 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpGuard: LLM Content Moderation in Specialized Domains
Mar 03, 2026With the growing deployment of large language models (LLMs) in real-world applications, establishing robust safety guardrails to moderate their inputs and outputs has become essential to ensure adherence to safety policies. Current guardrail models predominantly address general human-LLM interactions, rendering LLMs vulnerable to harmful and adversarial content within domain-specific contexts, particularly those rich in technical jargon and specialized concepts. To address this limitation, we introduce ExpGuard, a robust and specialized guardrail model designed to protect against harmful prompts and responses across financial, medical, and legal domains. In addition, we present ExpGuardMix, a meticulously curated dataset comprising 58,928 labeled prompts paired with corresponding refusal and compliant responses, from these specific sectors. This dataset is divided into two subsets: ExpGuardTrain, for model training, and ExpGuardTest, a high-quality test set annotated by domain experts to evaluate model robustness against technical and domain-specific content. Comprehensive evaluations conducted on ExpGuardTest and eight established public benchmarks reveal that ExpGuard delivers competitive performance across the board while demonstrating exceptional resilience to domain-specific adversarial attacks, surpassing state-of-the-art models such as WildGuard by up to 8.9% in prompt classification and 15.3% in response classification. To encourage further research and development, we open-source our code, data, and model, enabling adaptation to additional domains and supporting the creation of increasingly robust guardrail models.
BankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios
Feb 19, 2026Large language models (LLMs)-based chatbots are increasingly being adopted in the financial domain, particularly in digital banking, to handle customer inquiries about products such as deposits, savings, and loans. However, these models still exhibit low accuracy in core banking computations-including total payout estimation, comparison of products with varying interest rates, and interest calculation under early repayment conditions. Such tasks require multi-step numerical reasoning and contextual understanding of banking products, yet existing LLMs often make systematic errors-misinterpreting product types, applying conditions incorrectly, or failing basic calculations involving exponents and geometric progressions. However, such errors have rarely been captured by existing benchmarks. Mathematical datasets focus on fundamental math problems, whereas financial benchmarks primarily target financial documents, leaving everyday banking scenarios underexplored. To address this limitation, we propose BankMathBench, a domain-specific dataset that reflects realistic banking tasks. BankMathBench is organized in three levels of difficulty-basic, intermediate, and advanced-corresponding to single-product reasoning, multi-product comparison, and multi-condition scenarios, respectively. When trained on BankMathBench, open-source LLMs exhibited notable improvements in both formula generation and numerical reasoning accuracy, demonstrating the dataset's effectiveness in enhancing domain-specific reasoning. With tool-augmented fine-tuning, the models achieved average accuracy increases of 57.6%p (basic), 75.1%p (intermediate), and 62.9%p (advanced), representing significant gains over zero-shot baselines. These findings highlight BankMathBench as a reliable benchmark for evaluating and advancing LLMs' numerical reasoning in real-world banking scenarios.
FontAdapter: Instant Font Adaptation in Visual Text Generation
Jun 06, 2025

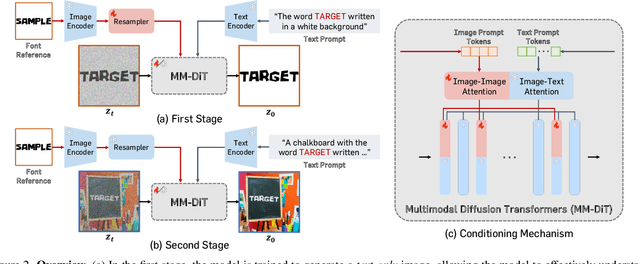
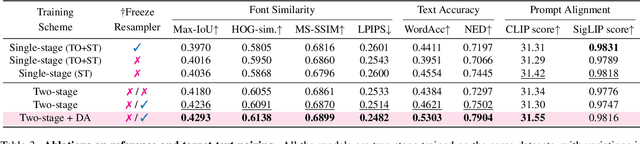
Text-to-image diffusion models have significantly improved the seamless integration of visual text into diverse image contexts. Recent approaches further improve control over font styles through fine-tuning with predefined font dictionaries. However, adapting unseen fonts outside the preset is computationally expensive, often requiring tens of minutes, making real-time customization impractical. In this paper, we present FontAdapter, a framework that enables visual text generation in unseen fonts within seconds, conditioned on a reference glyph image. To this end, we find that direct training on font datasets fails to capture nuanced font attributes, limiting generalization to new glyphs. To overcome this, we propose a two-stage curriculum learning approach: FontAdapter first learns to extract font attributes from isolated glyphs and then integrates these styles into diverse natural backgrounds. To support this two-stage training scheme, we construct synthetic datasets tailored to each stage, leveraging large-scale online fonts effectively. Experiments demonstrate that FontAdapter enables high-quality, robust font customization across unseen fonts without additional fine-tuning during inference. Furthermore, it supports visual text editing, font style blending, and cross-lingual font transfer, positioning FontAdapter as a versatile framework for font customization tasks.
