 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Attention Sinks to Identify and Evaluate Dormant Heads in Pretrained LLMs
Apr 04, 2025Multi-head attention is foundational to large language models (LLMs), enabling different heads to have diverse focus on relevant input tokens. However, learned behaviors like attention sinks, where the first token receives most attention despite limited semantic importance, challenge our understanding of multi-head attention. To analyze this phenomenon, we propose a new definition for attention heads dominated by attention sinks, known as dormant attention heads. We compare our definition to prior work in a model intervention study where we test whether dormant heads matter for inference by zeroing out the output of dormant attention heads. Using six pretrained models and five benchmark datasets, we find our definition to be more model and dataset-agnostic. Using our definition on most models, more than 4% of a model's attention heads can be zeroed while maintaining average accuracy, and zeroing more than 14% of a model's attention heads can keep accuracy to within 1% of the pretrained model's average accuracy. Further analysis reveals that dormant heads emerge early in pretraining and can transition between dormant and active states during pretraining. Additionally, we provide evidence that they depend on characteristics of the input text.
DAVE: Diverse Atomic Visual Elements Dataset with High Representation of Vulnerable Road Users in Complex and Unpredictable Environments
Dec 28, 2024



Most existing traffic video datasets including Waymo are structured, focusing predominantly on Western traffic, which hinders global applicability. Specifically, most Asian scenarios are far more complex, involving numerous objects with distinct motions and behaviors. Addressing this gap, we present a new dataset, DAVE, designed for evaluating perception methods with high representation of Vulnerable Road Users (VRUs: e.g. pedestrians, animals, motorbikes, and bicycles) in complex and unpredictable environments. DAVE is a manually annotated dataset encompassing 16 diverse actor categories (spanning animals, humans, vehicles, etc.) and 16 action types (complex and rare cases like cut-ins, zigzag movement, U-turn, etc.), which require high reasoning ability. DAVE densely annotates over 13 million bounding boxes (bboxes) actors with identification, and more than 1.6 million boxes are annotated with both actor identification and action/behavior details. The videos within DAVE are collected based on a broad spectrum of factors, such as weather conditions, the time of day, road scenarios, and traffic density. DAVE can benchmark video tasks like Tracking, Detection, Spatiotemporal Action Localization, Language-Visual Moment retrieval, and Multi-label Video Action Recognition. Given the critical importance of accurately identifying VRUs to prevent accidents and ensure road safety, in DAVE, vulnerable road users constitute 41.13% of instances, compared to 23.71% in Waymo. DAVE provides an invaluable resource for the development of more sensitive and accurate visual perception algorithms in the complex real world. Our experiments show that existing methods suffer degradation in performance when evaluated on DAVE, highlighting its benefit for future video recognition research.
Learning from Convolution-based Unlearnable Datastes
Nov 04, 2024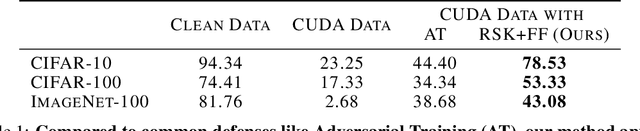



The construction of large datasets for deep learning has raised concerns regarding unauthorized use of online data, leading to increased interest in protecting data from third-parties who want to use it for training. The Convolution-based Unlearnable DAtaset (CUDA) method aims to make data unlearnable by applying class-wise blurs to every image in the dataset so that neural networks learn relations between blur kernels and labels, as opposed to informative features for classifying clean data. In this work, we evaluate whether CUDA data remains unlearnable after image sharpening and frequency filtering, finding that this combination of simple transforms improves the utility of CUDA data for training. In particular, we observe a substantial increase in test accuracy over adversarial training for models trained with CUDA unlearnable data from CIFAR-10, CIFAR-100, and ImageNet-100. In training models to high accuracy using unlearnable data, we underscore the need for ongoing refinement in data poisoning techniques to ensure data privacy. Our method opens new avenues for enhancing the robustness of unlearnable datasets by highlighting that simple methods such as sharpening and frequency filtering are capable of breaking convolution-based unlearnable datasets.
A Simple and Efficient Baseline for Data Attribution on Images
Nov 03, 2023Data attribution methods play a crucial role in understanding machine learning models, providing insight into which training data points are most responsible for model outputs during deployment. However, current state-of-the-art approaches require a large ensemble of as many as 300,000 models to accurately attribute model predictions. These approaches therefore come at a high computational cost, are memory intensive, and are hard to scale to large models or datasets. In this work, we focus on a minimalist baseline, utilizing the feature space of a backbone pretrained via self-supervised learning to perform data attribution. Our method is model-agnostic and scales easily to large datasets. We show results on CIFAR-10 and ImageNet, achieving strong performance that rivals or outperforms state-of-the-art approaches at a fraction of the compute or memory cost. Contrary to prior work, our results reinforce the intuition that a model's prediction on one image is most impacted by visually similar training samples. Our approach serves as a simple and efficient baseline for data attribution on images.
What Can We Learn from Unlearnable Datasets?
May 30, 2023In an era of widespread web scraping, unlearnable dataset methods have the potential to protect data privacy by preventing deep neural networks from generalizing. But in addition to a number of practical limitations that make their use unlikely, we make a number of findings that call into question their ability to safeguard data. First, it is widely believed that neural networks trained on unlearnable datasets only learn shortcuts, simpler rules that are not useful for generalization. In contrast, we find that networks actually can learn useful features that can be reweighed for high test performance, suggesting that image privacy is not preserved. Unlearnable datasets are also believed to induce learning shortcuts through linear separability of added perturbations. We provide a counterexample, demonstrating that linear separability of perturbations is not a necessary condition. To emphasize why linearly separable perturbations should not be relied upon, we propose an orthogonal projection attack which allows learning from unlearnable datasets published in ICML 2021 and ICLR 2023. Our proposed attack is significantly less complex than recently proposed techniques.
JPEG Compressed Images Can Bypass Protections Against AI Editing
Apr 07, 2023



