 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuReNav: Superpixel Graph-based Constraint Relaxation for Navigation in Over-constrained Environments
Feb 06, 2026We address the over-constrained planning problem in semi-static environments. The planning objective is to find a best-effort solution that avoids all hard constraint regions while minimally traversing the least risky areas. Conventional methods often rely on pre-defined area costs, limiting generalizations. Further, the spatial continuity of navigation spaces makes it difficult to identify regions that are passable without overestimation. To overcome these challenges, we propose SuReNav, a superpixel graph-based constraint relaxation and navigation method that imitates human-like safe and efficient navigation. Our framework consists of three components: 1) superpixel graph map generation with regional constraints, 2) regional-constraint relaxation using graph neural network trained on human demonstrations for safe and efficient navigation, and 3) interleaving relaxation, planning, and execution for complete navigation. We evaluate our method against state-of-the-art baselines on 2D semantic maps and 3D maps from OpenStreetMap, achieving the highest human-likeness score of complete navigation while maintaining a balanced trade-off between efficiency and safety. We finally demonstrate its scalability and generalization performance in real-world urban navigation with a quadruped robot, Spot.
Learning-based Initialization of Trajectory Optimization for Path-following Problems of Redundant Manipulators
Feb 03, 2026Trajectory optimization (TO) is an efficient tool to generate a redundant manipulator's joint trajectory following a 6-dimensional Cartesian path. The optimization performance largely depends on the quality of initial trajectories. However, the selection of a high-quality initial trajectory is non-trivial and requires a considerable time budget due to the extremely large space of the solution trajectories and the lack of prior knowledge about task constraints in configuration space. To alleviate the issue, we present a learning-based initial trajectory generation method that generates high-quality initial trajectories in a short time budget by adopting example-guided reinforcement learning. In addition, we suggest a null-space projected imitation reward to consider null-space constraints by efficiently learning kinematically feasible motion captured in expert demonstrations. Our statistical evaluation in simulation shows the improved optimality, efficiency, and applicability of TO when we plug in our method's output, compared with three other baselines. We also show the performance improvement and feasibility via real-world experiments with a seven-degree-of-freedom manipulator.
C2F-Space: Coarse-to-Fine Space Grounding for Spatial Instructions using Vision-Language Models
Nov 19, 2025Space grounding refers to localizing a set of spatial references described in natural language instructions. Traditional methods often fail to account for complex reasoning -- such as distance, geometry, and inter-object relationships -- while vision-language models (VLMs), despite strong reasoning abilities, struggle to produce a fine-grained region of outputs. To overcome these limitations, we propose C2F-Space, a novel coarse-to-fine space-grounding framework that (i) estimates an approximated yet spatially consistent region using a VLM, then (ii) refines the region to align with the local environment through superpixelization. For the coarse estimation, we design a grid-based visual-grounding prompt with a propose-validate strategy, maximizing VLM's spatial understanding and yielding physically and semantically valid canonical region (i.e., ellipses). For the refinement, we locally adapt the region to surrounding environment without over-relaxed to free space. We construct a new space-grounding benchmark and compare C2F-Space with five state-of-the-art baselines using success rate and intersection-over-union. Our C2F-Space significantly outperforms all baselines. Our ablation study confirms the effectiveness of each module in the two-step process and their synergistic effect of the combined framework. We finally demonstrate the applicability of C2F-Space to simulated robotic pick-and-place tasks.
A Survey on Integration of Large Language Models with Intelligent Robots
Apr 14, 2024In recent years, the integration of large language models (LLMs) has revolutionized the field of robotics, enabling robots to communicate, understand, and reason with human-like proficiency. This paper explores the multifaceted impact of LLMs on robotics, addressing key challenges and opportunities for leveraging these models across various domains. By categorizing and analyzing LLM applications within core robotics elements -- communication, perception, planning, and control -- we aim to provide actionable insights for researchers seeking to integrate LLMs into their robotic systems. Our investigation focuses on LLMs developed post-GPT-3.5, primarily in text-based modalities while also considering multimodal approaches for perception and control. We offer comprehensive guidelines and examples for prompt engineering, facilitating beginners' access to LLM-based robotics solutions. Through tutorial-level examples and structured prompt construction, we illustrate how LLM-guided enhancements can be seamlessly integrated into robotics applications. This survey serves as a roadmap for researchers navigating the evolving landscape of LLM-driven robotics, offering a comprehensive overview and practical guidance for harnessing the power of language models in robotics development.
