 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Visual State Tracking in Multimodal Video Understanding
Jun 02, 2026Understanding a video requires more than recognizing isolated moments, as humans continuously track entities, states, and events over time. This capacity for visual state tracking is fundamental to video understanding, yet remains underexplored in current evaluations of Multimodal Large Language Models (MLLMs). We introduce Visual STAte Tracking benchmark (VSTAT), a video-based benchmark designed to diagnose visual state tracking in MLLMs. VSTAT consists of 834 clips drawn from both synthetic and real-world videos, paired with 1,500 questions that cannot be answered from any single frame or short segment, requiring continuous perception and integration of events across the entire video stream. Despite their strong performance on existing video benchmarks, we find that state-of-the-art MLLMs perform far below humans and only modestly above answer-prior baselines. To analyze this gap, we compare MLLMs' thinking traces with the underlying video stream to understand why and when MLLMs fail on VSTAT. We find that MLLMs reason and track correctly in text, but fail at visually perceiving the events they need to track. Finally, our preliminary evaluation suggests that recent agentic approaches, including MLLM-based video agents and coding agents, do not readily resolve these failures, still falling short on VSTAT.
World Action Models are Zero-shot Policies
Feb 17, 2026State-of-the-art Vision-Language-Action (VLA) models excel at semantic generalization but struggle to generalize to unseen physical motions in novel environments. We introduce DreamZero, a World Action Model (WAM) built upon a pretrained video diffusion backbone. Unlike VLAs, WAMs learn physical dynamics by predicting future world states and actions, using video as a dense representation of how the world evolves. By jointly modeling video and action, DreamZero learns diverse skills effectively from heterogeneous robot data without relying on repetitive demonstrations. This results in over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments. Crucially, through model and system optimizations, we enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. Finally, we demonstrate two forms of cross-embodiment transfer: video-only demonstrations from other robots or humans yield a relative improvement of over 42% on unseen task performance with just 10-20 minutes of data. More surprisingly, DreamZero enables few-shot embodiment adaptation, transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Feb 06, 2026Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.
ContextVLA: Vision-Language-Action Model with Amortized Multi-Frame Context
Oct 05, 2025Leveraging temporal context is crucial for success in partially observable robotic tasks. However, prior work in behavior cloning has demonstrated inconsistent performance gains when using multi-frame observations. In this paper, we introduce ContextVLA, a policy model that robustly improves robotic task performance by effectively leveraging multi-frame observations. Our approach is motivated by the key observation that Vision-Language-Action models (VLA), i.e., policy models built upon a Vision-Language Model (VLM), more effectively utilize multi-frame observations for action generation. This suggests that VLMs' inherent temporal understanding capability enables them to extract more meaningful context from multi-frame observations. However, the high dimensionality of video inputs introduces significant computational overhead, making VLA training and inference inefficient. To address this, ContextVLA compresses past observations into a single context token, allowing the policy to efficiently leverage temporal context for action generation. Our experiments show that ContextVLA consistently improves over single-frame VLAs and achieves the benefits of full multi-frame training but with reduced training and inference times.
Enhancing Motion Dynamics of Image-to-Video Models via Adaptive Low-Pass Guidance
Jun 10, 2025



Recent text-to-video (T2V) models have demonstrated strong capabilities in producing high-quality, dynamic videos. To improve the visual controllability, recent works have considered fine-tuning pre-trained T2V models to support image-to-video (I2V) generation. However, such adaptation frequently suppresses motion dynamics of generated outputs, resulting in more static videos compared to their T2V counterparts. In this work, we analyze this phenomenon and identify that it stems from the premature exposure to high-frequency details in the input image, which biases the sampling process toward a shortcut trajectory that overfits to the static appearance of the reference image. To address this, we propose adaptive low-pass guidance (ALG), a simple fix to the I2V model sampling procedure to generate more dynamic videos without compromising per-frame image quality. Specifically, ALG adaptively modulates the frequency content of the conditioning image by applying low-pass filtering at the early stage of denoising. Extensive experiments demonstrate that ALG significantly improves the temporal dynamics of generated videos, while preserving image fidelity and text alignment. Especially, under VBench-I2V test suite, ALG achieves an average improvement of 36% in dynamic degree without a significant drop in video quality or image fidelity.
