 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Experts with Intermediate CTC Supervision for Accented Speech Recognition
Feb 02, 2026Accented speech remains a persistent challenge for automatic speech recognition (ASR), as most models are trained on data dominated by a few high-resource English varieties, leading to substantial performance degradation for other accents. Accent-agnostic approaches improve robustness yet struggle with heavily accented or unseen varieties, while accent-specific methods rely on limited and often noisy labels. We introduce Moe-Ctc, a Mixture-of-Experts architecture with intermediate CTC supervision that jointly promotes expert specialization and generalization. During training, accent-aware routing encourages experts to capture accent-specific patterns, which gradually transitions to label-free routing for inference. Each expert is equipped with its own CTC head to align routing with transcription quality, and a routing-augmented loss further stabilizes optimization. Experiments on the Mcv-Accent benchmark demonstrate consistent gains across both seen and unseen accents in low- and high-resource conditions, achieving up to 29.3% relative WER reduction over strong FastConformer baselines.
Merging Triggers, Breaking Backdoors: Defensive Poisoning for Instruction-Tuned Language Models
Jan 07, 2026Large Language Models (LLMs) have greatly advanced Natural Language Processing (NLP), particularly through instruction tuning, which enables broad task generalization without additional fine-tuning. However, their reliance on large-scale datasets-often collected from human or web sources-makes them vulnerable to backdoor attacks, where adversaries poison a small subset of data to implant hidden behaviors. Despite this growing risk, defenses for instruction-tuned models remain underexplored. We propose MB-Defense (Merging & Breaking Defense Framework), a novel training pipeline that immunizes instruction-tuned LLMs against diverse backdoor threats. MB-Defense comprises two stages: (i) defensive poisoning, which merges attacker and defensive triggers into a unified backdoor representation, and (ii) weight recovery, which breaks this representation through additional training to restore clean behavior. Extensive experiments across multiple LLMs show that MB-Defense substantially lowers attack success rates while preserving instruction-following ability. Our method offers a generalizable and data-efficient defense strategy, improving the robustness of instruction-tuned LLMs against unseen backdoor attacks.
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
Oct 31, 2025Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, yet they still suffer from a multilingual reasoning gap, performing better in high-resource languages than in low-resource ones. While recent efforts have reduced this gap, its underlying causes remain largely unexplored. In this paper, we address this by showing that the multilingual reasoning gap largely stems from failures in language understanding-the model's inability to represent the multilingual input meaning into the dominant language (i.e., English) within its reasoning trace. This motivates us to examine whether understanding failures can be detected, as this ability could help mitigate the multilingual reasoning gap. To this end, we evaluate a range of detection methods and find that understanding failures can indeed be identified, with supervised approaches performing best. Building on this, we propose Selective Translation, a simple yet effective strategy that translates the multilingual input into English only when an understanding failure is detected. Experimental results show that Selective Translation bridges the multilingual reasoning gap, achieving near full-translation performance while using translation for only about 20% of inputs. Together, our work demonstrates that understanding failures are the primary cause of the multilingual reasoning gap and can be detected and selectively mitigated, providing key insight into its origin and a promising path toward more equitable multilingual reasoning. Our code and data are publicly available at https://github.com/deokhk/RLM_analysis.
DeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Jun 09, 2025
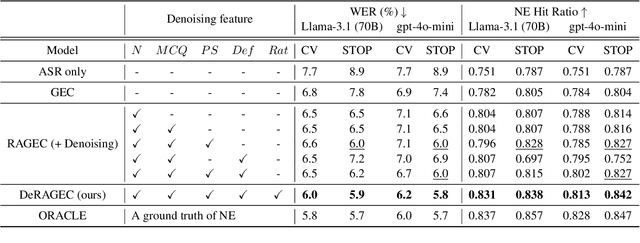

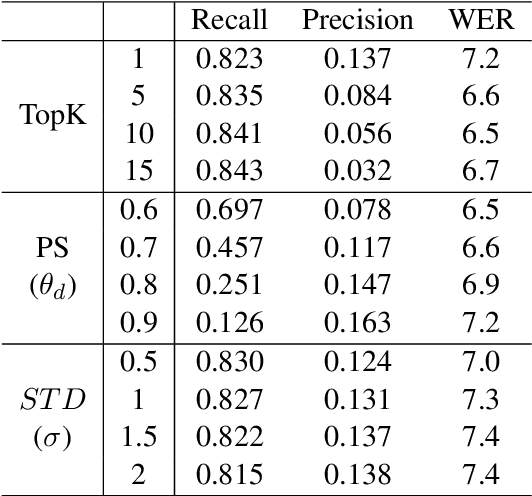
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec
Self-Correcting Code Generation Using Small Language Models
May 29, 2025Self-correction has demonstrated potential in code generation by allowing language models to revise and improve their outputs through successive refinement. Recent studies have explored prompting-based strategies that incorporate verification or feedback loops using proprietary models, as well as training-based methods that leverage their strong reasoning capabilities. However, whether smaller models possess the capacity to effectively guide their outputs through self-reflection remains unexplored. Our findings reveal that smaller models struggle to exhibit reflective revision behavior across both self-correction paradigms. In response, we introduce CoCoS, an approach designed to enhance the ability of small language models for multi-turn code correction. Specifically, we propose an online reinforcement learning objective that trains the model to confidently maintain correct outputs while progressively correcting incorrect outputs as turns proceed. Our approach features an accumulated reward function that aggregates rewards across the entire trajectory and a fine-grained reward better suited to multi-turn correction scenarios. This facilitates the model in enhancing initial response quality while achieving substantial improvements through self-correction. With 1B-scale models, CoCoS achieves improvements of 35.8% on the MBPP and 27.7% on HumanEval compared to the baselines.
EnSToM: Enhancing Dialogue Systems with Entropy-Scaled Steering Vectors for Topic Maintenance
May 22, 2025Small large language models (sLLMs) offer the advantage of being lightweight and efficient, which makes them suitable for resource-constrained environments. However, sLLMs often struggle to maintain topic consistency in task-oriented dialogue systems, which is critical for scenarios such as service chatbots. Specifically, it is important to ensure that the model denies off-topic or malicious inputs and adheres to its intended functionality so as to prevent potential misuse and uphold reliability. Towards this, existing activation engineering approaches have been proposed to manipulate internal activations during inference. While these methods are effective in certain scenarios, our preliminary experiments reveal their limitations in ensuring topic adherence. Therefore, to address this, we propose a novel approach termed Entropy-scaled Steering vectors for Topic Maintenance (EnSToM). EnSToM dynamically adjusts the steering intensity based on input uncertainty, which allows the model to handle off-topic distractors effectively while preserving on-topic accuracy. Our experiments demonstrate that EnSToM achieves significant performance gain with a relatively small data size compared to fine-tuning approaches. By improving topic adherence without compromising efficiency, our approach provides a robust solution for enhancing sLLM-based dialogue systems.