LINGO-Space: Language-Conditioned Incremental Grounding for Space
Feb 02, 2024
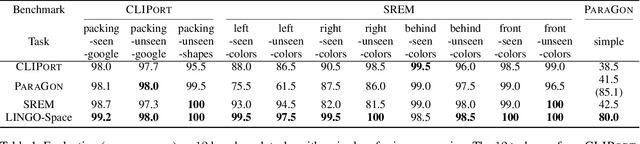
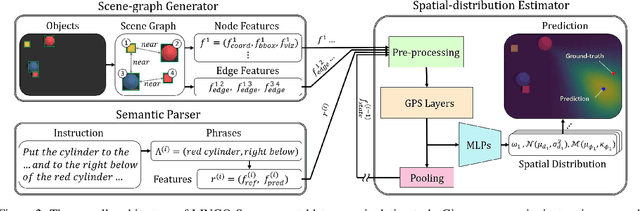
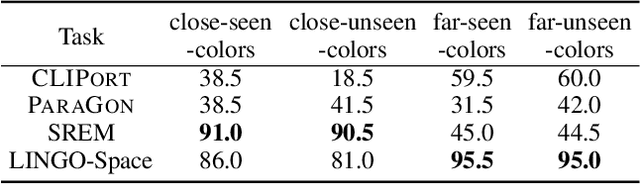
We aim to solve the problem of spatially localizing composite instructions referring to space: space grounding. Compared to current instance grounding, space grounding is challenging due to the ill-posedness of identifying locations referred to by discrete expressions and the compositional ambiguity of referring expressions. Therefore, we propose a novel probabilistic space-grounding methodology (LINGO-Space) that accurately identifies a probabilistic distribution of space being referred to and incrementally updates it, given subsequent referring expressions leveraging configurable polar distributions. Our evaluations show that the estimation using polar distributions enables a robot to ground locations successfully through $20$ table-top manipulation benchmark tests. We also show that updating the distribution helps the grounding method accurately narrow the referring space. We finally demonstrate the robustness of the space grounding with simulated manipulation and real quadruped robot navigation tasks. Code and videos are available at https://lingo-space.github.io.
Graph-based 3D Collision-distance Estimation Network with Probabilistic Graph Rewiring
Oct 06, 2023We aim to solve the problem of data-driven collision-distance estimation given 3-dimensional (3D) geometries. Conventional algorithms suffer from low accuracy due to their reliance on limited representations, such as point clouds. In contrast, our previous graph-based model, GraphDistNet, achieves high accuracy using edge information but incurs higher message-passing costs with growing graph size, limiting its applicability to 3D geometries. To overcome these challenges, we propose GDN-R, a novel 3D graph-based estimation network.GDN-R employs a layer-wise probabilistic graph-rewiring algorithm leveraging the differentiable Gumbel-top-K relaxation. Our method accurately infers minimum distances through iterative graph rewiring and updating relevant embeddings. The probabilistic rewiring enables fast and robust embedding with respect to unforeseen categories of geometries. Through 41,412 random benchmark tasks with 150 pairs of 3D objects, we show GDN-R outperforms state-of-the-art baseline methods in terms of accuracy and generalizability. We also show that the proposed rewiring improves the update performance reducing the size of the estimation model. We finally show its batch prediction and auto-differentiation capabilities for trajectory optimization in both simulated and real-world scenarios.
SGGNet$^2$: Speech-Scene Graph Grounding Network for Speech-guided Navigation
Jul 14, 2023The spoken language serves as an accessible and efficient interface, enabling non-experts and disabled users to interact with complex assistant robots. However, accurately grounding language utterances gives a significant challenge due to the acoustic variability in speakers' voices and environmental noise. In this work, we propose a novel speech-scene graph grounding network (SGGNet$^2$) that robustly grounds spoken utterances by leveraging the acoustic similarity between correctly recognized and misrecognized words obtained from automatic speech recognition (ASR) systems. To incorporate the acoustic similarity, we extend our previous grounding model, the scene-graph-based grounding network (SGGNet), with the ASR model from NVIDIA NeMo. We accomplish this by feeding the latent vector of speech pronunciations into the BERT-based grounding network within SGGNet. We evaluate the effectiveness of using latent vectors of speech commands in grounding through qualitative and quantitative studies. We also demonstrate the capability of SGGNet$^2$ in a speech-based navigation task using a real quadruped robot, RBQ-3, from Rainbow Robotics.
