 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLM Behavior in Multi-Target Cross-Lingual Summarization
May 31, 2026Multi-target cross-lingual text summarization (MTXLS), which summarizes a source document into multiple target languages, is increasingly important as users consume content in diverse languages, but remains underexplored. To address this gap, we introduce multi-target cross-lingual element-aware (MEA), a new MTXLS benchmark covering 24 target languages. We benchmark end-to-end and pipeline approaches across various LLMs and show that MTXLS performance still substantially lags behind English monolingual summarization. To better understand MTXLS in LLMs, we propose a layer-wise analysis framework for investigating how LLMs internally perform MTXLS. Our analyses suggest that translation and summarization behaviors emerge jointly within later layers rather than as distinctly decomposed stages. Most task-relevant processing occurs within these layers, and errors also tend to arise at similar depths. Motivated by these findings, we introduce an inference-time activation steering method that leverages hidden representations from English summarization to guide MTXLS generation. Experiments show that our method consistently improves MTXLS quality across target languages.
Behavior-Aware Item Modeling via Dynamic Procedural Solution Representations for Knowledge Tracing
Apr 09, 2026Knowledge Tracing (KT) aims to predict learners' future performance from past interactions. While recent KT approaches have improved via learning item representations aligned with Knowledge Components, they overlook the procedural dynamics of problem solving. We propose Behavior-Aware Item Modeling (BAIM), a framework that enriches item representations by integrating dynamic procedural solution information. BAIM leverages a reasoning language model to decompose each item's solution into four problem-solving stages (i.e., understand, plan, carry out, and look back), pedagogically grounded in Polya's framework. Specifically, it derives stage-level representations from per-stage embedding trajectories, capturing latent signals beyond surface features. To reflect learner heterogeneity, BAIM adaptively routes these stage-wise representations, introducing a context-conditioned mechanism within a KT backbone, allowing different procedural stages to be emphasized for different learners. Experiments on XES3G5M and NIPS34 show that BAIM consistently outperforms strong pretraining-based baselines, achieving particularly large gains under repeated learner interactions.
GuRE:Generative Query REwriter for Legal Passage Retrieval
May 19, 2025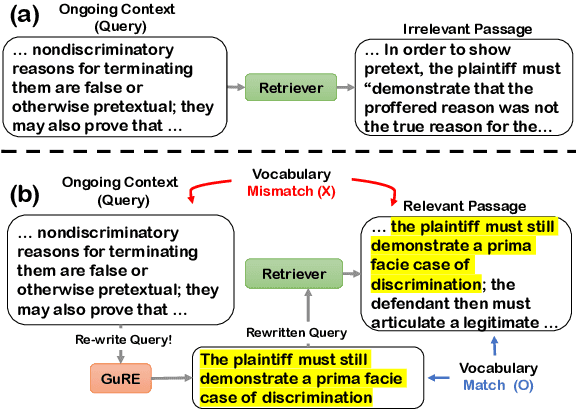
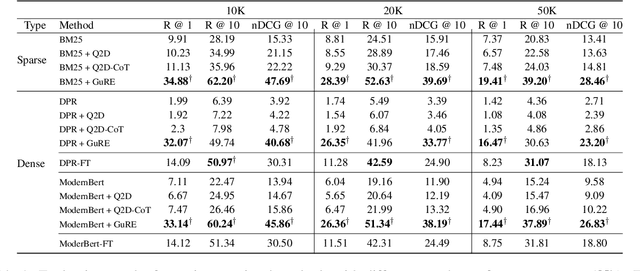
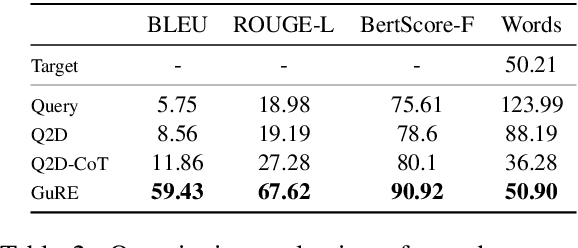