Recently developed text-to-image diffusion models make it easy to edit or create high-quality images. Their ease of use has raised concerns about the potential for malicious editing or deepfake creation. Imperceptible perturbations have been proposed as a means of protecting images from malicious editing by preventing diffusion models from generating realistic images. However, we find that the aforementioned perturbations are not robust to JPEG compression, which poses a major weakness because of the common usage and availability of JPEG. We discuss the importance of robustness for additive imperceptible perturbations and encourage alternative approaches to protect images against editing.
Autoregressive Perturbations for Data Poisoning
Jun 15, 2022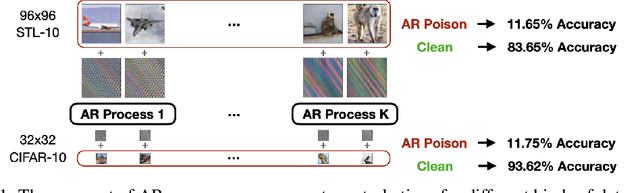
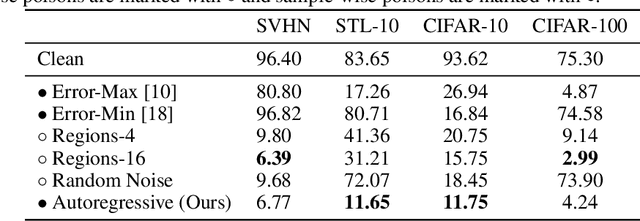
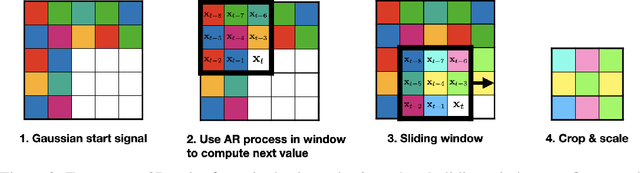
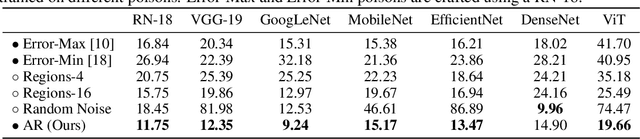
The prevalence of data scraping from social media as a means to obtain datasets has led to growing concerns regarding unauthorized use of data. Data poisoning attacks have been proposed as a bulwark against scraping, as they make data "unlearnable" by adding small, imperceptible perturbations. Unfortunately, existing methods require knowledge of both the target architecture and the complete dataset so that a surrogate network can be trained, the parameters of which are used to generate the attack. In this work, we introduce autoregressive (AR) poisoning, a method that can generate poisoned data without access to the broader dataset. The proposed AR perturbations are generic, can be applied across different datasets, and can poison different architectures. Compared to existing unlearnable methods, our AR poisons are more resistant against common defenses such as adversarial training and strong data augmentations. Our analysis further provides insight into what makes an effective data poison.
Poisons that are learned faster are more effective
Apr 19, 2022
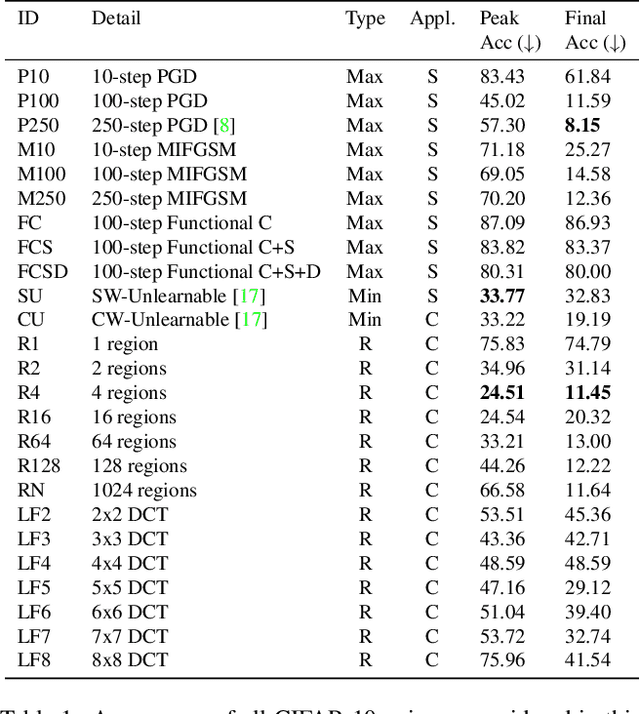
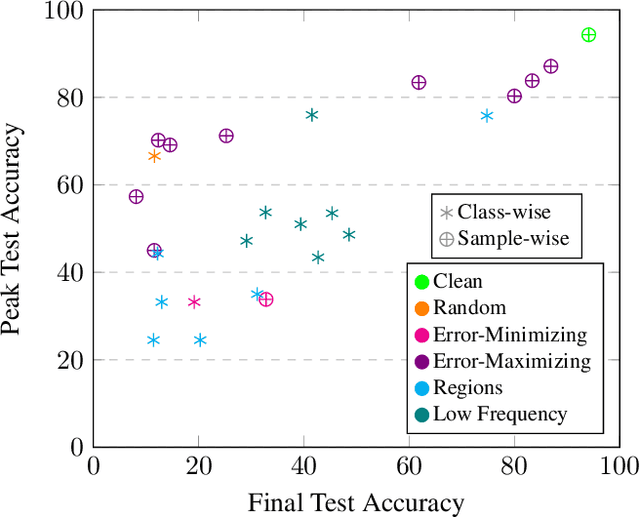

