 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating and Implementing Conventional Fairness Metrics With Probabilistic Protected Features
Oct 02, 2023
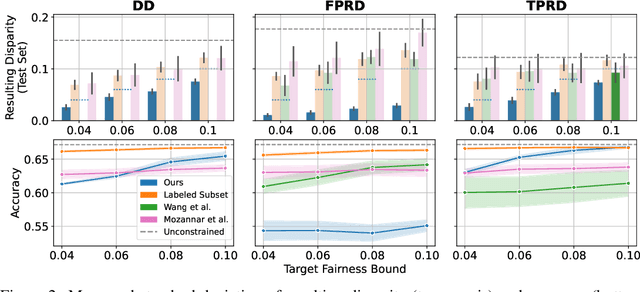
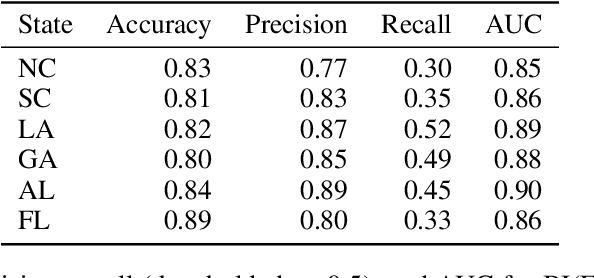
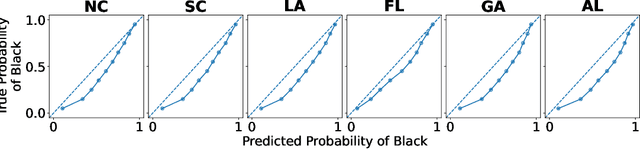
The vast majority of techniques to train fair models require access to the protected attribute (e.g., race, gender), either at train time or in production. However, in many important applications this protected attribute is largely unavailable. In this paper, we develop methods for measuring and reducing fairness violations in a setting with limited access to protected attribute labels. Specifically, we assume access to protected attribute labels on a small subset of the dataset of interest, but only probabilistic estimates of protected attribute labels (e.g., via Bayesian Improved Surname Geocoding) for the rest of the dataset. With this setting in mind, we propose a method to estimate bounds on common fairness metrics for an existing model, as well as a method for training a model to limit fairness violations by solving a constrained non-convex optimization problem. Unlike similar existing approaches, our methods take advantage of contextual information -- specifically, the relationships between a model's predictions and the probabilistic prediction of protected attributes, given the true protected attribute, and vice versa -- to provide tighter bounds on the true disparity. We provide an empirical illustration of our methods using voting data. First, we show our measurement method can bound the true disparity up to 5.5x tighter than previous methods in these applications. Then, we demonstrate that our training technique effectively reduces disparity while incurring lesser fairness-accuracy trade-offs than other fair optimization methods with limited access to protected attributes.
ODTlearn: A Package for Learning Optimal Decision Trees for Prediction and Prescription
Jul 28, 2023

ODTLearn is an open-source Python package that provides methods for learning optimal decision trees for high-stakes predictive and prescriptive tasks based on the mixed-integer optimization (MIO) framework proposed in Aghaei et al. (2019) and several of its extensions. The current version of the package provides implementations for learning optimal classification trees, optimal fair classification trees, optimal classification trees robust to distribution shifts, and optimal prescriptive trees from observational data. We have designed the package to be easy to maintain and extend as new optimal decision tree problem classes, reformulation strategies, and solution algorithms are introduced. To this end, the package follows object-oriented design principles and supports both commercial (Gurobi) and open source (COIN-OR branch and cut) solvers. The package documentation and an extensive user guide can be found at https://d3m-research-group.github.io/odtlearn/. Additionally, users can view the package source code and submit feature requests and bug reports by visiting https://github.com/D3M-Research-Group/odtlearn.