A Smooth Sea Never Made a Skilled $\texttt{SAILOR}$: Robust Imitation via Learning to Search
Jun 05, 2025



The fundamental limitation of the behavioral cloning (BC) approach to imitation learning is that it only teaches an agent what the expert did at states the expert visited. This means that when a BC agent makes a mistake which takes them out of the support of the demonstrations, they often don't know how to recover from it. In this sense, BC is akin to giving the agent the fish -- giving them dense supervision across a narrow set of states -- rather than teaching them to fish: to be able to reason independently about achieving the expert's outcome even when faced with unseen situations at test-time. In response, we explore learning to search (L2S) from expert demonstrations, i.e. learning the components required to, at test time, plan to match expert outcomes, even after making a mistake. These include (1) a world model and (2) a reward model. We carefully ablate the set of algorithmic and design decisions required to combine these and other components for stable and sample/interaction-efficient learning of recovery behavior without additional human corrections. Across a dozen visual manipulation tasks from three benchmarks, our approach $\texttt{SAILOR}$ consistently out-performs state-of-the-art Diffusion Policies trained via BC on the same data. Furthermore, scaling up the amount of demonstrations used for BC by 5-10$\times$ still leaves a performance gap. We find that $\texttt{SAILOR}$ can identify nuanced failures and is robust to reward hacking. Our code is available at https://github.com/arnavkj1995/SAILOR .
Mirror: Multimodal Cognitive Reframing Therapy for Rolling with Resistance
Apr 16, 2025
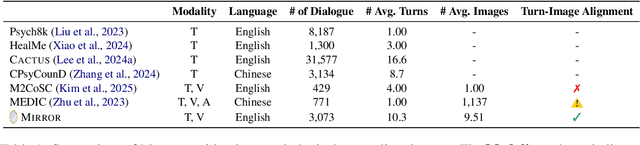
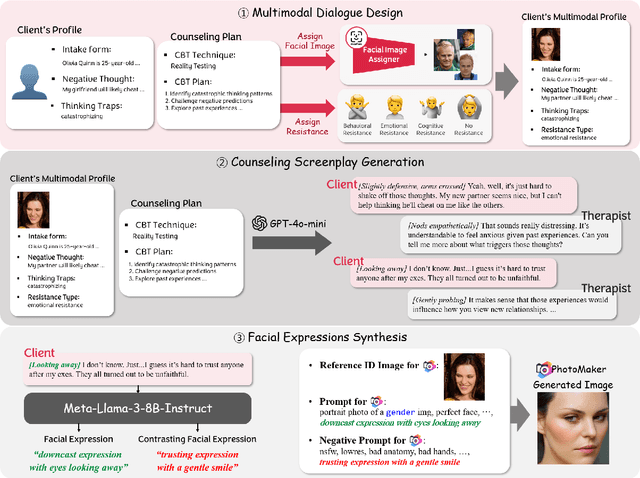
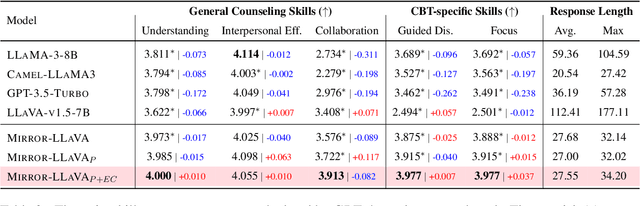
Recent studies have explored the use of large language models (LLMs) in psychotherapy; however, text-based cognitive behavioral therapy (CBT) models often struggle with client resistance, which can weaken therapeutic alliance. To address this, we propose a multimodal approach that incorporates nonverbal cues, allowing the AI therapist to better align its responses with the client's negative emotional state. Specifically, we introduce a new synthetic dataset, Multimodal Interactive Rolling with Resistance (Mirror), which is a novel synthetic dataset that pairs client statements with corresponding facial images. Using this dataset, we train baseline Vision-Language Models (VLMs) that can analyze facial cues, infer emotions, and generate empathetic responses to effectively manage resistance. They are then evaluated in terms of both the therapist's counseling skills and the strength of the therapeutic alliance in the presence of client resistance. Our results demonstrate that Mirror significantly enhances the AI therapist's ability to handle resistance, which outperforms existing text-based CBT approaches.
