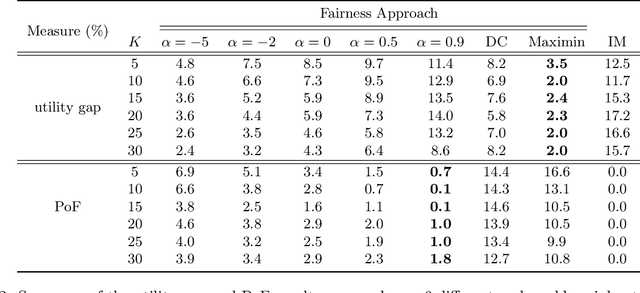
Nov 23, 2023We study the problem of allocating scarce societal resources of different types (e.g., permanent housing, deceased donor kidneys for transplantation, ventilators) to heterogeneous allocatees on a waitlist (e.g., people experiencing homelessness, individuals suffering from end-stage renal disease, Covid-19 patients) based on their observed covariates. We leverage administrative data collected in deployment to design an online policy that maximizes expected outcomes while satisfying budget constraints, in the long run. Our proposed policy waitlists each individual for the resource maximizing the difference between their estimated mean treatment outcome and the estimated resource dual-price or, roughly, the opportunity cost of using the resource. Resources are then allocated as they arrive, in a first-come first-serve fashion. We demonstrate that our data-driven policy almost surely asymptotically achieves the expected outcome of the optimal out-of-sample policy under mild technical assumptions. We extend our framework to incorporate various fairness constraints. We evaluate the performance of our approach on the problem of designing policies for allocating scarce housing resources to people experiencing homelessness in Los Angeles based on data from the homeless management information system. In particular, we show that using our policies improves rates of exit from homelessness by 1.9% and that policies that are fair in either allocation or outcomes by race come at a very low price of fairness.
Fairness in Contextual Resource Allocation Systems: Metrics and Incompatibility Results
Dec 04, 2022We study critical systems that allocate scarce resources to satisfy basic needs, such as homeless services that provide housing. These systems often support communities disproportionately affected by systemic racial, gender, or other injustices, so it is crucial to design these systems with fairness considerations in mind. To address this problem, we propose a framework for evaluating fairness in contextual resource allocation systems that is inspired by fairness metrics in machine learning. This framework can be applied to evaluate the fairness properties of a historical policy, as well as to impose constraints in the design of new (counterfactual) allocation policies. Our work culminates with a set of incompatibility results that investigate the interplay between the different fairness metrics we propose. Notably, we demonstrate that: 1) fairness in allocation and fairness in outcomes are usually incompatible; 2) policies that prioritize based on a vulnerability score will usually result in unequal outcomes across groups, even if the score is perfectly calibrated; 3) policies using contextual information beyond what is needed to characterize baseline risk and treatment effects can be fairer in their outcomes than those using just baseline risk and treatment effects; and 4) policies using group status in addition to baseline risk and treatment effects are as fair as possible given all available information. Our framework can help guide the discussion among stakeholders in deciding which fairness metrics to impose when allocating scarce resources.
Learning Resource Allocation Policies from Observational Data with an Application to Homeless Services Delivery
Jan 25, 2022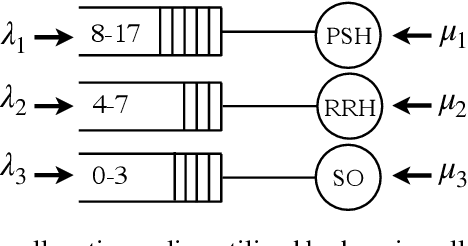
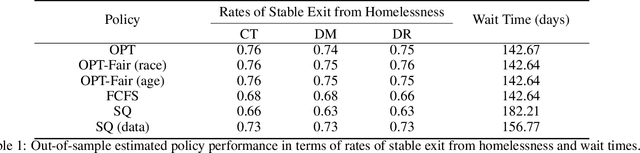
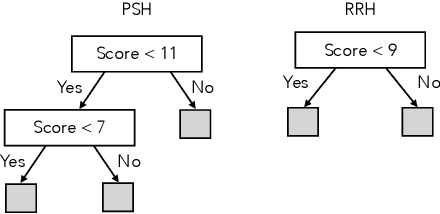
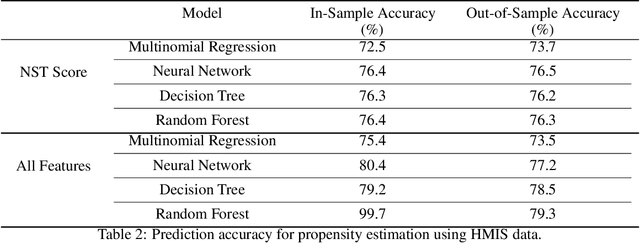
We study the problem of learning, from observational data, fair and interpretable policies that effectively match heterogeneous individuals to scarce resources of different types. We model this problem as a multi-class multi-server queuing system where both individuals and resources arrive stochastically over time. Each individual, upon arrival, is assigned to a queue where they wait to be matched to a resource. The resources are assigned in a first come first served (FCFS) fashion according to an eligibility structure that encodes the resource types that serve each queue. We propose a methodology based on techniques in modern causal inference to construct the individual queues as well as learn the matching outcomes and provide a mixed-integer optimization (MIO) formulation to optimize the eligibility structure. The MIO problem maximizes policy outcome subject to wait time and fairness constraints. It is very flexible, allowing for additional linear domain constraints. We conduct extensive analyses using synthetic and real-world data. In particular, we evaluate our framework using data from the U.S. Homeless Management Information System (HMIS). We obtain wait times as low as an FCFS policy while improving the rate of exit from homelessness for underserved or vulnerable groups (7% higher for the Black individuals and 15% higher for those below 17 years old) and overall.