Imperceptible poisoning attacks on entire datasets have recently been touted as methods for protecting data privacy. However, among a number of defenses preventing the practical use of these techniques, early-stopping stands out as a simple, yet effective defense. To gauge poisons' vulnerability to early-stopping, we benchmark error-minimizing, error-maximizing, and synthetic poisons in terms of peak test accuracy over 100 epochs and make a number of surprising observations. First, we find that poisons that reach a low training loss faster have lower peak test accuracy. Second, we find that a current state-of-the-art error-maximizing poison is 7 times less effective when poison training is stopped at epoch 8. Third, we find that stronger, more transferable adversarial attacks do not make stronger poisons. We advocate for evaluating poisons in terms of peak test accuracy.
Adversarially robust segmentation models learn perceptually-aligned gradients
Apr 03, 2022



The effects of adversarial training on semantic segmentation networks has not been thoroughly explored. While previous work has shown that adversarially-trained image classifiers can be used to perform image synthesis, we have yet to understand how best to leverage an adversarially-trained segmentation network to do the same. Using a simple optimizer, we demonstrate that adversarially-trained semantic segmentation networks can be used to perform image inpainting and generation. Our experiments demonstrate that adversarially-trained segmentation networks are more robust and indeed exhibit perceptually-aligned gradients which help in producing plausible image inpaintings. We seek to place additional weight behind the hypothesis that adversarially robust models exhibit gradients that are more perceptually-aligned with human vision. Through image synthesis, we argue that perceptually-aligned gradients promote a better understanding of a neural network's learned representations and aid in making neural networks more interpretable.
AutoProtoNet: Interpretability for Prototypical Networks
Apr 02, 2022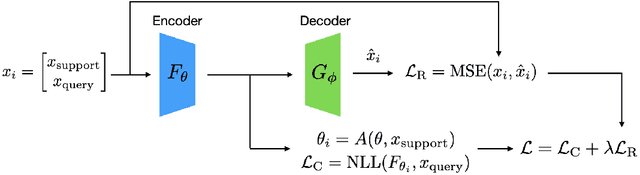
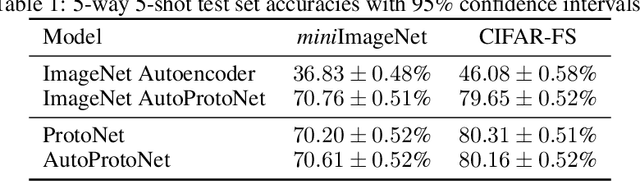

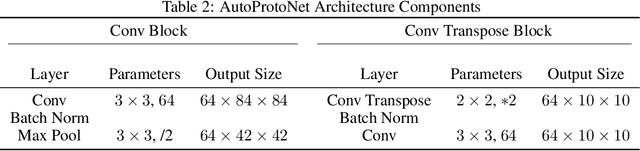
In meta-learning approaches, it is difficult for a practitioner to make sense of what kind of representations the model employs. Without this ability, it can be difficult to both understand what the model knows as well as to make meaningful corrections. To address these challenges, we introduce AutoProtoNet, which builds interpretability into Prototypical Networks by training an embedding space suitable for reconstructing inputs, while remaining convenient for few-shot learning. We demonstrate how points in this embedding space can be visualized and used to understand class representations. We also devise a prototype refinement method, which allows a human to debug inadequate classification parameters. We use this debugging technique on a custom classification task and find that it leads to accuracy improvements on a validation set consisting of in-the-wild images. We advocate for interpretability in meta-learning approaches and show that there are interactive ways for a human to enhance meta-learning algorithms.