 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Disk KV Cache Management for Efficient Multi-Instance Inference in RAG-Powered LLMs
Apr 16, 2025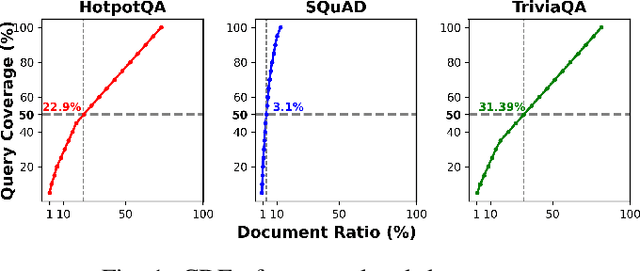
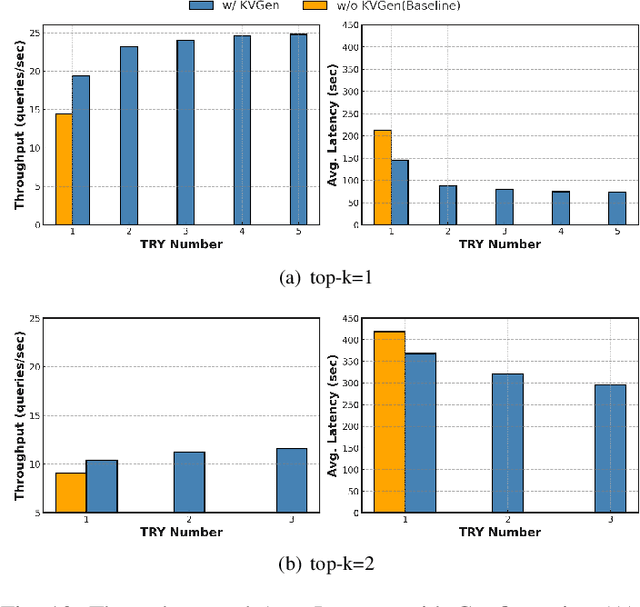
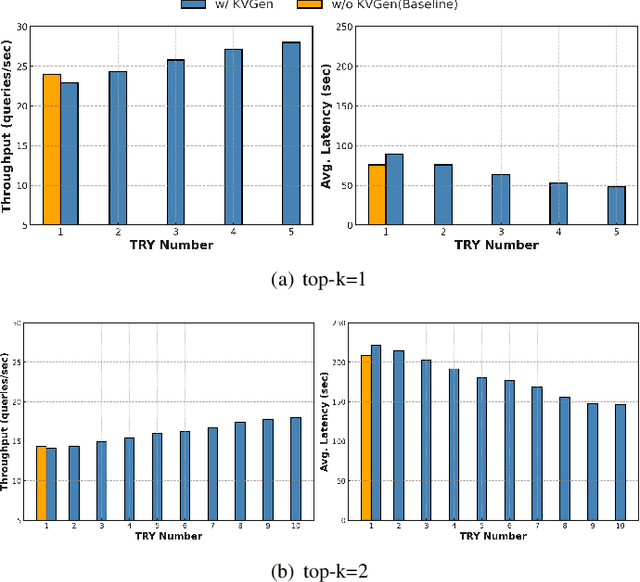
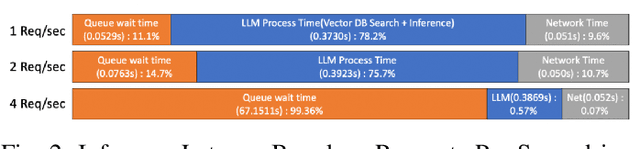
Recent large language models (LLMs) face increasing inference latency as input context length and model size continue to grow. In particular, the retrieval-augmented generation (RAG) technique, which enhances LLM responses by incorporating external knowledge, exacerbates this issue by significantly increasing the number of input tokens. This expansion in token length leads to a substantial rise in computational overhead, particularly during the prefill stage, resulting in prolonged time-to-first-token (TTFT). To address this issue, this paper proposes a method to reduce TTFT by leveraging a disk-based key-value (KV) cache to lessen the computational burden during the prefill stage. We also introduce a disk-based shared KV cache management system, called Shared RAG-DCache, for multi-instance LLM RAG service environments. This system, together with an optimal system configuration, improves both throughput and latency under given resource constraints. Shared RAG-DCache exploits the locality of documents related to user queries in RAG, as well as the queueing delay in LLM inference services. It proactively generates and stores disk KV caches for query-related documents and shares them across multiple LLM instances to enhance inference performance. In experiments on a single host equipped with 2 GPUs and 1 CPU, Shared RAG-DCache achieved a 15~71% increase in throughput and up to a 12~65% reduction in latency, depending on the resource configuration.
