 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2Scratch: An Executable Benchmark and Evaluation for Block-Based Programming
Jun 20, 2026Block-based programming environments such as Scratch are widely used in early programming education, yet natural-language-to-code (NL2Code) research has focused primarily on text-based languages. Scratch programs are event-driven, visually compositional, and distributed across concurrent scripts, making conventional NL2Code assumptions and evaluation insufficient. We introduce NL2Scratch, an executable benchmark for natural-language-to-Scratch generation comprising 311,648 parser-valid NL--program pairs, whose program side is extracted from real Scratch projects and paired with semantically aligned NL descriptions. For reliable evaluation beyond surface overlap, we propose Semantic Alignment Consistency (SAC), an interpretable slot-level metric for measuring semantic agreement between descriptions and programs. With SAC, we construct a semantically validated pool of 23,594 examples, and a slot-balanced 800 diagnostic benchmark. Experiments across instruction-tuned and fine-tuned LLMs reveal a notable gap between lexical similarity and semantic alignment: models achieving token-level F1 above 0.93 often fail to attain perfect SAC, particularly on longer examples. Errors concentrate on operational slots like actions, conditions, and numeric arguments, exposing failure modes largely invisible under conventional metrics.
Segment-level Tree Search for Long Meeting Document Summarization
Jun 07, 2026Meeting documents are challenging to summarize due to their length and complex conversational structure. Existing approaches typically adopt multi-stage pipelines that extract information prior to summarization; however, these approaches often suffer from cumulative error propagation without intermediate validation, a limitation further amplified by short and low-quality reference summaries. We propose segment-level summarization via Monte Carlo Tree Search (S3), a training-free framework that constructs a final summary by composing segment-level summary candidates. S3 partitions a long document into segments and generates multiple summary candidates per segment, forming nodes of a search tree. The best-scoring combination is selected via self-reward-guided tree search and refined into the final output. Despite using a 7B model, S3 achieves performance comparable to larger 72B models while producing length-appropriate summaries.
Benchmarking and Enhancing Text-to-Image Models for Generating Visual Representations in Early Arithmetic Education
May 29, 2026AI systems are increasingly used to support educational content creation, yet it remains unclear whether they can generate outputs that faithfully represent the pedagogical concepts they are intended to teach. Thus, we introduce equation-to-visual generation, a task that, in contrast to conventional image generation, requires producing pedagogically meaningful visuals from arithmetic equations while precisely preserving their numerical and relational structure. Informed by interviews with teachers and an analysis of educational materials, we construct E2V-Bench, a benchmark spanning four pedagogically grounded visual types, along with automatic metrics for evaluating visual correctness. Our evaluation reveals that recent text-to-image (T2I) models frequently fail on this task, with errors dominated by incorrect object counts and broken relational structure. Building on this, we explore benchmark-guided enhancement strategies. These strategies improve representative models, while the remaining gap calls for stronger numerical and relational grounding in future T2I models.
Simulating Students or Sycophantic Problem Solving? On Misconception Faithfulness of LLM Simulators
May 12, 2026Large language models (LLMs) can fluently generate student-like responses, making them attractive as simulated students for training and evaluating AI tutors and human educators. Yet such simulators are typically evaluated by output similarity to real students, not by whether they behave like students with coherent misconceptions during interaction. We introduce a controlled framework for evaluating misconception faithfulness, whether a simulator maintains a misconception-driven belief state and updates selectively when feedback addresses the underlying misconception. Central to our framework is a misconception-contrastive feedback protocol that compares targeted feedback against two controls: misaligned feedback (targeting a different but plausible misconception) and generic feedback (only identifying answer is wrong). We propose Selective Flip Score (SFS), which quantifies how much more often a simulator flips its answer under targeted feedback than under contrastive controls. Across seven LLMs (4B-120B), multiple datasets, and prompting strategies, simulators exhibit near-zero SFS, correcting their answers at similarly high rates regardless of feedback relevance. Further analyses reveal a sycophantic failure mode: models behave less like students with misconceptions but more like problem-solvers who treat any corrective signal as a cue to abandon the simulated belief and re-solve from internal knowledge. To address this, we develop a post-training pipeline spanning supervised fine-tuning (SFT), preference optimization, and reinforcement learning (RL) with an SFS-aligned reward; SFT yields notable gains up to +0.56, and SFS-aligned RL provides more consistent improvements than preference optimization. Our results establish misconception faithfulness as a challenging yet trainable property, motivating a shift from static output matching toward interactive, belief-aware student modeling.
