 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Classification Trees Robust to Distribution Shifts
Oct 26, 2023We consider the problem of learning classification trees that are robust to distribution shifts between training and testing/deployment data. This problem arises frequently in high stakes settings such as public health and social work where data is often collected using self-reported surveys which are highly sensitive to e.g., the framing of the questions, the time when and place where the survey is conducted, and the level of comfort the interviewee has in sharing information with the interviewer. We propose a method for learning optimal robust classification trees based on mixed-integer robust optimization technology. In particular, we demonstrate that the problem of learning an optimal robust tree can be cast as a single-stage mixed-integer robust optimization problem with a highly nonlinear and discontinuous objective. We reformulate this problem equivalently as a two-stage linear robust optimization problem for which we devise a tailored solution procedure based on constraint generation. We evaluate the performance of our approach on numerous publicly available datasets, and compare the performance to a regularized, non-robust optimal tree. We show an increase of up to 12.48% in worst-case accuracy and of up to 4.85% in average-case accuracy across several datasets and distribution shifts from using our robust solution in comparison to the non-robust one.
ODTlearn: A Package for Learning Optimal Decision Trees for Prediction and Prescription
Jul 28, 2023

ODTLearn is an open-source Python package that provides methods for learning optimal decision trees for high-stakes predictive and prescriptive tasks based on the mixed-integer optimization (MIO) framework proposed in Aghaei et al. (2019) and several of its extensions. The current version of the package provides implementations for learning optimal classification trees, optimal fair classification trees, optimal classification trees robust to distribution shifts, and optimal prescriptive trees from observational data. We have designed the package to be easy to maintain and extend as new optimal decision tree problem classes, reformulation strategies, and solution algorithms are introduced. To this end, the package follows object-oriented design principles and supports both commercial (Gurobi) and open source (COIN-OR branch and cut) solvers. The package documentation and an extensive user guide can be found at https://d3m-research-group.github.io/odtlearn/. Additionally, users can view the package source code and submit feature requests and bug reports by visiting https://github.com/D3M-Research-Group/odtlearn.
Fairness in Contextual Resource Allocation Systems: Metrics and Incompatibility Results
Dec 04, 2022We study critical systems that allocate scarce resources to satisfy basic needs, such as homeless services that provide housing. These systems often support communities disproportionately affected by systemic racial, gender, or other injustices, so it is crucial to design these systems with fairness considerations in mind. To address this problem, we propose a framework for evaluating fairness in contextual resource allocation systems that is inspired by fairness metrics in machine learning. This framework can be applied to evaluate the fairness properties of a historical policy, as well as to impose constraints in the design of new (counterfactual) allocation policies. Our work culminates with a set of incompatibility results that investigate the interplay between the different fairness metrics we propose. Notably, we demonstrate that: 1) fairness in allocation and fairness in outcomes are usually incompatible; 2) policies that prioritize based on a vulnerability score will usually result in unequal outcomes across groups, even if the score is perfectly calibrated; 3) policies using contextual information beyond what is needed to characterize baseline risk and treatment effects can be fairer in their outcomes than those using just baseline risk and treatment effects; and 4) policies using group status in addition to baseline risk and treatment effects are as fair as possible given all available information. Our framework can help guide the discussion among stakeholders in deciding which fairness metrics to impose when allocating scarce resources.