Tuning-Free Multi-Event Long Video Generation via Synchronized Coupled Sampling
Mar 11, 2025While recent advancements in text-to-video diffusion models enable high-quality short video generation from a single prompt, generating real-world long videos in a single pass remains challenging due to limited data and high computational costs. To address this, several works propose tuning-free approaches, i.e., extending existing models for long video generation, specifically using multiple prompts to allow for dynamic and controlled content changes. However, these methods primarily focus on ensuring smooth transitions between adjacent frames, often leading to content drift and a gradual loss of semantic coherence over longer sequences. To tackle such an issue, we propose Synchronized Coupled Sampling (SynCoS), a novel inference framework that synchronizes denoising paths across the entire video, ensuring long-range consistency across both adjacent and distant frames. Our approach combines two complementary sampling strategies: reverse and optimization-based sampling, which ensure seamless local transitions and enforce global coherence, respectively. However, directly alternating between these samplings misaligns denoising trajectories, disrupting prompt guidance and introducing unintended content changes as they operate independently. To resolve this, SynCoS synchronizes them through a grounded timestep and a fixed baseline noise, ensuring fully coupled sampling with aligned denoising paths. Extensive experiments show that SynCoS significantly improves multi-event long video generation, achieving smoother transitions and superior long-range coherence, outperforming previous approaches both quantitatively and qualitatively.
Multimodal Cognitive Reframing Therapy via Multi-hop Psychotherapeutic Reasoning
Feb 08, 2025Previous research has revealed the potential of large language models (LLMs) to support cognitive reframing therapy; however, their focus was primarily on text-based methods, often overlooking the importance of non-verbal evidence crucial in real-life therapy. To alleviate this gap, we extend the textual cognitive reframing to multimodality, incorporating visual clues. Specifically, we present a new dataset called Multi Modal-Cognitive Support Conversation (M2CoSC), which pairs each GPT-4-generated dialogue with an image that reflects the virtual client's facial expressions. To better mirror real psychotherapy, where facial expressions lead to interpreting implicit emotional evidence, we propose a multi-hop psychotherapeutic reasoning approach that explicitly identifies and incorporates subtle evidence. Our comprehensive experiments with both LLMs and vision-language models (VLMs) demonstrate that the VLMs' performance as psychotherapists is significantly improved with the M2CoSC dataset. Furthermore, the multi-hop psychotherapeutic reasoning method enables VLMs to provide more thoughtful and empathetic suggestions, outperforming standard prompting methods.
