 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Few-Step Generative Models by Amortizing Sample-based Variational Inference
May 27, 2026Aligning a few-step generative model is challenging, since existing alignment frameworks typically rely on restrictive assumptions: a tractable likelihood, a specific ODE/SDE solver, or a particular model family. We introduce FAV, Few-step Generative Models Alignment via Sample-based Variational Inference, a general alignment framework that requires only sample access to the generator and the reference distribution. We cast alignment as sampling from a reward-tilted distribution anchored to a reference distribution. We leverage Stein Variational Gradient Descent as a sample-based variational inference scheme and amortize its particle updates into the generator parameters via fixed-point regression. We evaluate FAV on two domains: robotics manipulation and image generator alignment. On generative policy alignment for robotic manipulation, FAV outperforms prevailing policy extraction baselines across 56 offline and 30 offline-to-online RL tasks. For image generator alignment, FAV fine-tunes diverse few-step backbones, including GAN, drifting model, consistency models, and flow maps, scaling from ImageNet-$256$ to 1024$^2$ text-to-image synthesis. Code is available at https://github.com/Jaewoopudding/FAV.
Measuring the Depth of LLM Unlearning via Activation Patching
May 23, 2026Large language model (LLM) unlearning has emerged as a crucial post-hoc mechanism for privacy protection and AI safety, yet auditing whether target knowledge is truly erased remains challenging. Existing output-level metrics fail to detect when this knowledge remains recoverable from internal representations. Recent white-box studies reveal such residual knowledge but often rely on auxiliary training or dataset-specific adaptations, leaving no generalizable metric. To address these limitations, we propose the Unlearning Depth Score (UDS), a metric that quantifies the mechanistic depth of unlearning via activation patching. UDS first identifies layers that encode the target knowledge using a retain model baseline, then measures how much of it is erased in the unlearned model on a 0-1 scale. In a meta-evaluation across 20 metrics on 150 unlearned models spanning 8 methods, UDS achieves the highest faithfulness and robustness, confirming our causal approach as the most reliable for unlearning evaluation. Case studies further reveal that white-box metrics can disagree at the layer level and that erasure depth varies across examples. We provide guidelines for integrating UDS into existing benchmarking frameworks and streamlining the evaluation pipeline. Code and data are available at https://github.com/gnueaj/unlearning-depth-score
EXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
Direct Diffusion Score Preference Optimization via Stepwise Contrastive Policy-Pair Supervision
Dec 29, 2025Diffusion models have achieved impressive results in generative tasks such as text-to-image synthesis, yet they often struggle to fully align outputs with nuanced user intent and maintain consistent aesthetic quality. Existing preference-based training methods like Diffusion Direct Preference Optimization help address these issues but rely on costly and potentially noisy human-labeled datasets. In this work, we introduce Direct Diffusion Score Preference Optimization (DDSPO), which directly derives per-timestep supervision from winning and losing policies when such policies are available. Unlike prior methods that operate solely on final samples, DDSPO provides dense, transition-level signals across the denoising trajectory. In practice, we avoid reliance on labeled data by automatically generating preference signals using a pretrained reference model: we contrast its outputs when conditioned on original prompts versus semantically degraded variants. This practical strategy enables effective score-space preference supervision without explicit reward modeling or manual annotations. Empirical results demonstrate that DDSPO improves text-image alignment and visual quality, outperforming or matching existing preference-based methods while requiring significantly less supervision. Our implementation is available at: https://dohyun-as.github.io/DDSPO
C2F-Space: Coarse-to-Fine Space Grounding for Spatial Instructions using Vision-Language Models
Nov 19, 2025Space grounding refers to localizing a set of spatial references described in natural language instructions. Traditional methods often fail to account for complex reasoning -- such as distance, geometry, and inter-object relationships -- while vision-language models (VLMs), despite strong reasoning abilities, struggle to produce a fine-grained region of outputs. To overcome these limitations, we propose C2F-Space, a novel coarse-to-fine space-grounding framework that (i) estimates an approximated yet spatially consistent region using a VLM, then (ii) refines the region to align with the local environment through superpixelization. For the coarse estimation, we design a grid-based visual-grounding prompt with a propose-validate strategy, maximizing VLM's spatial understanding and yielding physically and semantically valid canonical region (i.e., ellipses). For the refinement, we locally adapt the region to surrounding environment without over-relaxed to free space. We construct a new space-grounding benchmark and compare C2F-Space with five state-of-the-art baselines using success rate and intersection-over-union. Our C2F-Space significantly outperforms all baselines. Our ablation study confirms the effectiveness of each module in the two-step process and their synergistic effect of the combined framework. We finally demonstrate the applicability of C2F-Space to simulated robotic pick-and-place tasks.