Fair Influence Maximization: A Welfare Optimization Approach
Jun 14, 2020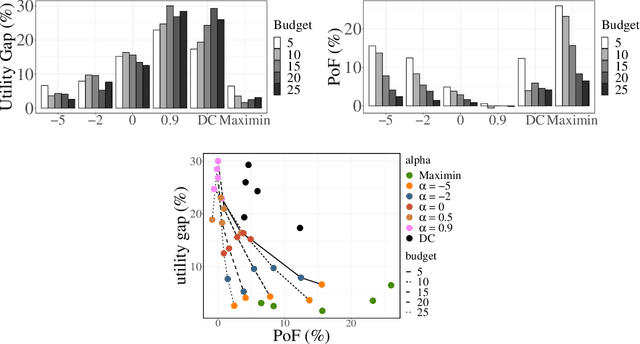
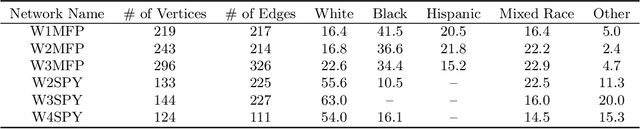

Several social interventions (e.g., suicide and HIV prevention) leverage social network information to maximize outreach. Algorithmic influence maximization techniques have been proposed to aid with the choice of influencers (or peer leaders) in such interventions. Traditional algorithms for influence maximization have not been designed with social interventions in mind. As a result, they may disproportionately exclude minority communities from the benefits of the intervention. This has motivated research on fair influence maximization. Existing techniques require committing to a single domain-specific fairness measure. This makes it hard for a decision maker to meaningfully compare these notions and their resulting trade-offs across different applications. We address these shortcomings by extending the principles of cardinal welfare to the influence maximization setting, which is underlain by complex connections between members of different communities. We generalize the theory regarding these principles and show under what circumstances these principles can be satisfied by a welfare function. We then propose a family of welfare functions that are governed by a single inequity aversion parameter which allows a decision maker to study task-dependent trade-offs between fairness and total influence and effectively trade off quantities like influence gap by varying this parameter. We use these welfare functions as a fairness notion to rule out undesirable allocations. We show that the resulting optimization problem is monotone and submodular and can be solved with optimality guarantees. Finally, we carry out a detailed experimental analysis on synthetic and real social networks and should that high welfare can be achieved without sacrificing the total influence significantly. Interestingly we can show there exists welfare functions that empirically satisfy all of the principles.