Relation-based Counterfactual Data Augmentation and Contrastive Learning for Robustifying Natural Language Inference Models
Oct 28, 2024



Although pre-trained language models show good performance on various natural language processing tasks, they often rely on non-causal features and patterns to determine the outcome. For natural language inference tasks, previous results have shown that even a model trained on a large number of data fails to perform well on counterfactually revised data, indicating that the model is not robustly learning the semantics of the classes. In this paper, we propose a method in which we use token-based and sentence-based augmentation methods to generate counterfactual sentence pairs that belong to each class, and apply contrastive learning to help the model learn the difference between sentence pairs of different classes with similar contexts. Evaluation results with counterfactually-revised dataset and general NLI datasets show that the proposed method can improve the performance and robustness of the NLI model.
SMCL: Saliency Masked Contrastive Learning for Long-tailed Recognition
Jun 04, 2024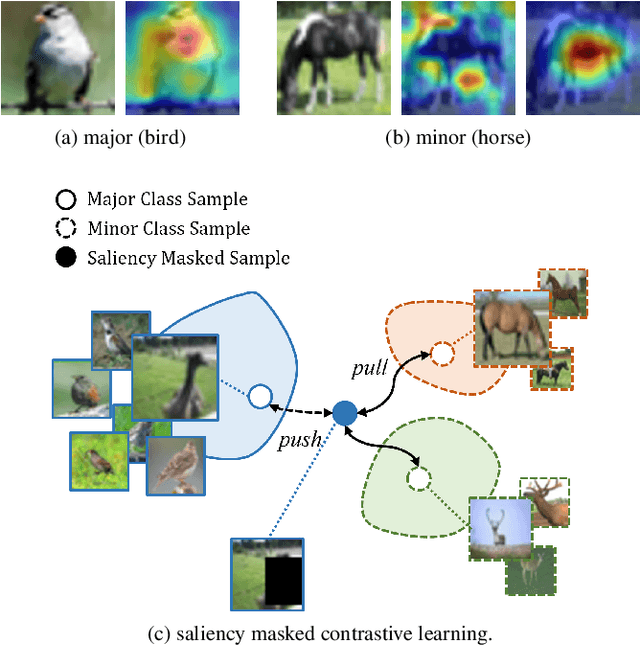
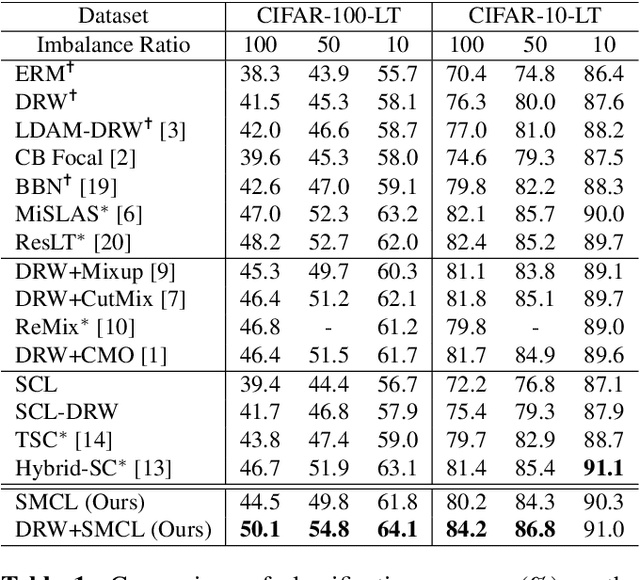
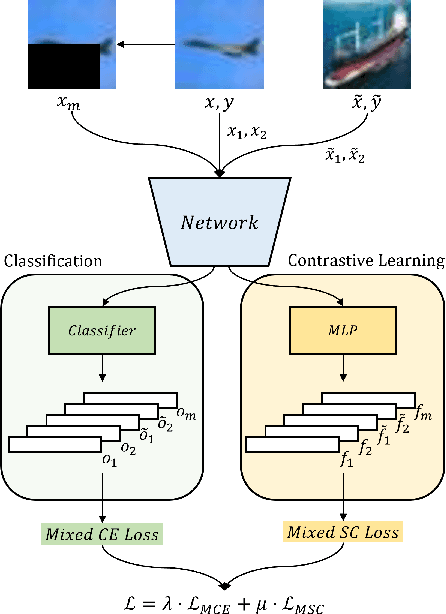
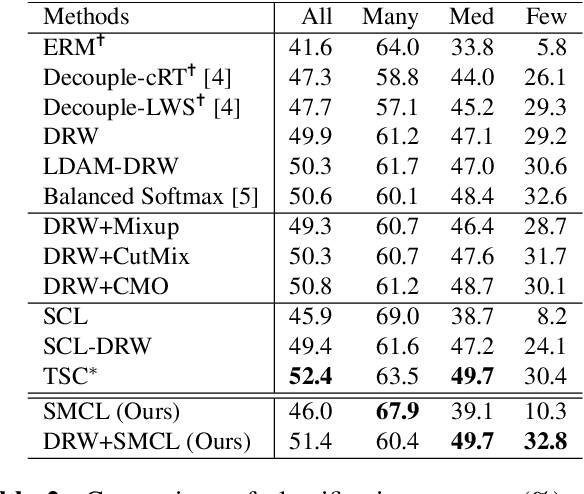
Real-world data often follow a long-tailed distribution with a high imbalance in the number of samples between classes. The problem with training from imbalanced data is that some background features, common to all classes, can be unobserved in classes with scarce samples. As a result, this background correlates to biased predictions into ``major" classes. In this paper, we propose saliency masked contrastive