Behavior-Aware Item Modeling via Dynamic Procedural Solution Representations for Knowledge Tracing
Apr 09, 2026Knowledge Tracing (KT) aims to predict learners' future performance from past interactions. While recent KT approaches have improved via learning item representations aligned with Knowledge Components, they overlook the procedural dynamics of problem solving. We propose Behavior-Aware Item Modeling (BAIM), a framework that enriches item representations by integrating dynamic procedural solution information. BAIM leverages a reasoning language model to decompose each item's solution into four problem-solving stages (i.e., understand, plan, carry out, and look back), pedagogically grounded in Polya's framework. Specifically, it derives stage-level representations from per-stage embedding trajectories, capturing latent signals beyond surface features. To reflect learner heterogeneity, BAIM adaptively routes these stage-wise representations, introducing a context-conditioned mechanism within a KT backbone, allowing different procedural stages to be emphasized for different learners. Experiments on XES3G5M and NIPS34 show that BAIM consistently outperforms strong pretraining-based baselines, achieving particularly large gains under repeated learner interactions.
What Defines Good Reasoning in LLMs? Dissecting Reasoning Steps with Multi-Aspect Evaluation
Oct 23, 2025
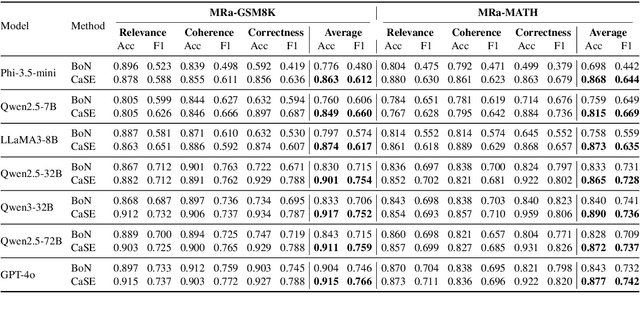
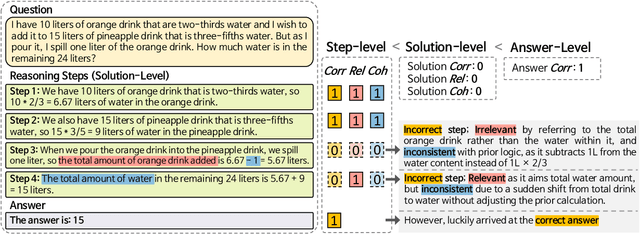
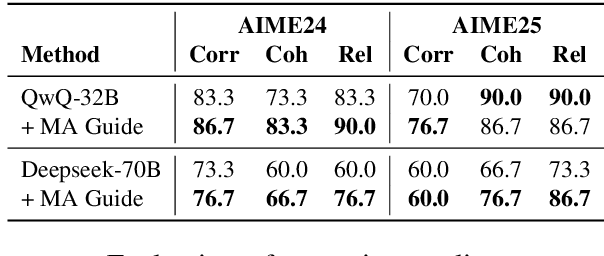
Evaluating large language models (LLMs) on final-answer correctness is the dominant paradigm. This approach, however, provides a coarse signal for model improvement and overlooks the quality of the underlying reasoning process. We argue that a more granular evaluation of reasoning offers a more effective path to building robust models. We decompose reasoning quality into two dimensions: relevance and coherence. Relevance measures if a step is grounded in the problem; coherence measures if it follows logically from prior steps. To measure these aspects reliably, we introduce causal stepwise evaluation (CaSE). This method assesses each reasoning step using only its preceding context, which avoids hindsight bias. We validate CaSE against human judgments on our new expert-annotated benchmarks, MRa-GSM8K and MRa-MATH. More importantly, we show that curating training data with CaSE-evaluated relevance and coherence directly improves final task performance. Our work provides a scalable framework for analyzing, debugging, and improving LLM reasoning, demonstrating the practical value of moving beyond validity checks.
Revisiting Early Detection of Sexual Predators via Turn-level Optimization
Mar 09, 2025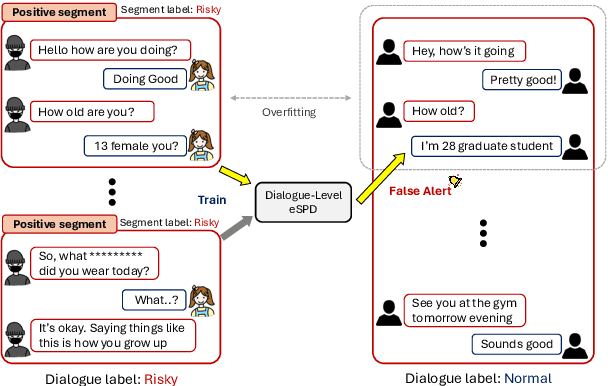



Online grooming is a severe social threat where sexual predators gradually entrap child victims with subtle and gradual manipulation. Therefore, timely intervention for online grooming is critical for proactive protection. However, previous methods fail to determine the optimal intervention points (i.e., jump to conclusions) as they rely on chat-level risk labels by causing weak supervision of risky utterances. For timely detection, we propose speed control reinforcement learning (SCoRL) (The code and supplementary materials are available at https://github.com/jinmyeongAN/SCoRL), incorporating a practical strategy derived from luring communication theory (LCT). To capture the predator's turn-level entrapment, we use a turn-level risk label based on the LCT. Then, we design a novel speed control reward function that balances the trade-off between speed and accuracy based on turn-level risk label; thus, SCoRL can identify the optimal intervention moment. In addition, we introduce a turn-level metric for precise evaluation, identifying limitations in previously used chat-level metrics. Experimental results show that SCoRL effectively preempted online grooming, offering a more proactive and timely solution. Further analysis reveals that our method enhances performance while intuitively identifying optimal early intervention points.