Fairness in Contextual Resource Allocation Systems: Metrics and Incompatibility Results
Dec 04, 2022We study critical systems that allocate scarce resources to satisfy basic needs, such as homeless services that provide housing. These systems often support communities disproportionately affected by systemic racial, gender, or other injustices, so it is crucial to design these systems with fairness considerations in mind. To address this problem, we propose a framework for evaluating fairness in contextual resource allocation systems that is inspired by fairness metrics in machine learning. This framework can be applied to evaluate the fairness properties of a historical policy, as well as to impose constraints in the design of new (counterfactual) allocation policies. Our work culminates with a set of incompatibility results that investigate the interplay between the different fairness metrics we propose. Notably, we demonstrate that: 1) fairness in allocation and fairness in outcomes are usually incompatible; 2) policies that prioritize based on a vulnerability score will usually result in unequal outcomes across groups, even if the score is perfectly calibrated; 3) policies using contextual information beyond what is needed to characterize baseline risk and treatment effects can be fairer in their outcomes than those using just baseline risk and treatment effects; and 4) policies using group status in addition to baseline risk and treatment effects are as fair as possible given all available information. Our framework can help guide the discussion among stakeholders in deciding which fairness metrics to impose when allocating scarce resources.
Learning Optimal Fair Classification Trees
Jan 24, 2022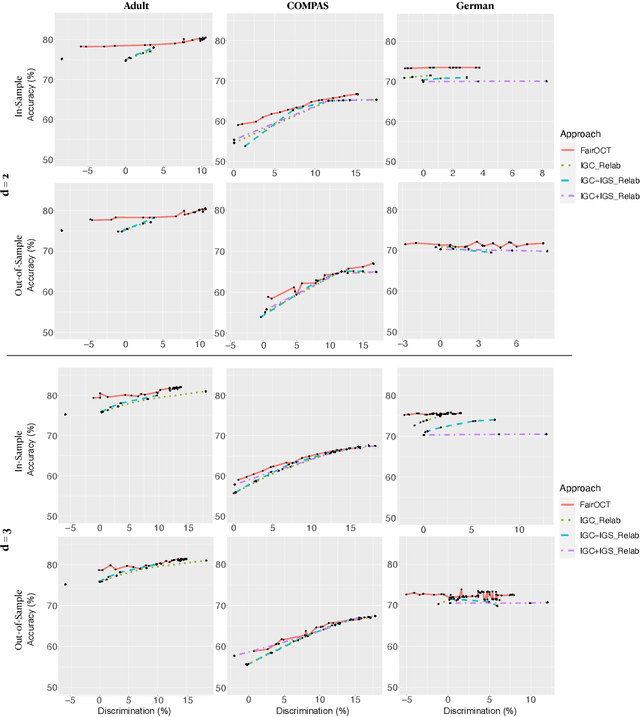
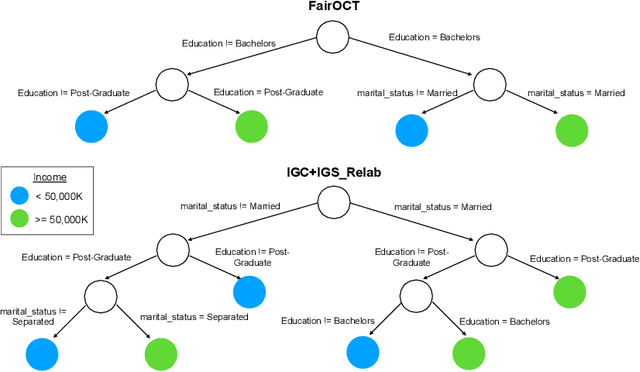
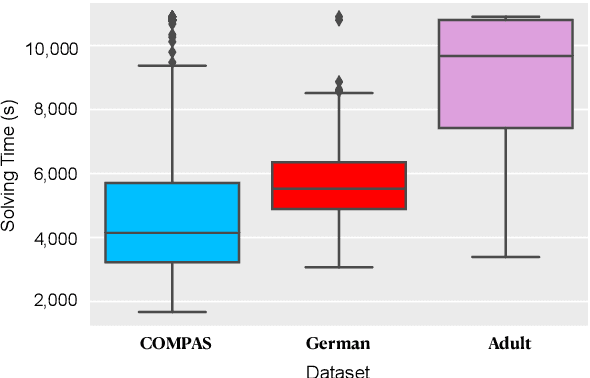
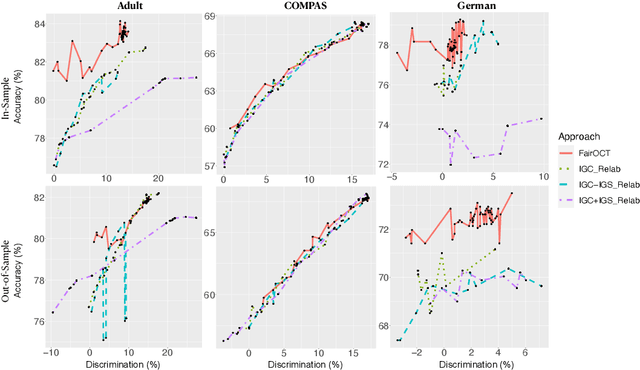
The increasing use of machine learning in high-stakes domains -- where people's livelihoods are impacted -- creates an urgent need for interpretable and fair algorithms. In these settings it is also critical for such algorithms to be accurate. With these needs in mind, we propose a mixed integer optimization (MIO) framework for learning optimal classification trees of fixed depth that can be conveniently augmented with arbitrary domain specific fairness constraints. We benchmark our method against the state-of-the-art approach for building fair trees on popular datasets; given a fixed discrimination threshold, our approach improves out-of-sample (OOS) accuracy by 2.3 percentage points on average and obtains a higher OOS accuracy on 88.9% of the experiments. We also incorporate various algorithmic fairness notions into our method, showcasing its versatile modeling power that allows decision makers to fine-tune the trade-off between accuracy and fairness.
