 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStanding on FURM ground -- A framework for evaluating Fair, Useful, and Reliable AI Models in healthcare systems
Mar 14, 2024



The impact of using artificial intelligence (AI) to guide patient care or operational processes is an interplay of the AI model's output, the decision-making protocol based on that output, and the capacity of the stakeholders involved to take the necessary subsequent action. Estimating the effects of this interplay before deployment, and studying it in real time afterwards, are essential to bridge the chasm between AI model development and achievable benefit. To accomplish this, the Data Science team at Stanford Health Care has developed a Testing and Evaluation (T&E) mechanism to identify fair, useful and reliable AI models (FURM) by conducting an ethical review to identify potential value mismatches, simulations to estimate usefulness, financial projections to assess sustainability, as well as analyses to determine IT feasibility, design a deployment strategy, and recommend a prospective monitoring and evaluation plan. We report on FURM assessments done to evaluate six AI guided solutions for potential adoption, spanning clinical and operational settings, each with the potential to impact from several dozen to tens of thousands of patients each year. We describe the assessment process, summarize the six assessments, and share our framework to enable others to conduct similar assessments. Of the six solutions we assessed, two have moved into a planning and implementation phase. Our novel contributions - usefulness estimates by simulation, financial projections to quantify sustainability, and a process to do ethical assessments - as well as their underlying methods and open source tools, are available for other healthcare systems to conduct actionable evaluations of candidate AI solutions.
When Do Neural Nets Outperform Boosted Trees on Tabular Data?
May 04, 2023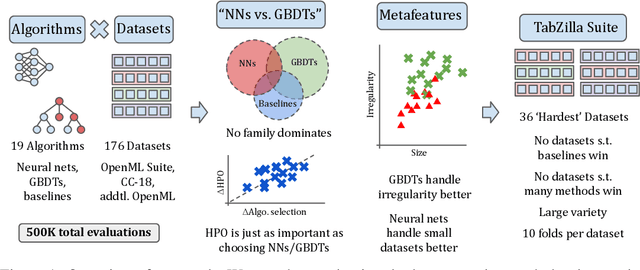



Tabular data is one of the most commonly used types of data in machine learning. Despite recent advances in neural nets (NNs) for tabular data, there is still an active discussion on whether or not NNs generally outperform gradient-boosted decision trees (GBDTs) on tabular data, with several recent works arguing either that GBDTs consistently outperform NNs on tabular data, or vice versa. In this work, we take a step back and ask, 'does it matter?' We conduct the largest tabular data analysis to date, by comparing 19 algorithms across 176 datasets, and we find that the 'NN vs. GBDT' debate is overemphasized: for a surprisingly high number of datasets, either the performance difference between GBDTs and NNs is negligible, or light hyperparameter tuning on a GBDT is more important than selecting the best algorithm. Next, we analyze 965 metafeatures to determine what properties of a dataset make NNs or GBDTs better-suited to perform well. For example, we find that GBDTs are much better than NNs at handling skewed feature distributions, heavy-tailed feature distributions, and other forms of dataset irregularities. Our insights act as a guide for practitioners to decide whether or not they need to run a neural net to reach top performance on their dataset. Our codebase and all raw results are available at https://github.com/naszilla/tabzilla.
On the Generalizability and Predictability of Recommender Systems
Jun 23, 2022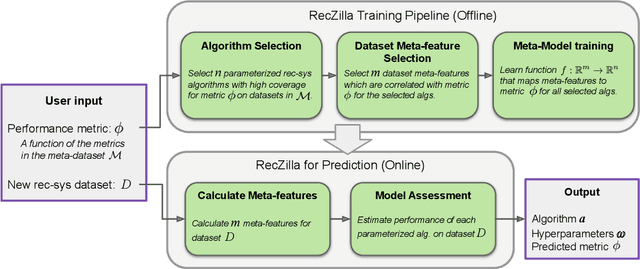
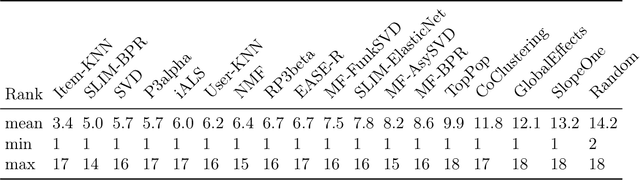
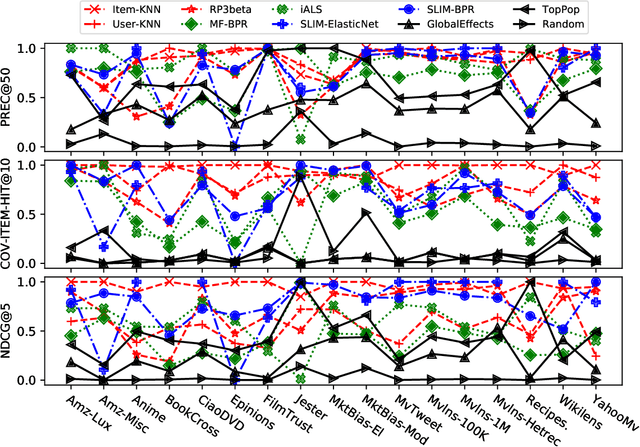