Learning Optimal Fair Classification Trees
Jan 24, 2022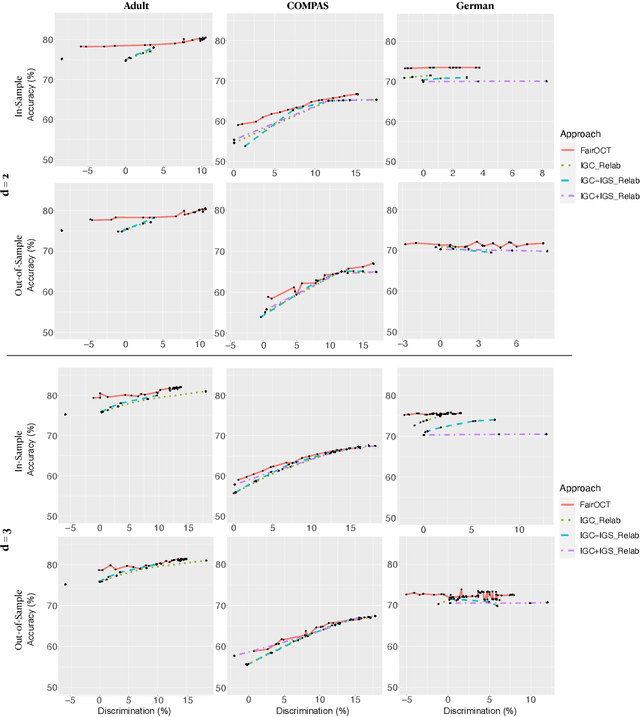
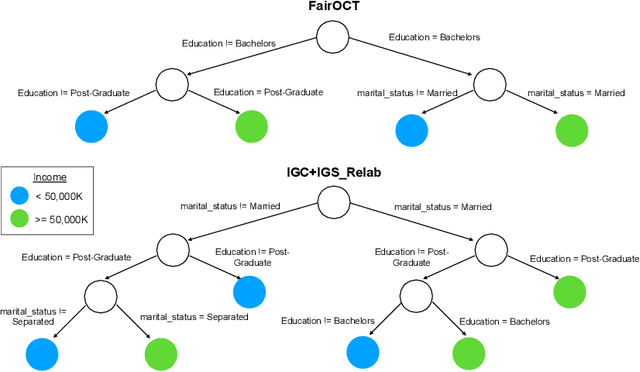
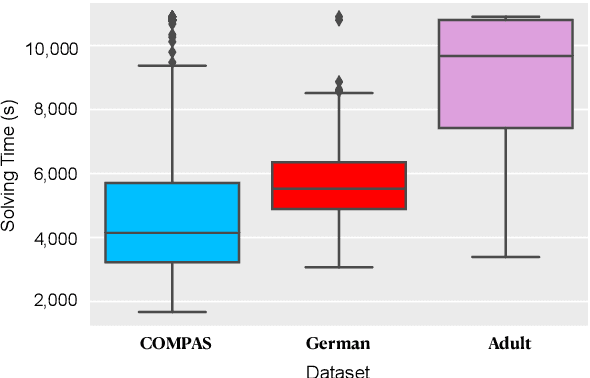
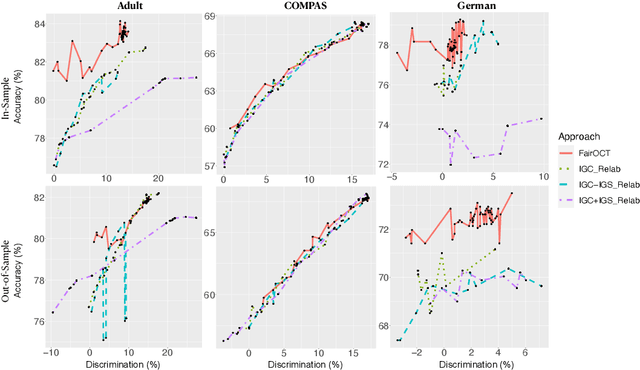
The increasing use of machine learning in high-stakes domains -- where people's livelihoods are impacted -- creates an urgent need for interpretable and fair algorithms. In these settings it is also critical for such algorithms to be accurate. With these needs in mind, we propose a mixed integer optimization (MIO) framework for learning optimal classification trees of fixed depth that can be conveniently augmented with arbitrary domain specific fairness constraints. We benchmark our method against the state-of-the-art approach for building fair trees on popular datasets; given a fixed discrimination threshold, our approach improves out-of-sample (OOS) accuracy by 2.3 percentage points on average and obtains a higher OOS accuracy on 88.9% of the experiments. We also incorporate various algorithmic fairness notions into our method, showcasing its versatile modeling power that allows decision makers to fine-tune the trade-off between accuracy and fairness.
