 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Convolution-based Unlearnable Datastes
Paper and Code
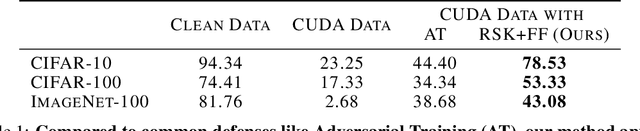



The construction of large datasets for deep learning has raised concerns regarding unauthorized use of online data, leading to increased interest in protecting data from third-parties who want to use it for training. The Convolution-based Unlearnable DAtaset (CUDA) method aims to make data unlearnable by applying class-wise blurs to every image in the dataset so that neural networks learn relations between blur kernels and labels, as opposed to informative features for classifying clean data. In this work, we evaluate whether CUDA data remains unlearnable after image sharpening and frequency filtering, finding that this combination of simple transforms improves the utility of CUDA data for training. In particular, we observe a substantial increase in test accuracy over adversarial training for models trained with CUDA unlearnable data from CIFAR-10, CIFAR-100, and ImageNet-100. In training models to high accuracy using unlearnable data, we underscore the need for ongoing refinement in data poisoning techniques to ensure data privacy. Our method opens new avenues for enhancing the robustness of unlearnable datasets by highlighting that simple methods such as sharpening and frequency filtering are capable of breaking convolution-based unlearnable datasets.