GuRE:Generative Query REwriter for Legal Passage Retrieval
May 19, 2025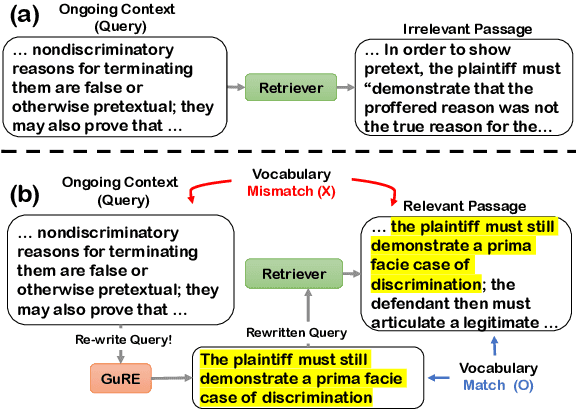
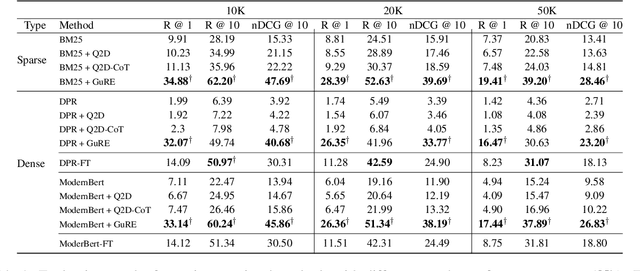
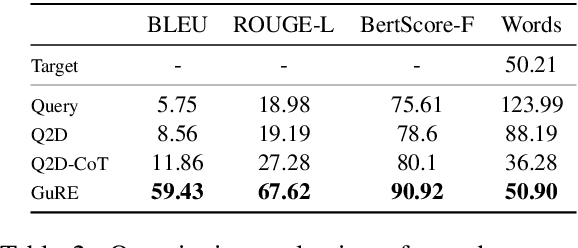

Legal Passage Retrieval (LPR) systems are crucial as they help practitioners save time when drafting legal arguments. However, it remains an underexplored avenue. One primary reason is the significant vocabulary mismatch between the query and the target passage. To address this, we propose a simple yet effective method, the Generative query REwriter (GuRE). We leverage the generative capabilities of Large Language Models (LLMs) by training the LLM for query rewriting. "Rewritten queries" help retrievers to retrieve target passages by mitigating vocabulary mismatch. Experimental results show that GuRE significantly improves performance in a retriever-agnostic manner, outperforming all baseline methods. Further analysis reveals that different training objectives lead to distinct retrieval behaviors, making GuRE more suitable than direct retriever fine-tuning for real-world applications. Codes are avaiable at github.com/daehuikim/GuRE.
PicPersona-TOD : A Dataset for Personalizing Utterance Style in Task-Oriented Dialogue with Image Persona
Apr 24, 2025
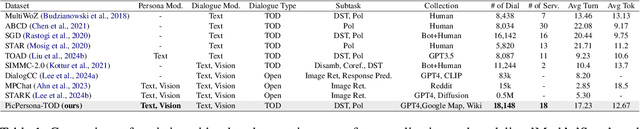
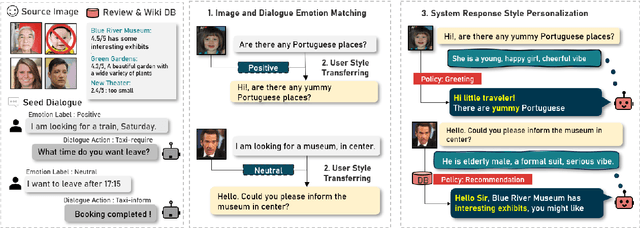

Task-Oriented Dialogue (TOD) systems are designed to fulfill user requests through natural language interactions, yet existing systems often produce generic, monotonic responses that lack individuality and fail to adapt to users' personal attributes. To address this, we introduce PicPersona-TOD, a novel dataset that incorporates user images as part of the persona, enabling personalized responses tailored to user-specific factors such as age or emotional context. This is facilitated by first impressions, dialogue policy-guided prompting, and the use of external knowledge to reduce hallucinations. Human evaluations confirm that our dataset enhances user experience, with personalized responses contributing to a more engaging interaction. Additionally, we introduce a new NLG model, Pictor, which not only personalizes responses, but also demonstrates robust performance across unseen domains https://github.com/JihyunLee1/PicPersona.