Active Preference Elicitation via Adjustable Robust Optimization
Mar 04, 2020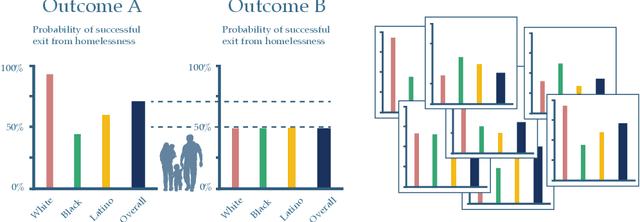


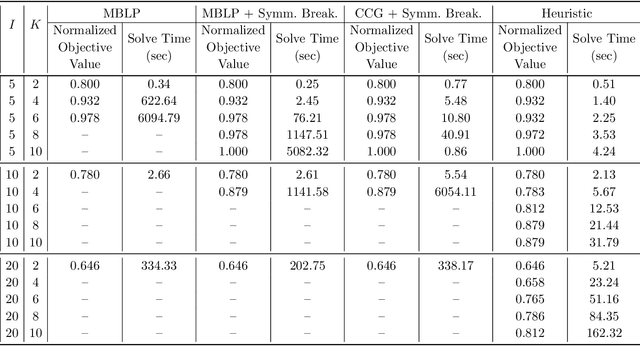
We consider the problem faced by a recommender system which seeks to offer a user with unknown preferences an item. Before making a recommendation, the system has the opportunity to elicit the user's preferences by making queries. Each query corresponds to a pairwise comparison between items. We take the point of view of either a risk averse or regret averse recommender system which only possess set-based information on the user utility function. We investigate: a) an offline elicitation setting, where all queries are made at once, and b) an online elicitation setting, where queries are selected sequentially over time. We propose exact robust optimization formulations of these problems which integrate the elicitation and recommendation phases and study the complexity of these problems. For the offline case, where the problem takes the form of a two-stage robust optimization problem with decision-dependent information discovery, we provide an enumeration-based algorithm and also an equivalent reformulation in the form of a mixed-binary linear program which we solve via column-and-constraint generation. For the online setting, where the problem takes the form of a multi-stage robust optimization problem with decision-dependent information discovery, we propose a conservative solution approach. We evaluate the performance of our methods on both synthetic data and real data from the Homeless Management Information System. We simulate elicitation of the preferences of policy-makers in terms of characteristics of housing allocation policies to better match individuals experiencing homelessness to scarce housing resources. Our framework is shown to outperform the state-of-the-art techniques from the literature.
Pilot Testing an Artificial Intelligence Algorithm That Selects Homeless Youth Peer Leaders Who Promote HIV Testing
Aug 19, 2016Objective. To pilot test an artificial intelligence (AI) algorithm that selects peer change agents (PCA) to disseminate HIV testing messaging in a population of homeless youth. Methods. We recruited and assessed 62 youth at baseline, 1 month (n = 48), and 3 months (n = 38). A Facebook app collected preliminary social network data. Eleven PCAs selected by AI attended a 1-day training and 7 weekly booster sessions. Mixed-effects models with random effects were used to assess change over time. Results. Significant change over time was observed in past 6-month HIV testing (57.9%, 82.4%, 76.3%; p < .05) but not condom use (63.9%, 65.7%, 65.8%). Most youth reported speaking to a PCA about HIV prevention (72.0% at 1 month, 61.5% at 3 months). Conclusions. AI is a promising avenue for implementing PCA models for homeless youth. Increasing rates of regular HIV testing is critical to HIV prevention and linking homeless youth to treatment.
Using Social Networks to Aid Homeless Shelters: Dynamic Influence Maximization under Uncertainty - An Extended Version
Jan 30, 2016


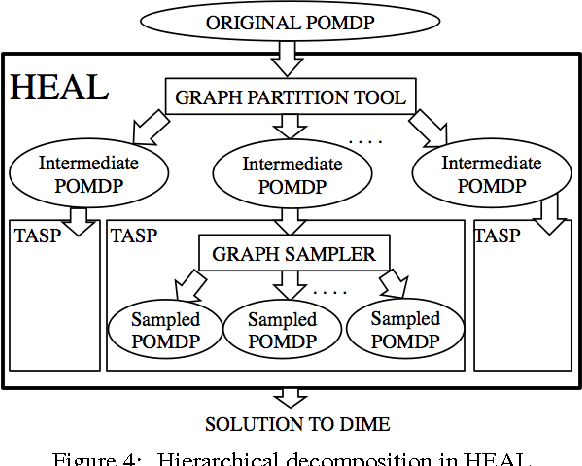
This paper presents HEALER, a software agent that recommends sequential intervention plans for use by homeless shelters, who organize these interventions to raise awareness about HIV among homeless youth. HEALER's sequential plans (built using knowledge of social networks of homeless youth) choose intervention participants strategically to maximize influence spread, while reasoning about uncertainties in the network. While previous work presents influence maximizing techniques to choose intervention participants, they do not address three real-world issues: (i) they completely fail to scale up to real-world sizes; (ii) they do not handle deviations in execution of intervention plans; (iii) constructing real-world social networks is an expensive process. HEALER handles these issues via four major contributions: (i) HEALER casts this influence maximization problem as a POMDP and solves it using a novel planner which scales up to previously unsolvable real-world sizes; (ii) HEALER allows shelter officials to modify its recommendations, and updates its future plans in a deviation-tolerant manner; (iii) HEALER constructs social networks of homeless youth at low cost, using a Facebook application. Finally, (iv) we show hardness results for the problem that HEALER solves. HEALER will be deployed in the real world in early Spring 2016 and is currently undergoing testing at a homeless shelter.