Learning Optimal Prescriptive Trees from Observational Data
Aug 31, 2021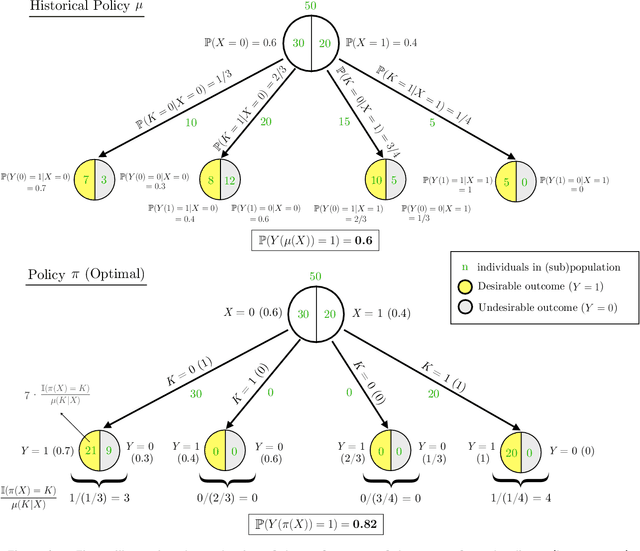


We consider the problem of learning an optimal prescriptive tree (i.e., a personalized treatment assignment policy in the form of a binary tree) of moderate depth, from observational data. This problem arises in numerous socially important domains such as public health and personalized medicine, where interpretable and data-driven interventions are sought based on data gathered in deployment, through passive collection of data, rather than from randomized trials. We propose a method for learning optimal prescriptive trees using mixed-integer optimization (MIO) technology. We show that under mild conditions our method is asymptotically exact in the sense that it converges to an optimal out-of-sample treatment assignment policy as the number of historical data samples tends to infinity. This sets us apart from existing literature on the topic which either requires data to be randomized or imposes stringent assumptions on the trees. Based on extensive computational experiments on both synthetic and real data, we demonstrate that our asymptotic guarantees translate to significant out-of-sample performance improvements even in finite samples.
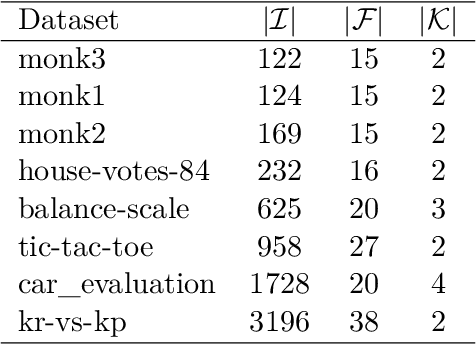
Strong Optimal Classification Trees
Mar 29, 2021


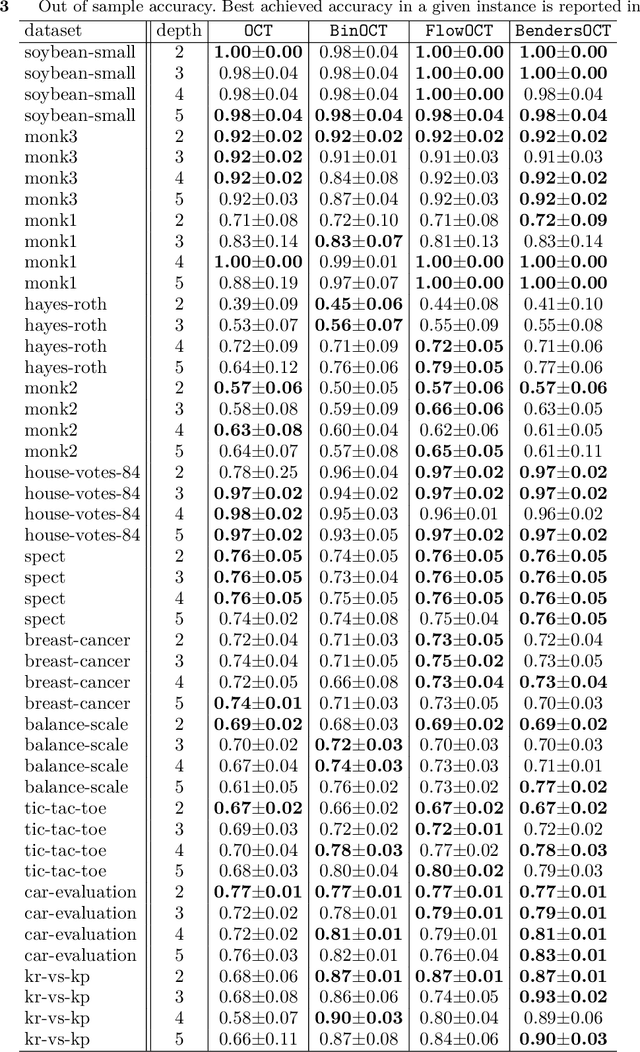
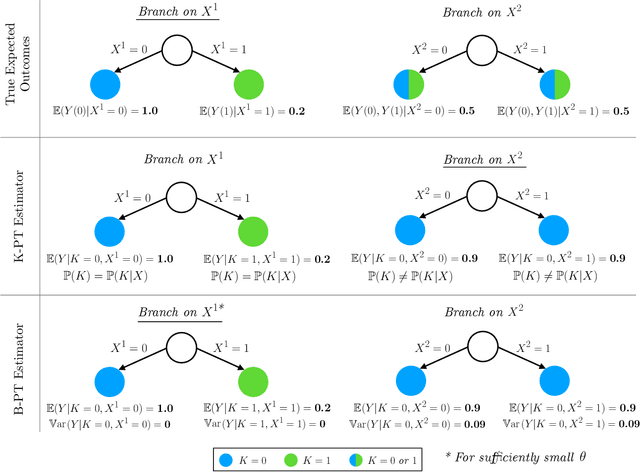
Decision trees are among the most popular machine learning models and are used routinely in applications ranging from revenue management and medicine to bioinformatics. In this paper, we consider the problem of learning optimal binary classification trees. Literature on the topic has burgeoned in recent years, motivated both by the empirical suboptimality of heuristic approaches and the tremendous improvements in mixed-integer optimization (MIO) technology. Yet, existing MIO-based approaches from the literature do not leverage the power of MIO to its full extent: they rely on weak formulations, resulting in slow convergence and large optimality gaps. To fill this gap in the literature, we propose an intuitive flow-based MIO formulation for learning optimal binary classification trees. Our formulation can accommodate side constraints to enable the design of interpretable and fair decision trees. Moreover, we show that our formulation has a stronger linear optimization relaxation than existing methods. We exploit the decomposable structure of our formulation and max-flow/min-cut duality to derive a Benders' decomposition method to speed-up computation. We propose a tailored procedure for solving each decomposed subproblem that provably generates facets of the feasible set of the MIO as constraints to add to the main problem. We conduct extensive computational experiments on standard benchmark datasets on which we show that our proposed approaches are 31 times faster than state-of-the art MIO-based techniques and improve out of sample performance by up to 8%.