Learning Optimal Prescriptive Trees from Observational Data
Aug 31, 2021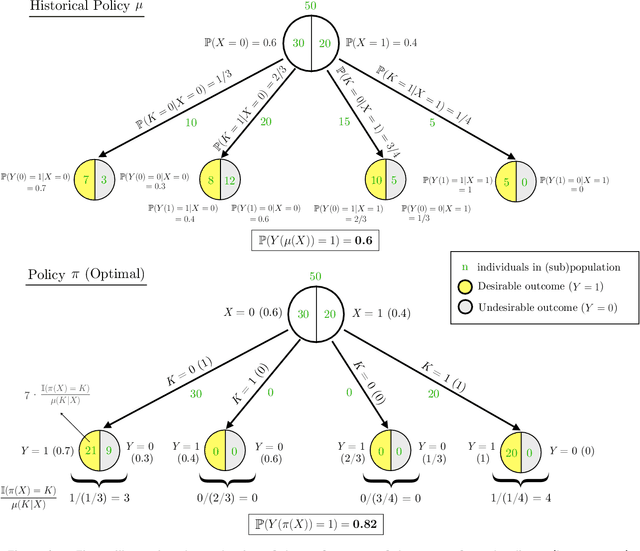
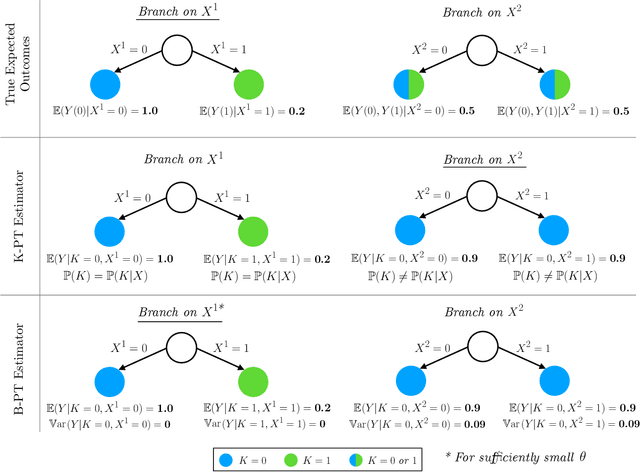


We consider the problem of learning an optimal prescriptive tree (i.e., a personalized treatment assignment policy in the form of a binary tree) of moderate depth, from observational data. This problem arises in numerous socially important domains such as public health and personalized medicine, where interpretable and data-driven interventions are sought based on data gathered in deployment, through passive collection of data, rather than from randomized trials. We propose a method for learning optimal prescriptive trees using mixed-integer optimization (MIO) technology. We show that under mild conditions our method is asymptotically exact in the sense that it converges to an optimal out-of-sample treatment assignment policy as the number of historical data samples tends to infinity. This sets us apart from existing literature on the topic which either requires data to be randomized or imposes stringent assumptions on the trees. Based on extensive computational experiments on both synthetic and real data, we demonstrate that our asymptotic guarantees translate to significant out-of-sample performance improvements even in finite samples.