Inverse Constraint Learning and Generalization by Transferable Reward Decomposition
Jun 21, 2023



We present the problem of inverse constraint learning (ICL), which recovers constraints from demonstrations to autonomously reproduce constrained skills in new scenarios. However, ICL suffers from an ill-posed nature, leading to inaccurate inference of constraints from demonstrations. To figure it out, we introduce a transferable constraint learning (TCL) algorithm that jointly infers a task-oriented reward and a task-agnostic constraint, enabling the generalization of learned skills. Our method TCL additively decomposes the overall reward into a task reward and its residual as soft constraints, maximizing policy divergence between task- and constraint-oriented policies to obtain a transferable constraint. Evaluating our method and four baselines in three simulated environments, we show TCL outperforms state-of-the-art IRL and ICL algorithms, achieving up to a $72\%$ higher task-success rates with accurate decomposition compared to the next best approach in novel scenarios. Further, we demonstrate the robustness of TCL on a real-world robotic tray-carrying task.
A Reachability Tree-Based Algorithm for Robot Task and Motion Planning
Mar 07, 2023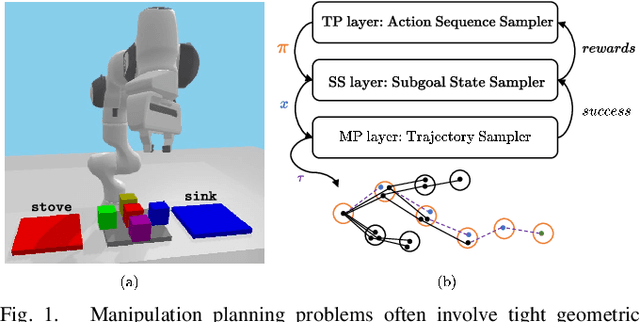
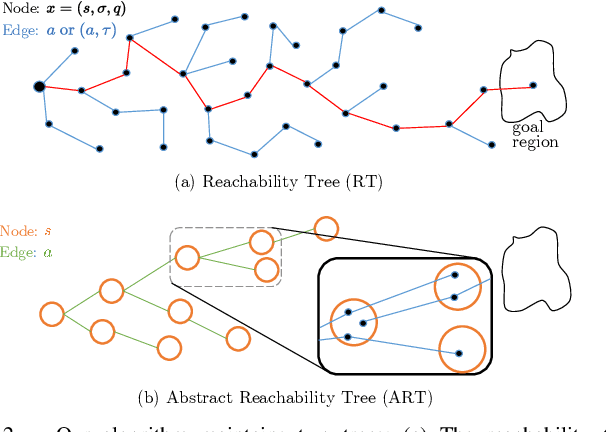
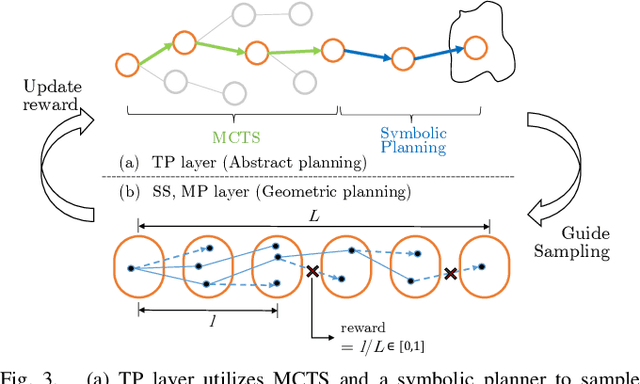
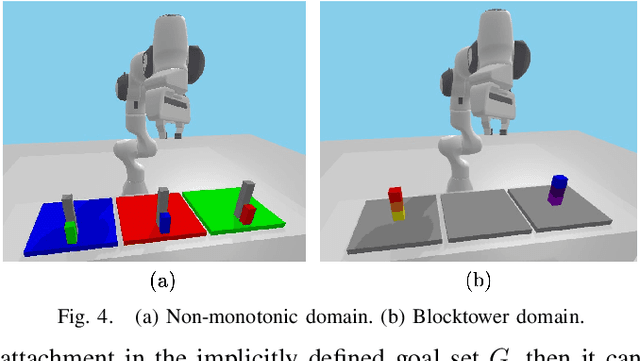
This paper presents a novel algorithm for robot task and motion planning (TAMP) problems by utilizing a reachability tree. While tree-based algorithms are known for their speed and simplicity in motion planning (MP), they are not well-suited for TAMP problems that involve both abstracted and