Learning Flexible Forward Trajectories for Masked Molecular Diffusion
May 22, 2025Masked diffusion models (MDMs) have achieved notable progress in modeling discrete data, while their potential in molecular generation remains underexplored. In this work, we explore their potential and introduce the surprising result that naively applying standards MDMs severely degrades the performance. We identify the critical cause of this issue as a state-clashing problem-where the forward diffusion of distinct molecules collapse into a common state, resulting in a mixture of reconstruction targets that cannot be learned using typical reverse diffusion process with unimodal predictions. To mitigate this, we propose Masked Element-wise Learnable Diffusion (MELD) that orchestrates per-element corruption trajectories to avoid collision between distinct molecular graphs. This is achieved through a parameterized noise scheduling network that assigns distinct corruption rates to individual graph elements, i.e., atoms and bonds. Extensive experiments on diverse molecular benchmarks reveal that MELD markedly enhances overall generation quality compared to element-agnostic noise scheduling, increasing the chemical validity of vanilla MDMs on ZINC250K from 15% to 93%, Furthermore, it achieves state-of-the-art property alignment in conditional generation tasks.
MALT Diffusion: Memory-Augmented Latent Transformers for Any-Length Video Generation
Feb 18, 2025Diffusion models are successful for synthesizing high-quality videos but are limited to generating short clips (e.g., 2-10 seconds). Synthesizing sustained footage (e.g. over minutes) still remains an open research question. In this paper, we propose MALT Diffusion (using Memory-Augmented Latent Transformers), a new diffusion model specialized for long video generation. MALT Diffusion (or just MALT) handles long videos by subdividing them into short segments and doing segment-level autoregressive generation. To achieve this, we first propose recurrent attention layers that encode multiple segments into a compact memory latent vector; by maintaining this memory vector over time, MALT is able to condition on it and continuously generate new footage based on a long temporal context. We also present several training techniques that enable the model to generate frames over a long horizon with consistent quality and minimal degradation. We validate the effectiveness of MALT through experiments on long video benchmarks. We first perform extensive analysis of MALT in long-contextual understanding capability and stability using popular long video benchmarks. For example, MALT achieves an FVD score of 220.4 on 128-frame video generation on UCF-101, outperforming the previous state-of-the-art of 648.4. Finally, we explore MALT's capabilities in a text-to-video generation setting and show that it can produce long videos compared with recent techniques for long text-to-video generation.
Efficient Long Video Tokenization via Coordinate-based Patch Reconstruction
Nov 26, 2024



Efficient tokenization of videos remains a challenge in training vision models that can process long videos. One promising direction is to develop a tokenizer that can encode long video clips, as it would enable the tokenizer to leverage the temporal coherence of videos better for tokenization. However, training existing tokenizers on long videos often incurs a huge training cost as they are trained to reconstruct all the frames at once. In this paper, we introduce CoordTok, a video tokenizer that learns a mapping from coordinate-based representations to the corresponding patches of input videos, inspired by recent advances in 3D generative models. In particular, CoordTok encodes a video into factorized triplane representations and reconstructs patches that correspond to randomly sampled $(x,y,t)$ coordinates. This allows for training large tokenizer models directly on long videos without requiring excessive training resources. Our experiments show that CoordTok can drastically reduce the number of tokens for encoding long video clips. For instance, CoordTok can encode a 128-frame video with 128$\times$128 resolution into 1280 tokens, while baselines need 6144 or 8192 tokens to achieve similar reconstruction quality. We further show that this efficient video tokenization enables memory-efficient training of a diffusion transformer that can generate 128 frames at once.
