 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Disk KV Cache Management for Efficient Multi-Instance Inference in RAG-Powered LLMs
Apr 16, 2025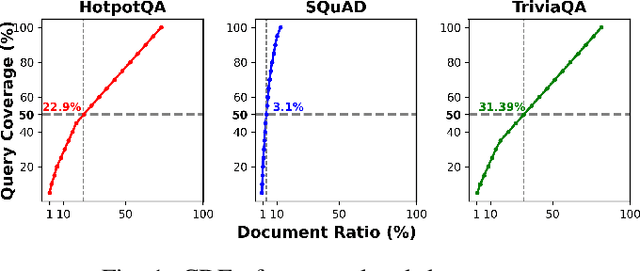
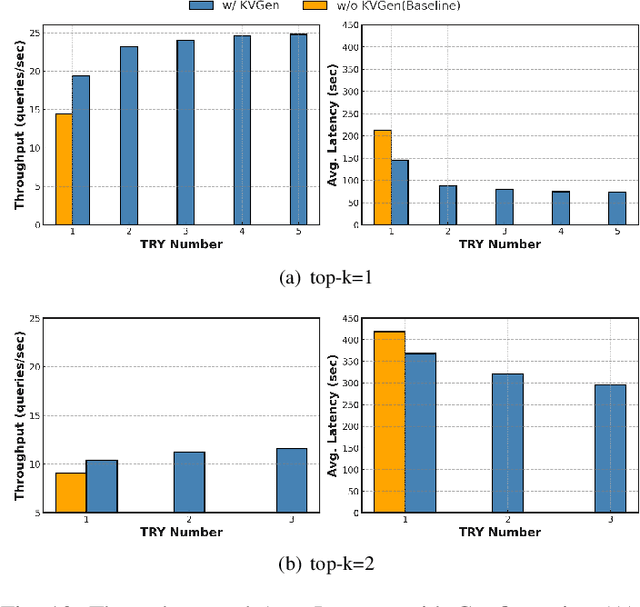
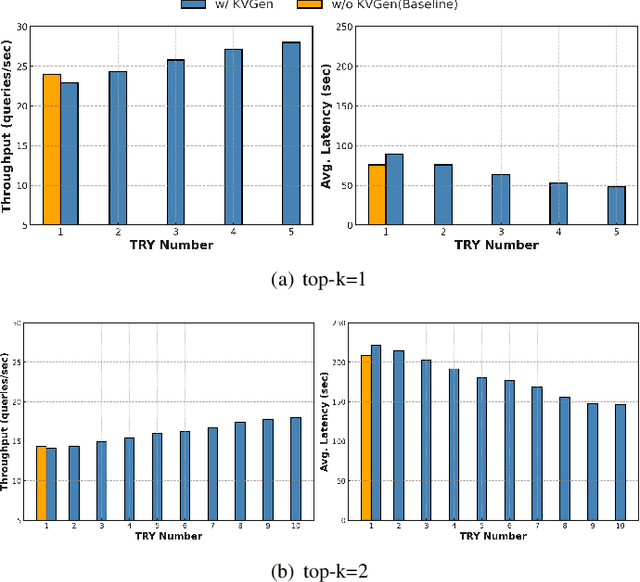
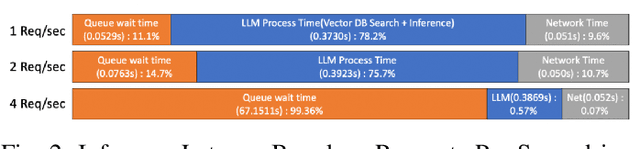
Recent large language models (LLMs) face increasing inference latency as input context length and model size continue to grow. In particular, the retrieval-augmented generation (RAG) technique, which enhances LLM responses by incorporating external knowledge, exacerbates this issue by significantly increasing the number of input tokens. This expansion in token length leads to a substantial rise in computational overhead, particularly during the prefill stage, resulting in prolonged time-to-first-token (TTFT). To address this issue, this paper proposes a method to reduce TTFT by leveraging a disk-based key-value (KV) cache to lessen the computational burden during the prefill stage. We also introduce a disk-based shared KV cache management system, called Shared RAG-DCache, for multi-instance LLM RAG service environments. This system, together with an optimal system configuration, improves both throughput and latency under given resource constraints. Shared RAG-DCache exploits the locality of documents related to user queries in RAG, as well as the queueing delay in LLM inference services. It proactively generates and stores disk KV caches for query-related documents and shares them across multiple LLM instances to enhance inference performance. In experiments on a single host equipped with 2 GPUs and 1 CPU, Shared RAG-DCache achieved a 15~71% increase in throughput and up to a 12~65% reduction in latency, depending on the resource configuration.
