 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVista4D: Video Reshooting with 4D Point Clouds
Apr 23, 2026We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and failing to maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition. See our project page for results, code, and models: https://eyeline-labs.github.io/Vista4D
LiveMathematicianBench: A Live Benchmark for Mathematician-Level Reasoning with Proof Sketches
Apr 02, 2026Mathematical reasoning is a hallmark of human intelligence, and whether large language models (LLMs) can meaningfully perform it remains a central question in artificial intelligence and cognitive science. As LLMs are increasingly integrated into scientific workflows, rigorous evaluation of their mathematical capabilities becomes a practical necessity. Existing benchmarks are limited by synthetic settings and data contamination. We present LiveMathematicianBench, a dynamic multiple-choice benchmark for research-level mathematical reasoning built from recent arXiv papers published after model training cutoffs. By grounding evaluation in newly published theorems, it provides a realistic testbed beyond memorized patterns. The benchmark introduces a thirteen-category logical taxonomy of theorem types (e.g., implication, equivalence, existence, uniqueness), enabling fine-grained evaluation across reasoning forms. It employs a proof-sketch-guided distractor pipeline that uses high-level proof strategies to construct plausible but invalid answer choices reflecting misleading proof directions, increasing sensitivity to genuine understanding over surface-level matching. We also introduce a substitution-resistant mechanism to distinguish answer recognition from substantive reasoning. Evaluation shows the benchmark is far from saturated: Gemini-3.1-pro-preview, the best model, achieves only 43.5%. Under substitution-resistant evaluation, accuracy drops sharply: GPT-5.4 scores highest at 30.6%, while Gemini-3.1-pro-preview falls to 17.6%, below the 20% random baseline. A dual-mode protocol reveals that proof-sketch access yields consistent accuracy gains, suggesting models can leverage high-level proof strategies for reasoning. Overall, LiveMathematicianBench offers a scalable, contamination-resistant testbed for studying research-level mathematical reasoning in LLMs.
Privacy-Preserving Mechanisms Enable Cheap Verifiable Inference of LLMs
Feb 19, 2026As large language models (LLMs) continue to grow in size, fewer users are able to host and run models locally. This has led to increased use of third-party hosting services. However, in this setting, there is a lack of guarantees on the computation performed by the inference provider. For example, a dishonest provider may replace an expensive large model with a cheaper-to-run weaker model and return the results from the weaker model to the user. Existing tools to verify inference typically rely on methods from cryptography such as zero-knowledge proofs (ZKPs), but these add significant computational overhead, and remain infeasible for use for large models. In this work, we develop a new insight -- that given a method for performing private LLM inference, one can obtain forms of verified inference at marginal extra cost. Specifically, we propose two new protocols which leverage privacy-preserving LLM inference in order to provide guarantees over the inference that was carried out. Our approaches are cheap, requiring the addition of a few extra tokens of computation, and have little to no downstream impact. As the fastest privacy-preserving inference methods are typically faster than ZK methods, the proposed protocols also improve verification runtime. Our work provides novel insights into the connections between privacy and verifiability in LLM inference.
Dynamic Delayed Tree Expansion For Improved Multi-Path Speculative Decoding
Feb 19, 2026Multi-path speculative decoding accelerates lossless sampling from a target model by using a cheaper draft model to generate a draft tree of tokens, and then applies a verification algorithm that accepts a subset of these. While prior work has proposed various verification algorithms for i.i.d rollouts, their relative performance under matched settings remains unclear. In this work, we firstly present a systematic evaluation of verification strategies across model families, tasks, and sampling regimes, and find that Traversal Verification dominates consistently, with OT-based methods lagging far behind. Our analysis uncovers that this occurs because OT-based methods achieve high multi-token acceptance near the root of the draft tree, while multi-token gains are most impactful deeper in the draft tree, where draft and target distributions diverge. Based on this insight, we propose delayed tree expansion, which drafts a partial single path, delaying the i.i.d. branching point. We show that delayed tree expansion preserves the target distribution and improves on root-node i.i.d rollouts. Further, we develop a dynamic neural selector that estimates the expected block efficiency of optimal-transport-based verification methods from draft and target features, enabling context-dependent expansion decisions. Our neural selector allows OT-based methods like SpecInfer to outperform Traversal Verification for the first time, achieving 5% higher average throughput across a wide range of models, datasets, and sampling settings.