geometrical state variables. To address this challenge, we propose a hierarchical sampling strategy, which first generates an abstracted task plan using Monte Carlo tree search (MCTS) and then fills in the details with a geometrically feasible motion trajectory. Moreover, we show that the performance of the proposed method can be significantly enhanced by selecting an appropriate reward for MCTS and by using a pre-generated goal state that is guaranteed to be geometrically feasible. A comparative study using TAMP benchmark problems demonstrates the effectiveness of the proposed approach.
GraphDistNet: A Graph-based Collision-distance Estimator for Gradient-based Trajectory
Jun 03, 2022
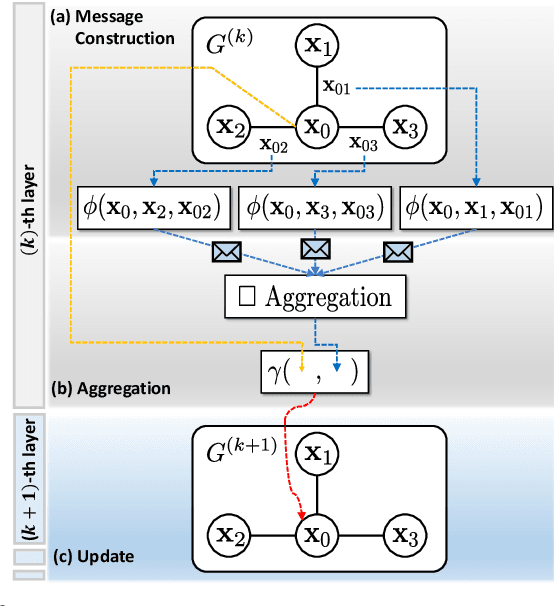
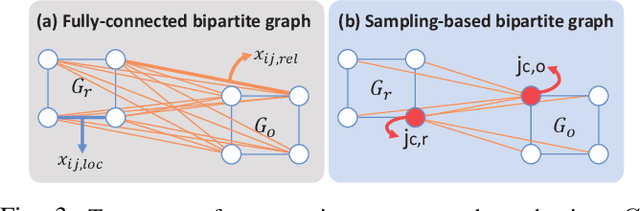
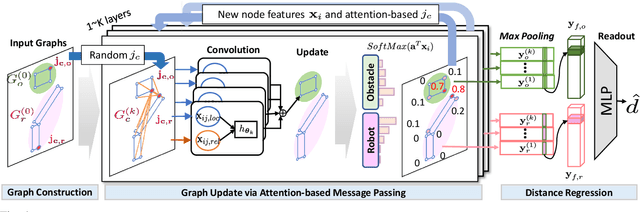
Trajectory optimization (TO) aims to find a sequence of valid states while minimizing costs. However, its fine validation process is often costly due to computationally expensive collision searches, otherwise coarse searches lower the safety of the system losing a precise solution. To resolve the issues, we introduce a new collision-distance estimator, GraphDistNet, that can precisely encode the structural information between two geometries by leveraging edge feature-based convolutional operations, and also efficiently predict a batch of collision distances and gradients through 25,000 random environments with a maximum of 20 unforeseen objects. Further, we show the adoption of attention mechanism enables our method to be easily generalized in unforeseen complex geometries toward TO. Our evaluation show GraphDistNet outperforms state-of-the-art baseline methods in both simulated and real world tasks.