Legal Passage Retrieval (LPR) systems are crucial as they help practitioners save time when drafting legal arguments. However, it remains an underexplored avenue. One primary reason is the significant vocabulary mismatch between the query and the target passage. To address this, we propose a simple yet effective method, the Generative query REwriter (GuRE). We leverage the generative capabilities of Large Language Models (LLMs) by training the LLM for query rewriting. "Rewritten queries" help retrievers to retrieve target passages by mitigating vocabulary mismatch. Experimental results show that GuRE significantly improves performance in a retriever-agnostic manner, outperforming all baseline methods. Further analysis reveals that different training objectives lead to distinct retrieval behaviors, making GuRE more suitable than direct retriever fine-tuning for real-world applications. Codes are avaiable at github.com/daehuikim/GuRE.
Revisiting Early Detection of Sexual Predators via Turn-level Optimization
Mar 09, 2025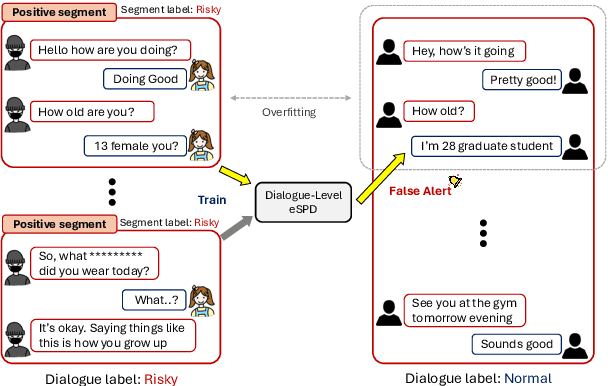



Online grooming is a severe social threat where sexual predators gradually entrap child victims with subtle and gradual manipulation. Therefore, timely intervention for online grooming is critical for proactive protection. However, previous methods fail to determine the optimal intervention points (i.e., jump to conclusions) as they rely on chat-level risk labels by causing weak supervision of risky utterances. For timely detection, we propose speed control reinforcement learning (SCoRL) (The code and supplementary materials are available at https://github.com/jinmyeongAN/SCoRL), incorporating a practical strategy derived from luring communication theory (LCT). To capture the predator's turn-level entrapment, we use a turn-level risk label based on the LCT. Then, we design a novel speed control reward function that balances the trade-off between speed and accuracy based on turn-level risk label; thus, SCoRL can identify the optimal intervention moment. In addition, we introduce a turn-level metric for precise evaluation, identifying limitations in previously used chat-level metrics. Experimental results show that SCoRL effectively preempted online grooming, offering a more proactive and timely solution. Further analysis reveals that our method enhances performance while intuitively identifying optimal early intervention points.
Teach-to-Reason with Scoring: Self-Explainable Rationale-Driven Multi-Trait Essay Scoring
Feb 28, 2025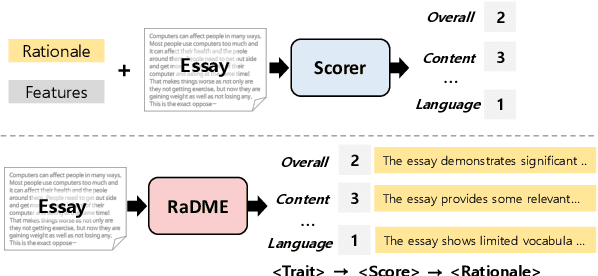



Multi-trait automated essay scoring (AES) systems provide a fine-grained evaluation of an essay's diverse aspects. While they excel in scoring, prior systems fail to explain why specific trait scores are assigned. This lack of transparency leaves instructors and learners unconvinced of the AES outputs, hindering their practical use. To address this, we propose a self-explainable Rationale-Driven Multi-trait automated Essay scoring (RaDME) framework. RaDME leverages the reasoning capabilities of large language models (LLMs) by distilling them into a smaller yet effective scorer. This more manageable student model is optimized to sequentially generate a trait score followed by the corresponding rationale, thereby inherently learning to select a more justifiable score by considering the subsequent rationale during training. Our findings indicate that while LLMs underperform in direct AES tasks, they excel in rationale generation when provided with precise numerical scores. Thus, RaDME integrates the superior reasoning capacities of LLMs into the robust scoring accuracy of an optimized smaller model. Extensive experiments demonstrate that RaDME achieves both accurate and adequate reasoning while supporting high-quality multi-trait scoring, significantly enhancing the transparency of AES.
Towards Prompt Generalization: Grammar-aware Cross-Prompt Automated Essay Scoring
Feb 12, 2025



