 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Concrete Challenges and Two Hopes for the Safety of Unsupervised Elicitation
Feb 23, 2026To steer language models towards truthful outputs on tasks which are beyond human capability, previous work has suggested training models on easy tasks to steer them on harder ones (easy-to-hard generalization), or using unsupervised training algorithms to steer models with no external labels at all (unsupervised elicitation). Although techniques from both paradigms have been shown to improve model accuracy on a wide variety of tasks, we argue that the datasets used for these evaluations could cause overoptimistic evaluation results. Unlike many real-world datasets, they often (1) have no features with more salience than truthfulness, (2) have balanced training sets, and (3) contain only data points to which the model can give a well-defined answer. We construct datasets that lack each of these properties to stress-test a range of standard unsupervised elicitation and easy-to-hard generalization techniques. We find that no technique reliably performs well on any of these challenges. We also study ensembling and combining easy-to-hard and unsupervised techniques, and find they only partially mitigate performance degradation due to these challenges. We believe that overcoming these challenges should be a priority for future work on unsupervised elicitation.
MAEB: Massive Audio Embedding Benchmark
Feb 17, 2026We introduce the Massive Audio Embedding Benchmark (MAEB), a large-scale benchmark covering 30 tasks across speech, music, environmental sounds, and cross-modal audio-text reasoning in 100+ languages. We evaluate 50+ models and find that no single model dominates across all tasks: contrastive audio-text models excel at environmental sound classification (e.g., ESC50) but score near random on multilingual speech tasks (e.g., SIB-FLEURS), while speech-pretrained models show the opposite pattern. Clustering remains challenging for all models, with even the best-performing model achieving only modest results. We observe that models excelling on acoustic understanding often perform poorly on linguistic tasks, and vice versa. We also show that the performance of audio encoders on MAEB correlates highly with their performance when used in audio large language models. MAEB is derived from MAEB+, a collection of 98 tasks. MAEB is designed to maintain task diversity while reducing evaluation cost, and it integrates into the MTEB ecosystem for unified evaluation across text, image, and audio modalities. We release MAEB and all 98 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
LLM Optimization Unlocks Real-Time Pairwise Reranking
Nov 10, 2025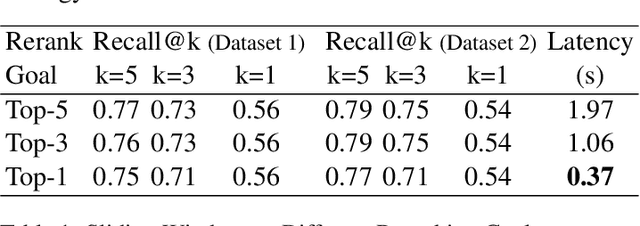



Efficiently reranking documents retrieved from information retrieval (IR) pipelines to enhance overall quality of Retrieval-Augmented Generation (RAG) system remains an important yet challenging problem. Recent studies have highlighted the importance of Large Language Models (LLMs) in reranking tasks. In particular, Pairwise Reranking Prompting (PRP) has emerged as a promising plug-and-play approach due to its usability and effectiveness. However, the inherent complexity of the algorithm, coupled with the high computational demands and latency incurred due to LLMs, raises concerns about its feasibility in real-time applications. To address these challenges, this paper presents a focused study on pairwise reranking, demonstrating that carefully applied optimization methods can significantly mitigate these issues. By implementing these methods, we achieve a remarkable latency reduction of up to 166 times, from 61.36 seconds to 0.37 seconds per query, with an insignificant drop in performance measured by Recall@k. Our study highlights the importance of design choices that were previously overlooked, such as using smaller models, limiting the reranked set, using lower precision, reducing positional bias with one-directional order inference, and restricting output tokens. These optimizations make LLM-based reranking substantially more efficient and feasible for latency-sensitive, real-world deployments.
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
Dec 09, 2024



A key component of building safe and reliable language models is enabling the models to appropriately refuse to follow certain instructions or answer certain questions. We may want models to output refusal messages for various categories of user queries, for example, ill-posed questions, instructions for committing illegal acts, or queries which require information past the model's knowledge horizon. Engineering models that refuse to answer such questions is complicated by the fact that an individual may want their model to exhibit varying levels of sensitivity for refusing queries of various categories, and different users may want different refusal rates. The current default approach involves training multiple models with varying proportions of refusal messages from each category to achieve the desired refusal rates, which is computationally expensive and may require training a new model to accommodate each user's desired preference over refusal rates. To address these challenges, we propose refusal tokens, one such token for each refusal category or a single refusal token, which are prepended to the model's responses during training. We then show how to increase or decrease the probability of generating the refusal token for each category during inference to steer the model's refusal behavior. Refusal tokens enable controlling a single model's refusal rates without the need of any further fine-tuning, but only by selectively intervening during generation.
Adma: A Flexible Loss Function for Neural Networks
Jul 23, 2020


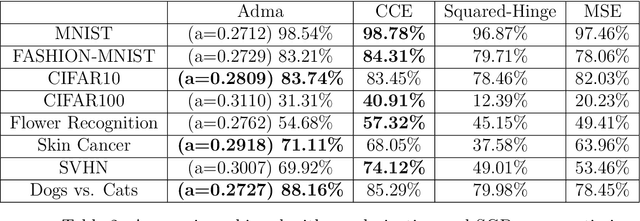
Highly increased interest in Artificial Neural Networks (ANNs) have resulted in impressively wide-ranging improvements in its structure. In this work, we come up with the idea that instead of static plugins that the currently available loss functions are, they should by default be flexible in nature. A flexible loss function can be a more insightful navigator for neural networks leading to higher convergence rates and therefore reaching the optimum accuracy more quickly. The insights to help decide the degree of flexibility can be derived from the complexity of ANNs, the data distribution, selection of hyper-parameters and so on. In the wake of this, we introduce a novel flexible loss function for neural networks. The function is shown to characterize a range of fundamentally unique properties from which, much of the properties of other loss functions are only a subset and varying the flexibility parameter in the function allows it to emulate the loss curves and the learning behavior of prevalent static loss functions. The extensive experimentation performed with the loss function demonstrates that it is able to give state-of-the-art performance on selected data sets. Thus, in all the idea of flexibility itself and the proposed function built upon it carry the potential to open to a new interesting chapter in deep learning research.