Cost-Efficient LLM Serving in the Cloud: VM Selection with KV Cache Offloading
Apr 16, 2025LLM inference is essential for applications like text summarization, translation, and data analysis, but the high cost of GPU instances from Cloud Service Providers (CSPs) like AWS is a major burden. This paper proposes InferSave, a cost-efficient VM selection framework for cloud based LLM inference. InferSave optimizes KV cache offloading based on Service Level Objectives (SLOs) and workload charac teristics, estimating GPU memory needs, and recommending cost-effective VM instances. Additionally, the Compute Time Calibration Function (CTCF) improves instance selection accuracy by adjusting for discrepancies between theoretical and actual GPU performance. Experiments on AWS GPU instances show that selecting lower-cost instances without KV cache offloading improves cost efficiency by up to 73.7% for online workloads, while KV cache offloading saves up to 20.19% for offline workloads.
Audio-Based Linguistic Feature Extraction for Enhancing Multi-lingual and Low-Resource Text-to-Speech
Sep 27, 2024The difficulty of acquiring abundant, high-quality data, especially in multi-lingual contexts, has sparked interest in addressing low-resource scenarios. Moreover, current literature rely on fixed expressions from language IDs, which results in the inadequate learning of language representations, and the failure to generate speech in unseen languages. To address these challenges, we propose a novel method that directly extracts linguistic features from audio input while effectively filtering out miscellaneous acoustic information including speaker-specific attributes like timbre. Subjective and objective evaluations affirm the effectiveness of our approach for multi-lingual text-to-speech, and highlight its superiority in low-resource transfer learning for previously unseen language.
On stable wrapper-based parameter selection method for efficient ANN-based data-driven modeling of turbulent flows
Aug 04, 2023
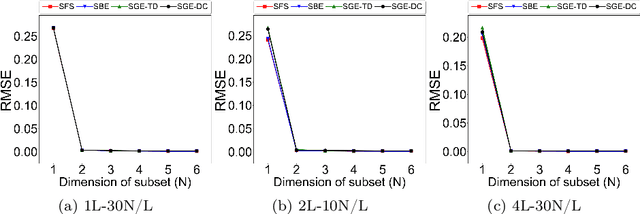


To model complex turbulent flow and heat transfer phenomena, this study aims to analyze and develop a reduced modeling approach based on artificial neural network (ANN) and wrapper methods. This approach has an advantage over other methods such as the correlation-based filter method in terms of removing redundant or irrelevant parameters even under non-linearity among them. As a downside, the overfitting and randomness of ANN training may produce inconsistent subsets over selection trials especially in a higher physical dimension. This study analyzes a few existing ANN-based wrapper methods and develops a revised one based on the gradient-based subset selection indices to minimize the loss in the total derivative or the directional consistency at each elimination step. To examine parameter reduction performance and consistency-over-trials, we apply these methods to a manufactured subset selection problem, modeling of the bubble size in a turbulent bubbly flow, and modeling of the spatially varying turbulent Prandtl number in a duct flow. It is found that the gradient-based subset selection to minimize the total derivative loss results in improved consistency-over-trials compared to the other ANN-based wrapper methods, while removing unnecessary parameters successfully. For the reduced turbulent Prandtl number model, the gradient-based subset selection improves the prediction in the validation case over the other methods. Also, the reduced parameter subsets show a slight increase in the training speed compared to the others.