Multi-Token Prediction via Self-Distillation
Feb 05, 2026Existing techniques for accelerating language model inference, such as speculative decoding, require training auxiliary speculator models and building and deploying complex inference pipelines. We consider a new approach for converting a pretrained autoregressive language model from a slow single next token prediction model into a fast standalone multi-token prediction model using a simple online distillation objective. The final model retains the exact same implementation as the pretrained initial checkpoint and is deployable without the addition of any auxiliary verifier or other specialized inference code. On GSM8K, our method produces models that can decode more than $3\times$ faster on average at $<5\%$ drop in accuracy relative to single token decoding performance.
Closing the Train-Test Gap in World Models for Gradient-Based Planning
Dec 10, 2025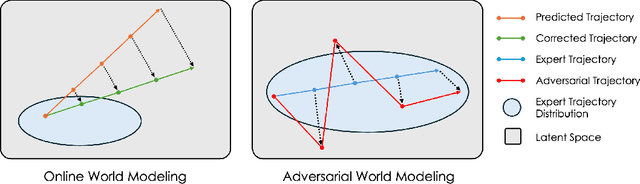
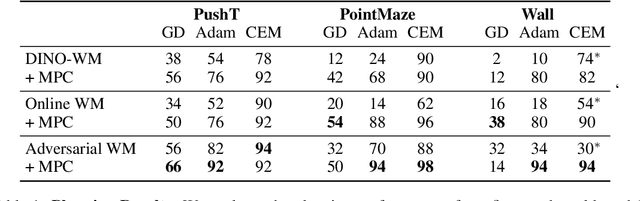
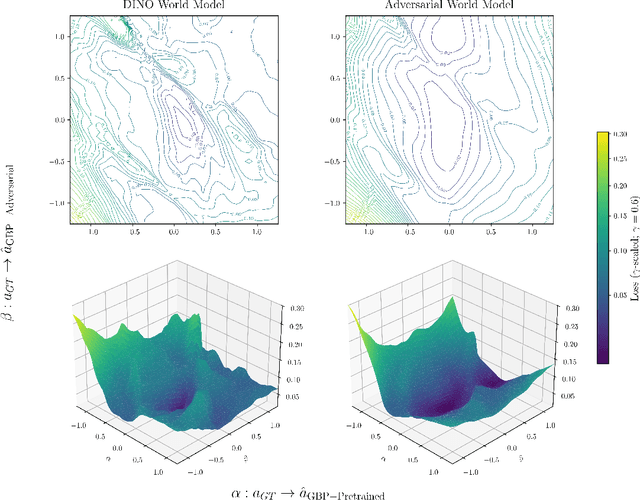
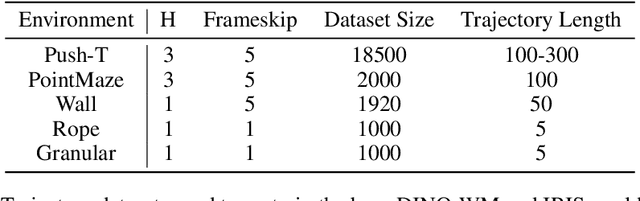
World models paired with model predictive control (MPC) can be trained offline on large-scale datasets of expert trajectories and enable generalization to a wide range of planning tasks at inference time. Compared to traditional MPC procedures, which rely on slow search algorithms or on iteratively solving optimization problems exactly, gradient-based planning offers a computationally efficient alternative. However, the performance of gradient-based planning has thus far lagged behind that of other approaches. In this paper, we propose improved methods for training world models that enable efficient gradient-based planning. We begin with the observation that although a world model is trained on a next-state prediction objective, it is used at test-time to instead estimate a sequence of actions. The goal of our work is to close this train-test gap. To that end, we propose train-time data synthesis techniques that enable significantly improved gradient-based planning with existing world models. At test time, our approach outperforms or matches the classical gradient-free cross-entropy method (CEM) across a variety of object manipulation and navigation tasks in 10% of the time budget.
