 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdma: A Flexible Loss Function for Neural Networks
Paper and Code
Jul 23, 2020


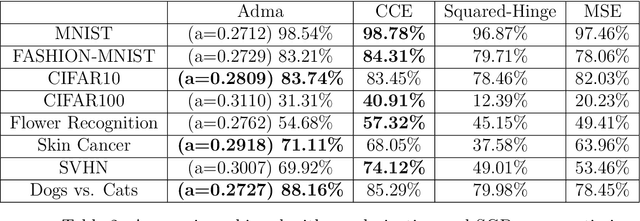
Highly increased interest in Artificial Neural Networks (ANNs) have resulted in impressively wide-ranging improvements in its structure. In this work, we come up with the idea that instead of static plugins that the currently available loss functions are, they should by default be flexible in nature. A flexible loss function can be a more insightful navigator for neural networks leading to higher convergence rates and therefore reaching the optimum accuracy more quickly. The insights to help decide the degree of flexibility can be derived from the complexity of ANNs, the data distribution, selection of hyper-parameters and so on. In the wake of this, we introduce a novel flexible loss function for neural networks. The function is shown to characterize a range of fundamentally unique properties from which, much of the properties of other loss functions are only a subset and varying the flexibility parameter in the function allows it to emulate the loss curves and the learning behavior of prevalent static loss functions. The extensive experimentation performed with the loss function demonstrates that it is able to give state-of-the-art performance on selected data sets. Thus, in all the idea of flexibility itself and the proposed function built upon it carry the potential to open to a new interesting chapter in deep learning research.