In automated essay scoring (AES), recent efforts have shifted toward cross-prompt settings that score essays on unseen prompts for practical applicability. However, prior methods trained with essay-score pairs of specific prompts pose challenges in obtaining prompt-generalized essay representation. In this work, we propose a grammar-aware cross-prompt trait scoring (GAPS), which internally captures prompt-independent syntactic aspects to learn generic essay representation. We acquire grammatical error-corrected information in essays via the grammar error correction technique and design the AES model to seamlessly integrate such information. By internally referring to both the corrected and the original essays, the model can focus on generic features during training. Empirical experiments validate our method's generalizability, showing remarkable improvements in prompt-independent and grammar-related traits. Furthermore, GAPS achieves notable QWK gains in the most challenging cross-prompt scenario, highlighting its strength in evaluating unseen prompts.
Multi-Facet Blending for Faceted Query-by-Example Retrieval
Dec 02, 2024With the growing demand to fit fine-grained user intents, faceted query-by-example (QBE), which retrieves similar documents conditioned on specific facets, has gained recent attention. However, prior approaches mainly depend on document-level comparisons using basic indicators like citations due to the lack of facet-level relevance datasets; yet, this limits their use to citation-based domains and fails to capture the intricacies of facet constraints. In this paper, we propose a multi-facet blending (FaBle) augmentation method, which exploits modularity by decomposing and recomposing to explicitly synthesize facet-specific training sets. We automatically decompose documents into facet units and generate (ir)relevant pairs by leveraging LLMs' intrinsic distinguishing capabilities; then, dynamically recomposing the units leads to facet-wise relevance-informed document pairs. Our modularization eliminates the need for pre-defined facet knowledge or labels. Further, to prove the FaBle's efficacy in a new domain beyond citation-based scientific paper retrieval, we release a benchmark dataset for educational exam item QBE. FaBle augmentation on 1K documents remarkably assists training in obtaining facet conditional embeddings.
Guide-to-Explain for Controllable Summarization
Nov 19, 2024



Recently, large language models (LLMs) have demonstrated remarkable performance in abstractive summarization tasks. However, controllable summarization with LLMs remains underexplored, limiting their ability to generate summaries that align with specific user preferences. In this paper, we first investigate the capability of LLMs to control diverse attributes, revealing that they encounter greater challenges with numerical attributes, such as length and extractiveness, compared to linguistic attributes. To address this challenge, we propose a guide-to-explain framework (GTE) for controllable summarization. Our GTE framework enables the model to identify misaligned attributes in the initial draft and guides it in explaining errors in the previous output. Based on this reflection, the model generates a well-adjusted summary. As a result, by allowing the model to reflect on its misalignment, we generate summaries that satisfy the desired attributes in surprisingly fewer iterations than other iterative methods solely using LLMs.
Autoregressive Multi-trait Essay Scoring via Reinforcement Learning with Scoring-aware Multiple Rewards
Sep 26, 2024Recent advances in automated essay scoring (AES) have shifted towards evaluating multiple traits to provide enriched feedback. Like typical AES systems, multi-trait AES employs the quadratic weighted kappa (QWK) to measure agreement with human raters, aligning closely with the rating schema; however, its non-differentiable nature prevents its direct use in neural network training. In this paper, we propose Scoring-aware Multi-reward Reinforcement Learning (SaMRL), which integrates actual evaluation schemes into the training process by designing QWK-based rewards with a mean-squared error penalty for multi-trait AES. Existing reinforcement learning (RL) applications in AES are limited to classification models despite associated performance degradation, as RL requires probability distributions; instead, we adopt an autoregressive score generation framework to leverage token generation probabilities for robust multi-trait score predictions. Empirical analyses demonstrate that SaMRL facilitates model training, notably enhancing scoring of previously inferior prompts.
Ontology-Free General-Domain Knowledge Graph-to-Text Generation Dataset Synthesis using Large Language Model
Sep 11, 2024



Knowledge Graph-to-Text (G2T) generation involves verbalizing structured knowledge graphs into natural language text. Recent advancements in Pretrained Language Models (PLMs) have improved G2T performance, but their effectiveness depends on datasets with precise graph-text alignment. However, the scarcity of high-quality, general-domain G2T generation datasets restricts progress in the general-domain G2T generation research. To address this issue, we introduce Wikipedia Ontology-Free Graph-text dataset (WikiOFGraph), a new large-scale G2T dataset generated using a novel method that leverages Large Language Model (LLM) and Data-QuestEval. Our new dataset, which contains 5.85M general-domain graph-text pairs, offers high graph-text consistency without relying on external ontologies. Experimental results demonstrate that PLM fine-tuned on WikiOFGraph outperforms those trained on other datasets across various evaluation metrics. Our method proves to be a scalable and effective solution for generating high-quality G2T data, significantly advancing the field of G2T generation.