Dr. Strategy: Model-Based Generalist Agents with Strategic Dreaming
Feb 29, 2024



Model-based reinforcement learning (MBRL) has been a primary approach to ameliorating the sample efficiency issue as well as to make a generalist agent. However, there has not been much effort toward enhancing the strategy of dreaming itself. Therefore, it is a question whether and how an agent can "dream better" in a more structured and strategic way. In this paper, inspired by the observation from cognitive science suggesting that humans use a spatial divide-and-conquer strategy in planning, we propose a new MBRL agent, called Dr. Strategy, which is equipped with a novel Dreaming Strategy. The proposed agent realizes a version of divide-and-conquer-like strategy in dreaming. This is achieved by learning a set of latent landmarks and then utilizing these to learn a landmark-conditioned highway policy. With the highway policy, the agent can first learn in the dream to move to a landmark, and from there it tackles the exploration and achievement task in a more focused way. In experiments, we show that the proposed model outperforms prior pixel-based MBRL methods in various visually complex and partially observable navigation tasks. The source code will be available at https://github.com/ahn-ml/drstrategy
Collaborative Score Distillation for Consistent Visual Synthesis
Jul 04, 2023Generative priors of large-scale text-to-image diffusion models enable a wide range of new generation and editing applications on diverse visual modalities. However, when adapting these priors to complex visual modalities, often represented as multiple images (e.g., video), achieving consistency across a set of images is challenging. In this paper, we address this challenge with a novel method, Collaborative Score Distillation (CSD). CSD is based on the Stein Variational Gradient Descent (SVGD). Specifically, we propose to consider multiple samples as "particles" in the SVGD update and combine their score functions to distill generative priors over a set of images synchronously. Thus, CSD facilitates seamless integration of information across 2D images, leading to a consistent visual synthesis across multiple samples. We show the effectiveness of CSD in a variety of tasks, encompassing the visual editing of panorama images, videos, and 3D scenes. Our results underline the competency of CSD as a versatile method for enhancing inter-sample consistency, thereby broadening the applicability of text-to-image diffusion models.
Video Probabilistic Diffusion Models in Projected Latent Space
Feb 15, 2023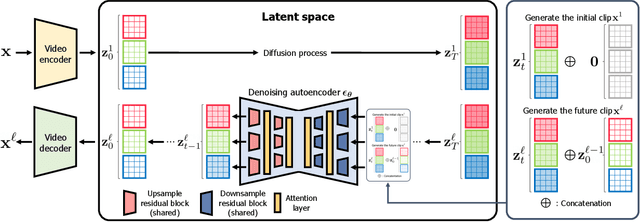
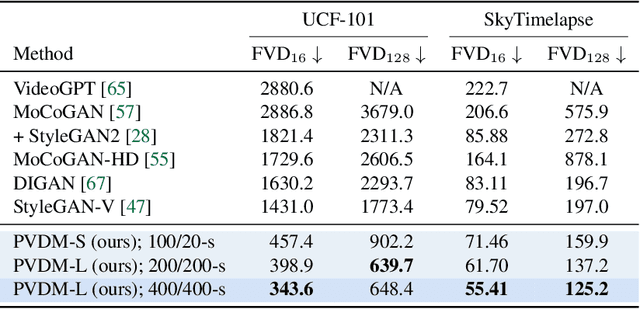
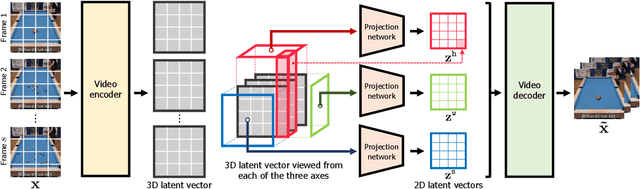

Despite the remarkable progress in deep generative models, synthesizing high-resolution and temporally coherent videos still remains a challenge due to their high-dimensionality and complex temporal dynamics along with large spatial variations. Recent works on diffusion models have shown their potential to solve this challenge, yet they suffer from severe computation- and memory-inefficiency that limit the scalability. To handle this issue, we propose a novel generative model for videos, coined projected latent video diffusion models (PVDM), a probabilistic diffusion model which learns a video distribution in a low-dimensional latent space and thus can be efficiently trained with high-resolution videos under limited resources. Specifically, PVDM is composed of two components: (a) an autoencoder that projects a given video as 2D-shaped latent vectors that factorize the complex cubic structure of video pixels and (b) a diffusion model architecture specialized for our new factorized latent space and the training/sampling procedure to synthesize videos of arbitrary length with a single model. Experiments on popular video generation datasets demonstrate the superiority of PVDM compared with previous video synthesis methods; e.g., PVDM obtains the FVD score of 639.7 on the UCF-101 long video (128 frames) generation benchmark, which improves 1773.4 of the prior state-of-the-art.