Controllable Human Image Generation with Personalized Multi-Garments
Nov 25, 2024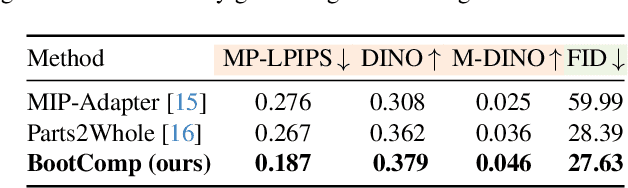
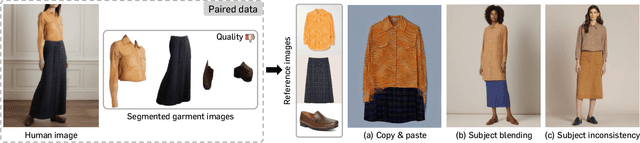

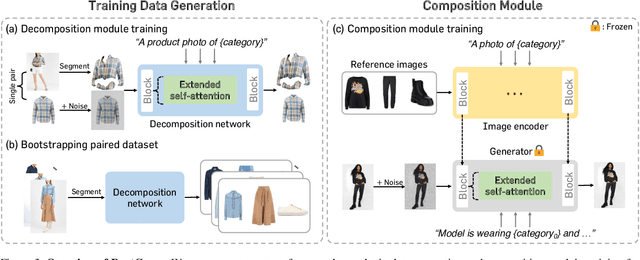
We present BootComp, a novel framework based on text-to-image diffusion models for controllable human image generation with multiple reference garments. Here, the main bottleneck is data acquisition for training: collecting a large-scale dataset of high-quality reference garment images per human subject is quite challenging, i.e., ideally, one needs to manually gather every single garment photograph worn by each human. To address this, we propose a data generation pipeline to construct a large synthetic dataset, consisting of human and multiple-garment pairs, by introducing a model to extract any reference garment images from each human image. To ensure data quality, we also propose a filtering strategy to remove undesirable generated data based on measuring perceptual similarities between the garment presented in human image and extracted garment. Finally, by utilizing the constructed synthetic dataset, we train a diffusion model having two parallel denoising paths that use multiple garment images as conditions to generate human images while preserving their fine-grained details. We further show the wide-applicability of our framework by adapting it to different types of reference-based generation in the fashion domain, including virtual try-on, and controllable human image generation with other conditions, e.g., pose, face, etc.
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Oct 09, 2024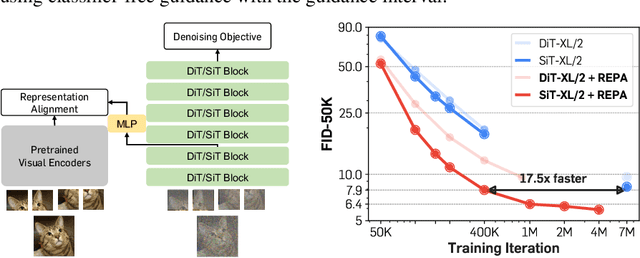

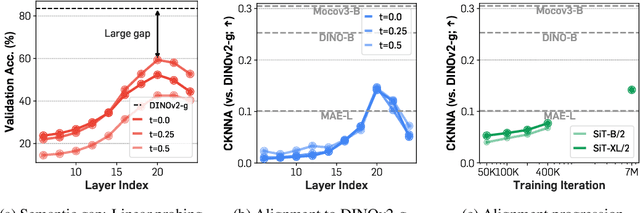
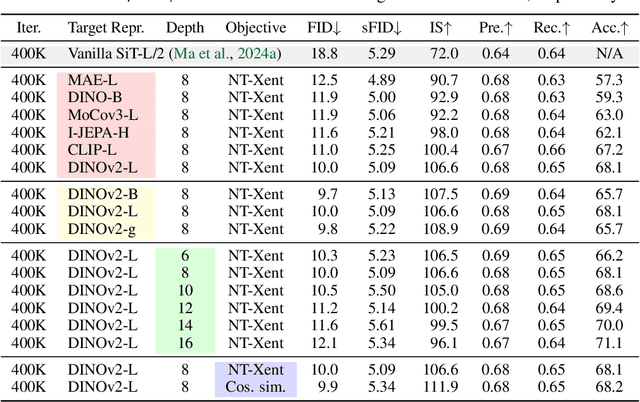
Recent studies have shown that the denoising process in (generative) diffusion models can induce meaningful (discriminative) representations inside the model, though the quality of these representations still lags behind those learned through recent self-supervised learning methods. We argue that one main bottleneck in training large-scale diffusion models for generation lies in effectively learning these representations. Moreover, training can be made easier by incorporating high-quality external visual representations, rather than relying solely on the diffusion models to learn them independently. We study this by introducing a straightforward regularization called REPresentation Alignment (REPA), which aligns the projections of noisy input hidden states in denoising networks with clean image representations obtained from external, pretrained visual encoders. The results are striking: our simple strategy yields significant improvements in both training efficiency and generation quality when applied to popular diffusion and flow-based transformers, such as DiTs and SiTs. For instance, our method can speed up SiT training by over 17.5$\times$, matching the performance (without classifier-free guidance) of a SiT-XL model trained for 7M steps in less than 400K steps. In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42 using classifier-free guidance with the guidance interval.