Teach-to-Reason with Scoring: Self-Explainable Rationale-Driven Multi-Trait Essay Scoring
Feb 28, 2025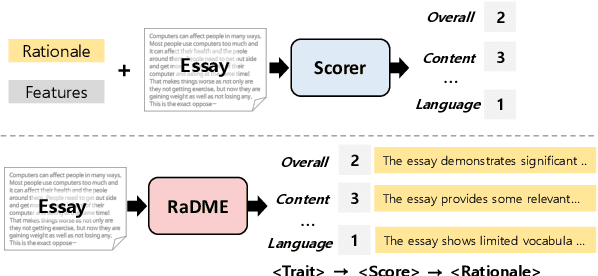



Multi-trait automated essay scoring (AES) systems provide a fine-grained evaluation of an essay's diverse aspects. While they excel in scoring, prior systems fail to explain why specific trait scores are assigned. This lack of transparency leaves instructors and learners unconvinced of the AES outputs, hindering their practical use. To address this, we propose a self-explainable Rationale-Driven Multi-trait automated Essay scoring (RaDME) framework. RaDME leverages the reasoning capabilities of large language models (LLMs) by distilling them into a smaller yet effective scorer. This more manageable student model is optimized to sequentially generate a trait score followed by the corresponding rationale, thereby inherently learning to select a more justifiable score by considering the subsequent rationale during training. Our findings indicate that while LLMs underperform in direct AES tasks, they excel in rationale generation when provided with precise numerical scores. Thus, RaDME integrates the superior reasoning capacities of LLMs into the robust scoring accuracy of an optimized smaller model. Extensive experiments demonstrate that RaDME achieves both accurate and adequate reasoning while supporting high-quality multi-trait scoring, significantly enhancing the transparency of AES.
Towards Prompt Generalization: Grammar-aware Cross-Prompt Automated Essay Scoring
Feb 12, 2025



In automated essay scoring (AES), recent efforts have shifted toward cross-prompt settings that score essays on unseen prompts for practical applicability. However, prior methods trained with essay-score pairs of specific prompts pose challenges in obtaining prompt-generalized essay representation. In this work, we propose a grammar-aware cross-prompt trait scoring (GAPS), which internally captures prompt-independent syntactic aspects to learn generic essay representation. We acquire grammatical error-corrected information in essays via the grammar error correction technique and design the AES model to seamlessly integrate such information. By internally referring to both the corrected and the original essays, the model can focus on generic features during training. Empirical experiments validate our method's generalizability, showing remarkable improvements in prompt-independent and grammar-related traits. Furthermore, GAPS achieves notable QWK gains in the most challenging cross-prompt scenario, highlighting its strength in evaluating unseen prompts.
Multimodal Cognitive Reframing Therapy via Multi-hop Psychotherapeutic Reasoning
Feb 08, 2025Previous research has revealed the potential of large language models (LLMs) to support cognitive reframing therapy; however, their focus was primarily on text-based methods, often overlooking the importance of non-verbal evidence crucial in real-life therapy. To alleviate this gap, we extend the textual cognitive reframing to multimodality, incorporating visual clues. Specifically, we present a new dataset called Multi Modal-Cognitive Support Conversation (M2CoSC), which pairs each GPT-4-generated dialogue with an image that reflects the virtual client's facial expressions. To better mirror real psychotherapy, where facial expressions lead to interpreting implicit emotional evidence, we propose a multi-hop psychotherapeutic reasoning approach that explicitly identifies and incorporates subtle evidence. Our comprehensive experiments with both LLMs and vision-language models (VLMs) demonstrate that the VLMs' performance as psychotherapists is significantly improved with the M2CoSC dataset. Furthermore, the multi-hop psychotherapeutic reasoning method enables VLMs to provide more thoughtful and empathetic suggestions, outperforming standard prompting methods.