Learning Optimal Classification Trees: Strong Max-Flow Formulations
Feb 21, 2020
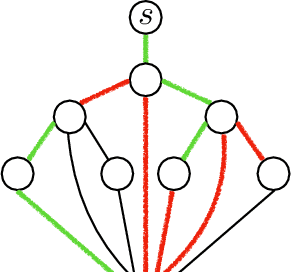

We consider the problem of learning optimal binary classification trees. Literature on the topic has burgeoned in recent years, motivated both by the empirical suboptimality of heuristic approaches and the tremendous improvements in mixed-integer programming (MIP) technology. Yet, existing approaches from the literature do not leverage the power of MIP to its full extent. Indeed, they rely on weak formulations, resulting in slow convergence and large optimality gaps. To fill this gap in the literature, we propose a flow-based MIP formulation for optimal binary classification trees that has a stronger linear programming relaxation. Our formulation presents an attractive decomposable structure. We exploit this structure and max-flow/min-cut duality to derive a Benders' decomposition method, which scales to larger instances. We conduct extensive computational experiments on standard benchmark datasets on which we show that our proposed approaches are 50 times faster than state-of-the art MIP-based techniques and improve out of sample performance up to 13.8%.
Learning Optimal and Fair Decision Trees for Non-Discriminative Decision-Making
Mar 25, 2019


In recent years, automated data-driven decision-making systems have enjoyed a tremendous success in a variety of fields (e.g., to make product recommendations, or to guide the production of entertainment). More recently, these algorithms are increasingly being used to assist socially sensitive decision-making (e.g., to decide who to admit into a degree program or to prioritize individuals for public housing). Yet, these automated tools may result in discriminative decision-making in the sense that they may treat individuals unfairly or unequally based on membership to a category or a minority, resulting in disparate treatment or disparate impact and violating both moral and ethical standards. This may happen when the training dataset is itself biased (e.g., if individuals belonging to a particular group have historically been discriminated upon). However, it may also happen when the training dataset is unbiased, if the errors made by the system affect individuals belonging to a category or minority differently (e.g., if misclassification rates for Blacks are higher than for Whites). In this paper, we unify the definitions of unfairness across classification and regression. We propose a versatile mixed-integer optimization framework for learning optimal and fair decision trees and variants thereof to prevent disparate treatment and/or disparate impact as appropriate. This translates to a flexible schema for designing fair and interpretable policies suitable for socially sensitive decision-making. We conduct extensive computational studies that show that our framework improves the state-of-the-art in the field (which typically relies on heuristics) to yield non-discriminative decisions at lower cost to overall accuracy.