 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation-based Counterfactual Data Augmentation and Contrastive Learning for Robustifying Natural Language Inference Models
Oct 28, 2024



Although pre-trained language models show good performance on various natural language processing tasks, they often rely on non-causal features and patterns to determine the outcome. For natural language inference tasks, previous results have shown that even a model trained on a large number of data fails to perform well on counterfactually revised data, indicating that the model is not robustly learning the semantics of the classes. In this paper, we propose a method in which we use token-based and sentence-based augmentation methods to generate counterfactual sentence pairs that belong to each class, and apply contrastive learning to help the model learn the difference between sentence pairs of different classes with similar contexts. Evaluation results with counterfactually-revised dataset and general NLI datasets show that the proposed method can improve the performance and robustness of the NLI model.
An Ensemble of Simple Convolutional Neural Network Models for MNIST Digit Recognition
Aug 12, 2020
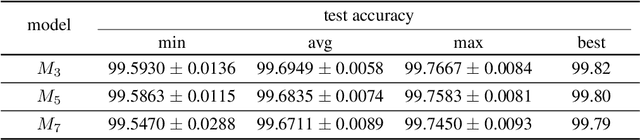
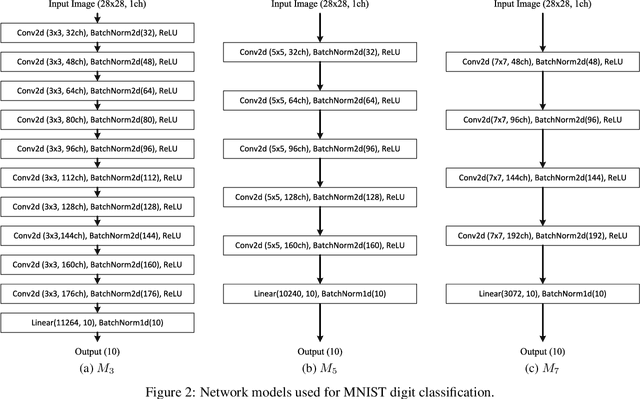
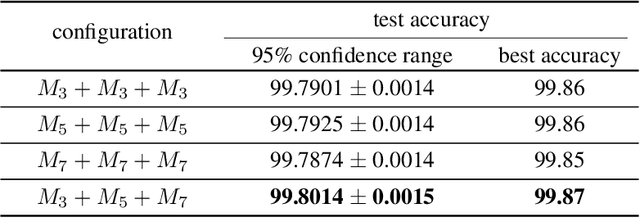
We report that a very high accuracy on the MNIST test set can be achieved by using simple convolutional neural network (CNN) models. We use three different models with 3x3, 5x5, and 7x7 kernel size in the convolution layers. Each model consists of a set of convolution layers followed by a single fully connected layer. Every convolution layer uses batch normalization and ReLU activation, and pooling is not used. Rotation and translation is used to augment training data, which is frequently used in most image classification tasks. A majority voting using the three models independently trained on the training data set can achieve up to 99.87% accuracy on the test set, which is one of the state-of-the-art results. A two-layer ensemble, a heterogeneous ensemble of three homogeneous ensemble networks, can achieve up to 99.91% test accuracy. The results can be reproduced by using the code at: https://github.com/ansh941/MnistSimpleCNN