 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
PicPersona-TOD : A Dataset for Personalizing Utterance Style in Task-Oriented Dialogue with Image Persona
Apr 24, 2025
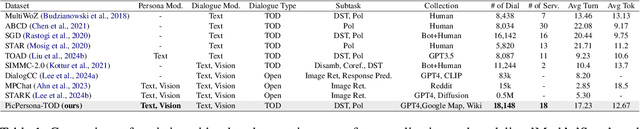

Task-Oriented Dialogue (TOD) systems are designed to fulfill user requests through natural language interactions, yet existing systems often produce generic, monotonic responses that lack individuality and fail to adapt to users' personal attributes. To address this, we introduce PicPersona-TOD, a novel dataset that incorporates user images as part of the persona, enabling personalized responses tailored to user-specific factors such as age or emotional context. This is facilitated by first impressions, dialogue policy-guided prompting, and the use of external knowledge to reduce hallucinations. Human evaluations confirm that our dataset enhances user experience, with personalized responses contributing to a more engaging interaction. Additionally, we introduce a new NLG model, Pictor, which not only personalizes responses, but also demonstrates robust performance across unseen domains https://github.com/JihyunLee1/PicPersona.
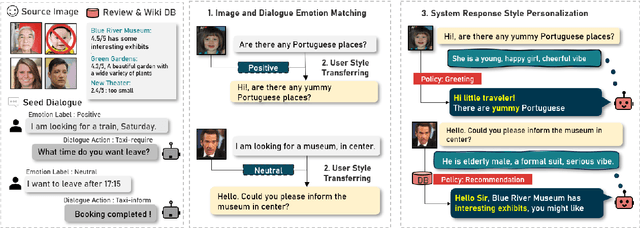
Multi-aspect Depression Severity Assessment via Inductive Dialogue System
Oct 29, 2024

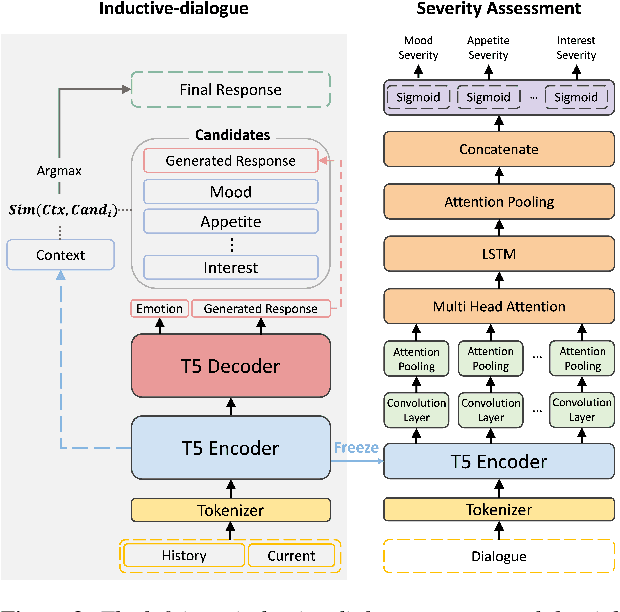
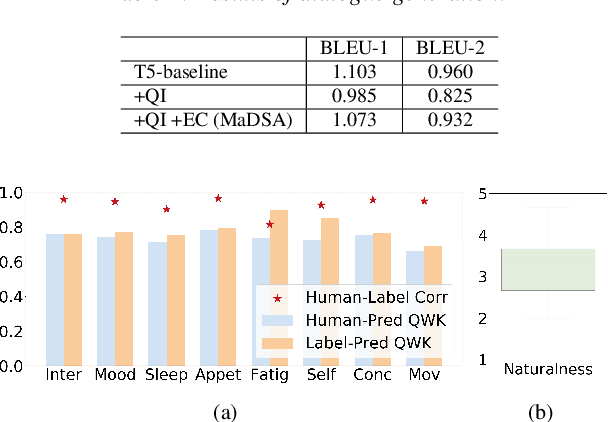
With the advancement of chatbots and the growing demand for automatic depression detection, identifying depression in patient conversations has gained more attention. However, prior methods often assess depression in a binary way or only a single score without diverse feedback and lack focus on enhancing dialogue responses. In this paper, we present a novel task of multi-aspect depression severity assessment via an inductive dialogue system (MaDSA), evaluating a patient's depression level on multiple criteria by incorporating an assessment-aided response generation. Further, we propose a foundational system for MaDSA, which induces psychological dialogue responses with an auxiliary emotion classification task within a hierarchical severity assessment structure. We synthesize the conversational dataset annotated with eight aspects of depression severity alongside emotion labels, proven robust via human evaluations. Experimental results show potential for our preliminary work on MaDSA.
DiagESC: Dialogue Synthesis for Integrating Depression Diagnosis into Emotional Support Conversation
Aug 12, 2024Dialogue systems for mental health care aim to provide appropriate support to individuals experiencing mental distress. While extensive research has been conducted to deliver adequate emotional support, existing studies cannot identify individuals who require professional medical intervention and cannot offer suitable guidance. We introduce the Diagnostic Emotional Support Conversation task for an advanced mental health management system. We develop the DESC dataset to assess depression symptoms while maintaining user experience by utilizing task-specific utterance generation prompts and a strict filtering algorithm. Evaluations by professional psychological counselors indicate that DESC has a superior ability to diagnose depression than existing data. Additionally, conversational quality evaluation reveals that DESC maintains fluent, consistent, and coherent dialogues.
DORIC : Domain Robust Fine-Tuning for Open Intent Clustering through Dependency Parsing
Mar 17, 2023We present our work on Track 2 in the Dialog System Technology Challenges 11 (DSTC11). DSTC11-Track2 aims to provide a benchmark for zero-shot, cross-domain, intent-set induction. In the absence of in-domain training dataset, robust utterance representation that can be used across domains is necessary to induce users' intentions. To achieve this, we leveraged a multi-domain dialogue dataset to fine-tune the language model and proposed extracting Verb-Object pairs to remove the artifacts of unnecessary information. Furthermore, we devised the method that generates each cluster's name for the explainability of clustered results. Our approach achieved 3rd place in the precision score and showed superior accuracy and normalized mutual information (NMI) score than the baseline model on various domain datasets.