 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Error Patterns of Language Models
May 27, 2026When generating outputs for domains with specific validity constraints (e.g., a program should compile), LLMs often fail in a small number of focused ways: for example, by using Python function names when generating TypeScript. We observe that these error patterns can be represented using a small number of constraints that can be learned in practice. We propose \emph{prefix filters}, which are per-domain-and-LLM symbolic functions, as objects to capture the error patterns, Palla as an algorithm to learn prefix filters efficiently in practice, and implement Palla. Prefix filters learned by Palla i) help us quantitatively analyze the error patterns of LLMs, and ii) can be used to constrain the outputs of a model via constrained sampling algorithms. For example, Palla boosts compile rates for Qwen2.5-1.5B on TypeScript generation, by over 60%, allowing Qwen2.5-1.5B to achieve similar performance to Llama3.1-8B unconstrained.
What are the Right Symmetries for Formal Theorem Proving?
May 21, 2026Formal theorem provers based on large language models (LLMs) are highly sensitive to superficial variations in problem representation: semantically equivalent statements can exhibit drastically different proof success rates, revealing a failure to respect structural symmetries inherent in formal mathematics. This raises a central question: what are the right symmetries for formal theorem proving? We introduce rewriting categories, a category-theoretic framework capturing the compositional, generally non-invertible transformations induced by proof tactics, and use it to formalize two symmetry notions: proof equivariance, governing how proof distributions transform under rewrites, and success invariance (i.e., invariance of success probability), requiring equivalent statements to be solved with the same probability. We observe that state-based next-tactic provers naturally satisfy proof equivariance by operating on proof states. In contrast, state-of-the-art LLM-based provers satisfy neither property, exhibiting large performance variation across equivalent formulations. To mitigate this, we propose test-time methods that aggregate over equivalent rewritings of the input, showing theoretically that they recover success invariance in the sampling limit, and empirically, that they improve robustness and performance under fixed inference budgets. Our results highlight symmetry as a key missing inductive bias in LLM-based theorem proving and suggest test-time computation as a practical route to approximate it.
PoseBridge: Bridging the Skeletonization Gap for Zero-Shot Skeleton-Based Action Recognition
May 12, 2026Zero-shot skeleton-based action recognition (ZSSAR) is typically treated as a skeleton-text alignment problem: encode joint-coordinate sequences, align them with language, and classify unseen actions. We argue that this alignment is often too late. Skeletons are not complete action observations, but compressed outputs of human pose estimation (HPE); by the time alignment begins, human-object interactions and pose-relative visual cues may no longer be explicit. We call this upstream semantic loss. To address it, we propose PoseBridge, an HPE-aware ZSSAR framework that bridges intermediate HPE representations to skeleton-text alignment. Rather than adding an RGB action branch or object detector, PoseBridge extracts pose-anchored semantic cues from the same HPE process that produces skeletons, then transfers them through skeleton-conditioned bridging and semantic prototype adaptation. Across NTU-RGB+D 60/120, PKU-MMD, and Kinetics-200/400, PoseBridge improves ZSSAR performance under the evaluated protocols. On the Kinetics-200/400 PURLS benchmark, which contains in-the-wild videos with diverse scenes and action contexts, PoseBridge shows the clearest separation, improving the strongest compared baseline by 13.3-17.4 points across all eight splits. Our code will be publicly released.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
HarassGuard: Detecting Harassment Behaviors in Social Virtual Reality with Vision-Language Models
Apr 01, 2026Social Virtual Reality (VR) platforms provide immersive social experiences but also expose users to serious risks of online harassment. Existing safety measures are largely reactive, while proactive solutions that detect harassment behavior during an incident often depend on sensitive biometric data, raising privacy concerns. In this paper, we present HarassGuard, a vision-language model (VLM) based system that detects physical harassment in social VR using only visual input. We construct an IRB-approved harassment vision dataset, apply prompt engineering, and fine-tune VLMs to detect harassment behavior by considering contextual information in social VR. Experimental results demonstrate that HarassGuard achieves competitive performance compared to state-of-the-art baselines (i.e., LSTM/CNN, Transformer), reaching an accuracy of up to 88.09% in binary classification and 68.85% in multi-class classification. Notably, HarassGuard matches these baselines while using significantly fewer fine-tuning samples (200 vs. 1,115), offering unique advantages in contextual reasoning and privacy-preserving detection.
One-step Language Modeling via Continuous Denoising
Feb 18, 2026Language models based on discrete diffusion have attracted widespread interest for their potential to provide faster generation than autoregressive models. In practice, however, they exhibit a sharp degradation of sample quality in the few-step regime, failing to realize this promise. Here we show that language models leveraging flow-based continuous denoising can outperform discrete diffusion in both quality and speed. By revisiting the fundamentals of flows over discrete modalities, we build a flow-based language model (FLM) that performs Euclidean denoising over one-hot token encodings. We show that the model can be trained by predicting the clean data via a cross entropy objective, where we introduce a simple time reparameterization that greatly improves training stability and generation quality. By distilling FLM into its associated flow map, we obtain a distilled flow map language model (FMLM) capable of few-step generation. On the LM1B and OWT language datasets, FLM attains generation quality matching state-of-the-art discrete diffusion models. With FMLM, our approach outperforms recent few-step language models across the board, with one-step generation exceeding their 8-step quality. Our work calls into question the widely held hypothesis that discrete diffusion processes are necessary for generative modeling over discrete modalities, and paves the way toward accelerated flow-based language modeling at scale. Code is available at https://github.com/david3684/flm.