Mirror: Multimodal Cognitive Reframing Therapy for Rolling with Resistance
Apr 16, 2025
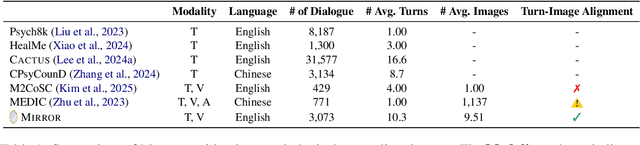
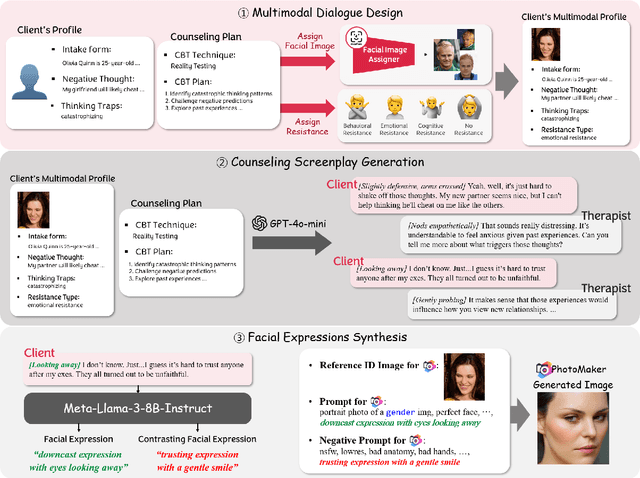
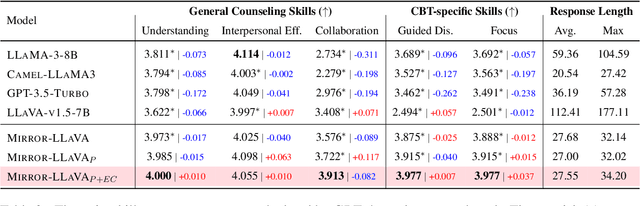
Recent studies have explored the use of large language models (LLMs) in psychotherapy; however, text-based cognitive behavioral therapy (CBT) models often struggle with client resistance, which can weaken therapeutic alliance. To address this, we propose a multimodal approach that incorporates nonverbal cues, allowing the AI therapist to better align its responses with the client's negative emotional state. Specifically, we introduce a new synthetic dataset, Multimodal Interactive Rolling with Resistance (Mirror), which is a novel synthetic dataset that pairs client statements with corresponding facial images. Using this dataset, we train baseline Vision-Language Models (VLMs) that can analyze facial cues, infer emotions, and generate empathetic responses to effectively manage resistance. They are then evaluated in terms of both the therapist's counseling skills and the strength of the therapeutic alliance in the presence of client resistance. Our results demonstrate that Mirror significantly enhances the AI therapist's ability to handle resistance, which outperforms existing text-based CBT approaches.
Revisiting Early Detection of Sexual Predators via Turn-level Optimization
Mar 09, 2025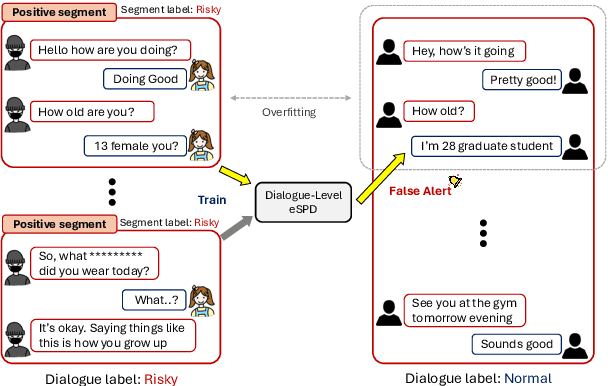



Online grooming is a severe social threat where sexual predators gradually entrap child victims with subtle and gradual manipulation. Therefore, timely intervention for online grooming is critical for proactive protection. However, previous methods fail to determine the optimal intervention points (i.e., jump to conclusions) as they rely on chat-level risk labels by causing weak supervision of risky utterances. For timely detection, we propose speed control reinforcement learning (SCoRL) (The code and supplementary materials are available at https://github.com/jinmyeongAN/SCoRL), incorporating a practical strategy derived from luring communication theory (LCT). To capture the predator's turn-level entrapment, we use a turn-level risk label based on the LCT. Then, we design a novel speed control reward function that balances the trade-off between speed and accuracy based on turn-level risk label; thus, SCoRL can identify the optimal intervention moment. In addition, we introduce a turn-level metric for precise evaluation, identifying limitations in previously used chat-level metrics. Experimental results show that SCoRL effectively preempted online grooming, offering a more proactive and timely solution. Further analysis reveals that our method enhances performance while intuitively identifying optimal early intervention points.