Reinforcement Learning-based Fault-Tolerant Control for Quadrotor with Online Transformer Adaptation
May 13, 2025Multirotors play a significant role in diverse field robotics applications but remain highly susceptible to actuator failures, leading to rapid instability and compromised mission reliability. While various fault-tolerant control (FTC) strategies using reinforcement learning (RL) have been widely explored, most previous approaches require prior knowledge of the multirotor model or struggle to adapt to new configurations. To address these limitations, we propose a novel hybrid RL-based FTC framework integrated with a transformer-based online adaptation module. Our framework leverages a transformer architecture to infer latent representations in real time, enabling adaptation to previously unseen system models without retraining. We evaluate our method in a PyBullet simulation under loss-of-effectiveness actuator faults, achieving a 95% success rate and a positional root mean square error (RMSE) of 0.129 m, outperforming existing adaptation methods with 86% success and an RMSE of 0.153 m. Further evaluations on quadrotors with varying configurations confirm the robustness of our framework across untrained dynamics. These results demonstrate the potential of our framework to enhance the adaptability and reliability of multirotors, enabling efficient fault management in dynamic and uncertain environments. Website is available at http://00dhkim.me/paper/rl-ftc
Random Conditioning with Distillation for Data-Efficient Diffusion Model Compression
Apr 02, 2025Diffusion models generate high-quality images through progressive denoising but are computationally intensive due to large model sizes and repeated sampling. Knowledge distillation, which transfers knowledge from a complex teacher to a simpler student model, has been widely studied in recognition tasks, particularly for transferring concepts unseen during student training. However, its application to diffusion models remains underexplored, especially in enabling student models to generate concepts not covered by the training images. In this work, we propose Random Conditioning, a novel approach that pairs noised images with randomly selected text conditions to enable efficient, image-free knowledge distillation. By leveraging this technique, we show that the student can generate concepts unseen in the training images. When applied to conditional diffusion model distillation, our method allows the student to explore the condition space without generating condition-specific images, resulting in notable improvements in both generation quality and efficiency. This promotes resource-efficient deployment of generative diffusion models, broadening their accessibility for both research and real-world applications. Code, models, and datasets are available at https://dohyun-as.github.io/Random-Conditioning .
COMPASS: A Compiler Framework for Resource-Constrained Crossbar-Array Based In-Memory Deep Learning Accelerators
Jan 12, 2025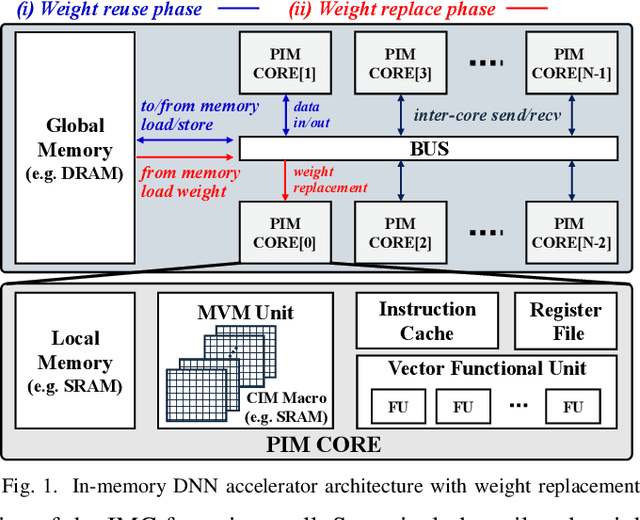
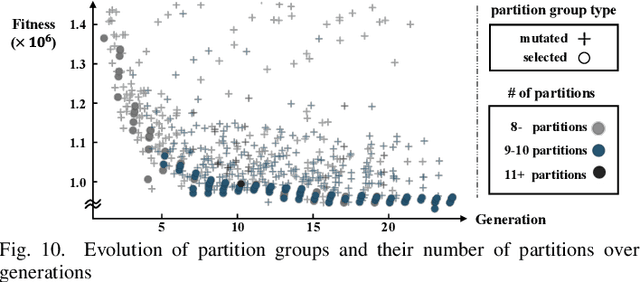
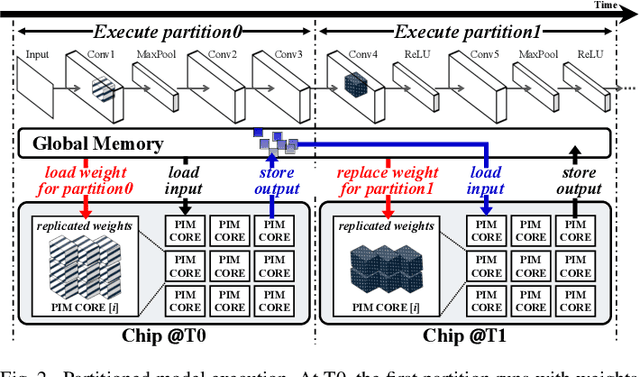
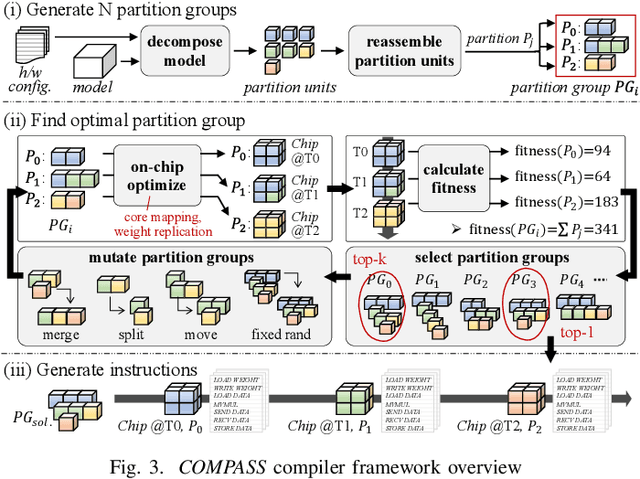