While other areas of machine learning have seen more and more automation, designing a high-performing recommender system still requires a high level of human effort. Furthermore, recent work has shown that modern recommender system algorithms do not always improve over well-tuned baselines. A natural follow-up question is, "how do we choose the right algorithm for a new dataset and performance metric?" In this work, we start by giving the first large-scale study of recommender system approaches by comparing 18 algorithms and 100 sets of hyperparameters across 85 datasets and 315 metrics. We find that the best algorithms and hyperparameters are highly dependent on the dataset and performance metric, however, there are also strong correlations between the performance of each algorithm and various meta-features of the datasets. Motivated by these findings, we create RecZilla, a meta-learning approach to recommender systems that uses a model to predict the best algorithm and hyperparameters for new, unseen datasets. By using far more meta-training data than prior work, RecZilla is able to substantially reduce the level of human involvement when faced with a new recommender system application. We not only release our code and pretrained RecZilla models, but also all of our raw experimental results, so that practitioners can train a RecZilla model for their desired performance metric: https://github.com/naszilla/reczilla.
Active Preference Elicitation via Adjustable Robust Optimization
Mar 04, 2020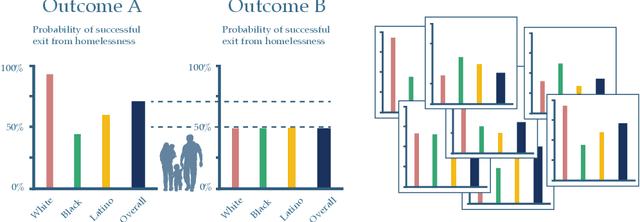


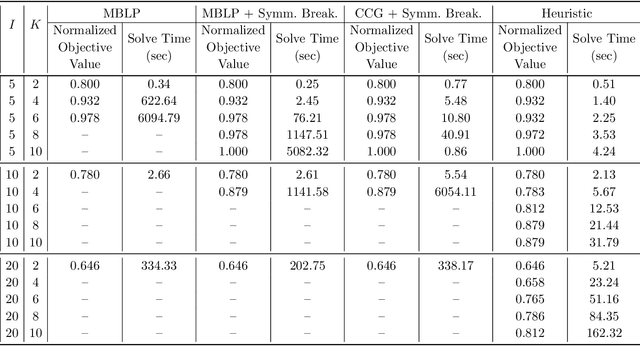
We consider the problem faced by a recommender system which seeks to offer a user with unknown preferences an item. Before making a recommendation, the system has the opportunity to elicit the user's preferences by making queries. Each query corresponds to a pairwise comparison between items. We take the point of view of either a risk averse or regret averse recommender system which only possess set-based information on the user utility function. We investigate: a) an offline elicitation setting, where all queries are made at once, and b) an online elicitation setting, where queries are selected sequentially over time. We propose exact robust optimization formulations of these problems which integrate the elicitation and recommendation phases and study the complexity of these problems. For the offline case, where the problem takes the form of a two-stage robust optimization problem with decision-dependent information discovery, we provide an enumeration-based algorithm and also an equivalent reformulation in the form of a mixed-binary linear program which we solve via column-and-constraint generation. For the online setting, where the problem takes the form of a multi-stage robust optimization problem with decision-dependent information discovery, we propose a conservative solution approach. We evaluate the performance of our methods on both synthetic data and real data from the Homeless Management Information System. We simulate elicitation of the preferences of policy-makers in terms of characteristics of housing allocation policies to better match individuals experiencing homelessness to scarce housing resources. Our framework is shown to outperform the state-of-the-art techniques from the literature.