learning, a new method that uses saliency masking and contrastive learning to mitigate the problem and improve the generalizability of a model. Our key idea is to mask the important part of an image using saliency detection and use contrastive learning to move the masked image towards minor classes in the feature space, so that background features present in the masked image are no longer correlated with the original class. Experiment results show that our method achieves state-of-the-art level performance on benchmark long-tailed datasets.
An Ensemble of Simple Convolutional Neural Network Models for MNIST Digit Recognition
Aug 12, 2020
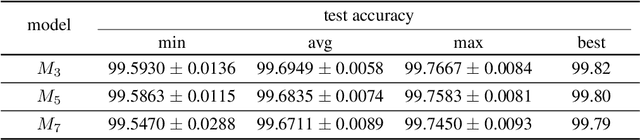
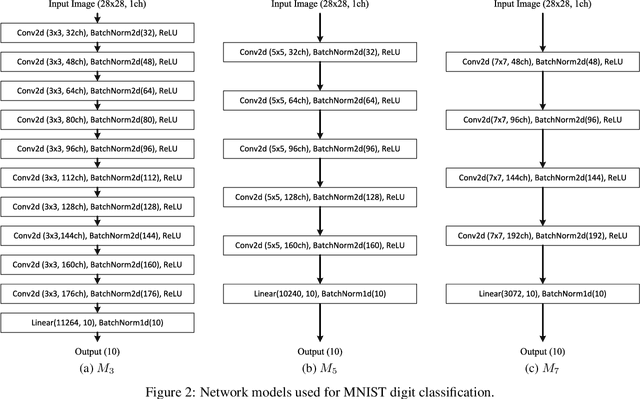
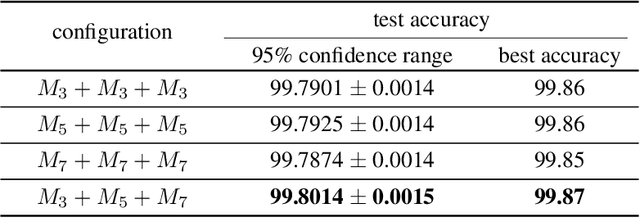
We report that a very high accuracy on the MNIST test set can be achieved by using simple convolutional neural network (CNN) models. We use three different models with 3x3, 5x5, and 7x7 kernel size in the convolution layers. Each model consists of a set of convolution layers followed by a single fully connected layer. Every convolution layer uses batch normalization and ReLU activation, and pooling is not used. Rotation and translation is used to augment training data, which is frequently used in most image classification tasks. A majority voting using the three models independently trained on the training data set can achieve up to 99.87% accuracy on the test set, which is one of the state-of-the-art results. A two-layer ensemble, a heterogeneous ensemble of three homogeneous ensemble networks, can achieve up to 99.91% test accuracy. The results can be reproduced by using the code at: https://github.com/ansh941/MnistSimpleCNN