Continuous Diffusion Models Can Obey Formal Syntax
Feb 12, 2026Diffusion language models offer a promising alternative to autoregressive models due to their global, non-causal generation process, but their continuous latent dynamics make discrete constraints -- e.g., the output should be a JSON file that matches a given schema -- difficult to impose. We introduce a training-free guidance method for steering continuous diffusion language models to satisfy formal syntactic constraints expressed using regular expressions. Our approach constructs an analytic score estimating the probability that a latent state decodes to a valid string accepted by a given regular expression, and uses its gradient to guide sampling, without training auxiliary classifiers. The denoising process targets the base model conditioned on syntactic validity. We implement our method in Diffinity on top of the PLAID diffusion model and evaluate it on 180 regular-expression constraints over JSON and natural-language benchmarks. Diffinity achieves 68-96\% constraint satisfaction while incurring only a small perplexity cost relative to unconstrained sampling, outperforming autoregressive constrained decoding in both constraint satisfaction and output quality.
Inverting Data Transformations via Diffusion Sampling
Feb 09, 2026We study the problem of transformation inversion on general Lie groups: a datum is transformed by an unknown group element, and the goal is to recover an inverse transformation that maps it back to the original data distribution. Such unknown transformations arise widely in machine learning and scientific modeling, where they can significantly distort observations. We take a probabilistic view and model the posterior over transformations as a Boltzmann distribution defined by an energy function on data space. To sample from this posterior, we introduce a diffusion process on Lie groups that keeps all updates on-manifold and only requires computations in the associated Lie algebra. Our method, Transformation-Inverting Energy Diffusion (TIED), relies on a new trivialized target-score identity that enables efficient score-based sampling of the transformation posterior. As a key application, we focus on test-time equivariance, where the objective is to improve the robustness of pretrained neural networks to input transformations. Experiments on image homographies and PDE symmetries demonstrate that TIED can restore transformed inputs to the training distribution at test time, showing improved performance over strong canonicalization and sampling baselines. Code is available at https://github.com/jw9730/tied.
FiLoRA: Focus-and-Ignore LoRA for Controllable Feature Reliance
Feb 02, 2026Multimodal foundation models integrate heterogeneous signals across modalities, yet it remains poorly understood how their predictions depend on specific internal feature groups and whether such reliance can be deliberately controlled. Existing studies of shortcut and spurious behavior largely rely on post hoc analyses or feature removal, offering limited insight into whether reliance can be modulated without altering task semantics. We introduce FiLoRA (Focus-and-Ignore LoRA), an instruction-conditioned, parameter-efficient adaptation framework that enables explicit control over internal feature reliance while keeping the predictive objective fixed. FiLoRA decomposes adaptation into feature group-aligned LoRA modules and applies instruction-conditioned gating, allowing natural language instructions to act as computation-level control signals rather than task redefinitions. Across text--image and audio--visual benchmarks, we show that instruction-conditioned gating induces consistent and causal shifts in internal computation, selectively amplifying or suppressing core and spurious feature groups without modifying the label space or training objective. Further analyses demonstrate that FiLoRA yields improved robustness under spurious feature interventions, revealing a principled mechanism to regulate reliance beyond correlation-driven learning.
Near-Real-Time InSAR Phase Estimation for Large-Scale Surface Displacement Monitoring
Nov 15, 2025
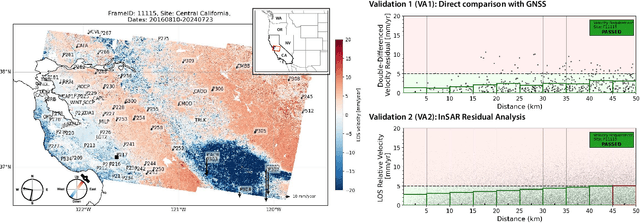


Operational near-real-time monitoring of Earth's surface deformation using Interferometric Synthetic Aperture Radar (InSAR) requires processing algorithms that efficiently incorporate new acquisitions without reprocessing historical archives. We present sequential phase linking approach using compressed single-look-complex images (SLCs) capable of producing surface displacement estimates within hours of the time of a new acquisition. Our key algorithmic contribution is a mini-stack reference scheme that maintains phase consistency across processing batches without adjusting or re-estimating previous time steps, enabling straightforward operational deployment. We introduce online methods for persistent and distributed scatterer identification that adapt to temporal changes in surface properties through incremental amplitude statistics updates. The processing chain incorporates multiple complementary metrics for pixel quality that are reliable for small SLC stack sizes, and an L1-norm network inversion to limit propagation of unwrapping errors across the time series. We use our algorithm to produce OPERA Surface Displacement from Sentinel-1 product, the first continental-scale surface displacement product over North America. Validation against GPS measurements and InSAR residual analysis demonstrates millimeter-level agreement in velocity estimates in varying environmental conditions. We demonstrate our algorithm's capabilities with a successful recovery of meter-scale co-eruptive displacement at Kilauea volcano during the 2018 eruption, as well as detection of subtle uplift at Three Sisters volcano, Oregon- a challenging environment for C-band InSAR due to dense vegetation and seasonal snow. We have made all software available as open source libraries, providing a significant advancement to the open scientific community's ability to process large InSAR data sets in a cloud environment.