Incoherent Beliefs & Inconsistent Actions in Large Language Models
Nov 17, 2025Real-world tasks and environments exhibit differences from the static datasets that large language models (LLMs) are typically evaluated on. Such tasks can involve sequential interaction, requiring coherent updating of beliefs in light of new evidence, and making appropriate decisions based on those beliefs. Predicting how LLMs will perform in such dynamic environments is important, but can be tricky to determine from measurements in static settings. In this work, we examine two critical components of LLM performance: the ability of LLMs to coherently update their beliefs, and the extent to which the actions they take are consistent with those beliefs. First, we find that LLMs are largely inconsistent in how they update their beliefs; models can exhibit up to a 30% average difference between the directly elicited posterior, and the correct update of their prior. Second, we find that LLMs also often take actions which are inconsistent with the beliefs they hold. On a betting market, for example, LLMs often do not even bet in the same direction as their internally held beliefs over the underlying outcomes. We also find they have moderate self-inconsistency in how they respond to challenges by users to given answers. Finally, we show that the above properties hold even for strong models that obtain high accuracy or that are well-calibrated on the tasks at hand. Our results highlight the difficulties of predicting LLM behavior in complex real-world settings.
Preserving Cross-Modal Consistency for CLIP-based Class-Incremental Learning
Nov 14, 2025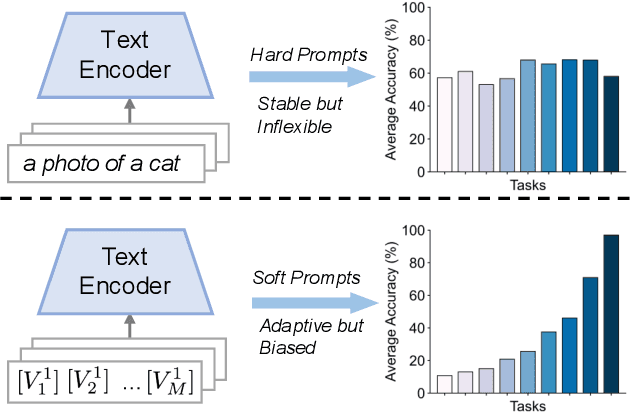
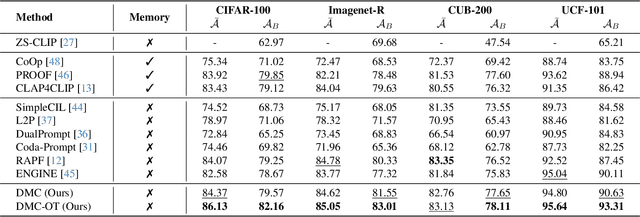
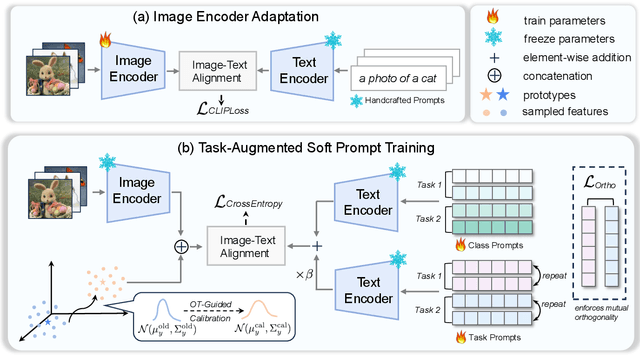
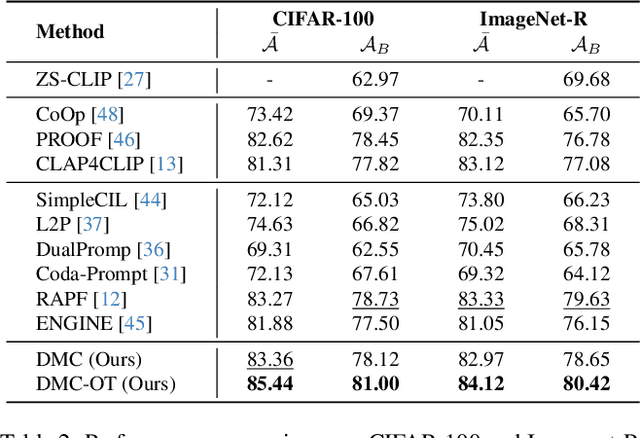
Class-incremental learning (CIL) enables models to continuously learn new categories from sequential tasks without forgetting previously acquired knowledge. While recent advances in vision-language models such as CLIP have demonstrated strong generalization across domains, extending them to continual settings remains challenging. In particular, learning task-specific soft prompts for newly introduced classes often leads to severe classifier bias, as the text prototypes overfit to recent categories when prior data are unavailable. In this paper, we propose DMC, a simple yet effective two-stage framework for CLIP-based CIL that decouples the adaptation of the vision encoder and the optimization of textual soft prompts. Each stage is trained with the other frozen, allowing one modality to act as a stable semantic anchor for the other to preserve cross-modal alignment. Furthermore, current CLIP-based CIL approaches typically store class-wise Gaussian statistics for generative replay, yet they overlook the distributional drift that arises when the vision encoder is updated over time. To address this issue, we introduce DMC-OT, an enhanced version of DMC that incorporates an optimal-transport guided calibration strategy to align memory statistics across evolving encoders, along with a task-specific prompting design that enhances inter-task separability. Extensive experiments on CIFAR-100, Imagenet-R, CUB-200, and UCF-101 demonstrate that both DMC and DMC-OT achieve state-of-the-art performance, with DMC-OT further improving accuracy by an average of 1.80%.
Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence
Nov 10, 2025Recent advances in depth-recurrent language models show that recurrence can decouple train-time compute and parameter count from test-time compute. In this work, we study how to convert existing pretrained non-recurrent language models into depth-recurrent models. We find that using a curriculum of recurrences to increase the effective depth of the model over the course of training preserves performance while reducing total computational cost. In our experiments, on mathematics, we observe that converting pretrained models to recurrent ones results in better performance at a given compute budget than simply post-training the original non-recurrent language model.
Far from the Shallow: Brain-Predictive Reasoning Embedding through Residual Disentanglement
Oct 26, 2025Understanding how the human brain progresses from processing simple linguistic inputs to performing high-level reasoning is a fundamental challenge in neuroscience. While modern large language models (LLMs) are increasingly used to model neural responses to language, their internal representations are highly "entangled," mixing information about lexicon, syntax, meaning, and reasoning. This entanglement biases conventional brain encoding analyses toward linguistically shallow features (e.g., lexicon and syntax), making it difficult to isolate the neural substrates of cognitively deeper processes. Here, we introduce a residual disentanglement method that computationally isolates these components. By first probing an LM to identify feature-specific layers, our method iteratively regresses out lower-level representations to produce four nearly orthogonal embeddings for lexicon, syntax, meaning, and, critically, reasoning. We used these disentangled embeddings to model intracranial (ECoG) brain recordings from neurosurgical patients listening to natural speech. We show that: 1) This isolated reasoning embedding exhibits unique predictive power, accounting for variance in neural activity not explained by other linguistic features and even extending to the recruitment of visual regions beyond classical language areas. 2) The neural signature for reasoning is temporally distinct, peaking later (~350-400ms) than signals related to lexicon, syntax, and meaning, consistent with its position atop a processing hierarchy. 3) Standard, non-disentangled LLM embeddings can be misleading, as their predictive success is primarily attributable to linguistically shallow features, masking the more subtle contributions of deeper cognitive processing.