Recently, crossbar array based in-memory accelerators have been gaining interest due to their high throughput and energy efficiency. While software and compiler support for the in-memory accelerators has also been introduced, they are currently limited to the case where all weights are assumed to be on-chip. This limitation becomes apparent with the significantly increasing network sizes compared to the in-memory footprint. Weight replacement schemes are essential to address this issue. We propose COMPASS, a compiler framework for resource-constrained crossbar-based processing-in-memory (PIM) deep neural network (DNN) accelerators. COMPASS is specially targeted for networks that exceed the capacity of PIM crossbar arrays, necessitating access to external memories. We propose an algorithm to determine the optimal partitioning that divides the layers so that each partition can be accelerated on chip. Our scheme takes into account the data dependence between layers, core utilization, and the number of write instructions to minimize latency, memory accesses, and improve energy efficiency. Simulation results demonstrate that COMPASS can accommodate much more networks using a minimal memory footprint, while improving throughput by 1.78X and providing 1.28X savings in energy-delay product (EDP) over baseline partitioning methods.
Learning from Convolution-based Unlearnable Datastes
Nov 04, 2024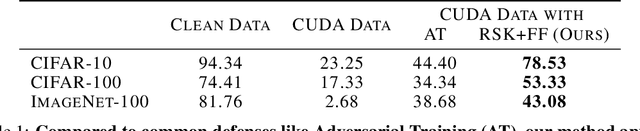



The construction of large datasets for deep learning has raised concerns regarding unauthorized use of online data, leading to increased interest in protecting data from third-parties who want to use it for training. The Convolution-based Unlearnable DAtaset (CUDA) method aims to make data unlearnable by applying class-wise blurs to every image in the dataset so that neural networks learn relations between blur kernels and labels, as opposed to informative features for classifying clean data. In this work, we evaluate whether CUDA data remains unlearnable after image sharpening and frequency filtering, finding that this combination of simple transforms improves the utility of CUDA data for training. In particular, we observe a substantial increase in test accuracy over adversarial training for models trained with CUDA unlearnable data from CIFAR-10, CIFAR-100, and ImageNet-100. In training models to high accuracy using unlearnable data, we underscore the need for ongoing refinement in data poisoning techniques to ensure data privacy. Our method opens new avenues for enhancing the robustness of unlearnable datasets by highlighting that simple methods such as sharpening and frequency filtering are capable of breaking convolution-based unlearnable datasets.
A Survey on Integration of Large Language Models with Intelligent Robots
Apr 14, 2024In recent years, the integration of large language models (LLMs) has revolutionized the field of robotics, enabling robots to communicate, understand, and reason with human-like proficiency. This paper explores the multifaceted impact of LLMs on robotics, addressing key challenges and opportunities for leveraging these models across various domains. By categorizing and analyzing LLM applications within core robotics elements -- communication, perception, planning, and control -- we aim to provide actionable insights for researchers seeking to integrate LLMs into their robotic systems. Our investigation focuses on LLMs developed post-GPT-3.5, primarily in text-based modalities while also considering multimodal approaches for perception and control. We offer comprehensive guidelines and examples for prompt engineering, facilitating beginners' access to LLM-based robotics solutions. Through tutorial-level examples and structured prompt construction, we illustrate how LLM-guided enhancements can be seamlessly integrated into robotics applications. This survey serves as a roadmap for researchers navigating the evolving landscape of LLM-driven robotics, offering a comprehensive overview and practical guidance for harnessing the power of language models in robotics development.