 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNACHUNKER: Learnable Tokenization for DNA Language Models
Jan 06, 2026DNA language models have emerged as powerful tools for decoding the complex language of DNA sequences. However, the performance of these models is heavily affected by their tokenization strategy, i.e., a method used to parse DNA sequences into a shorter sequence of chunks. In this work, we propose DNACHUNKER, which integrates a learnable dynamic DNA tokenization mechanism and is trained as a masked language model. Adopting the dynamic chunking procedure proposed by H-Net, our model learns to segment sequences into variable-length chunks. This dynamic chunking offers two key advantages: it's resilient to shifts and mutations in the DNA, and it allocates more detail to important functional areas. We demonstrate the performance of DNACHUNKER by training it on the human reference genome (HG38) and testing it on the Nucleotide Transformer and Genomic benchmarks. Further ablative experiments reveal that DNACHUNKER learns tokenization that grasps biological grammar and uses smaller chunks to preserve detail in important functional elements such as promoters and exons, while using larger chunks for repetitive, redundant regions.
Towards Reliable Test-Time Adaptation: Style Invariance as a Correctness Likelihood
Dec 08, 2025Test-time adaptation (TTA) enables efficient adaptation of deployed models, yet it often leads to poorly calibrated predictive uncertainty - a critical issue in high-stakes domains such as autonomous driving, finance, and healthcare. Existing calibration methods typically assume fixed models or static distributions, resulting in degraded performance under real-world, dynamic test conditions. To address these challenges, we introduce Style Invariance as a Correctness Likelihood (SICL), a framework that leverages style-invariance for robust uncertainty estimation. SICL estimates instance-wise correctness likelihood by measuring prediction consistency across style-altered variants, requiring only the model's forward pass. This makes it a plug-and-play, backpropagation-free calibration module compatible with any TTA method. Comprehensive evaluations across four baselines, five TTA methods, and two realistic scenarios with three model architecture demonstrate that SICL reduces calibration error by an average of 13 percentage points compared to conventional calibration approaches.
Learning Flexible Forward Trajectories for Masked Molecular Diffusion
May 22, 2025Masked diffusion models (MDMs) have achieved notable progress in modeling discrete data, while their potential in molecular generation remains underexplored. In this work, we explore their potential and introduce the surprising result that naively applying standards MDMs severely degrades the performance. We identify the critical cause of this issue as a state-clashing problem-where the forward diffusion of distinct molecules collapse into a common state, resulting in a mixture of reconstruction targets that cannot be learned using typical reverse diffusion process with unimodal predictions. To mitigate this, we propose Masked Element-wise Learnable Diffusion (MELD) that orchestrates per-element corruption trajectories to avoid collision between distinct molecular graphs. This is achieved through a parameterized noise scheduling network that assigns distinct corruption rates to individual graph elements, i.e., atoms and bonds. Extensive experiments on diverse molecular benchmarks reveal that MELD markedly enhances overall generation quality compared to element-agnostic noise scheduling, increasing the chemical validity of vanilla MDMs on ZINC250K from 15% to 93%, Furthermore, it achieves state-of-the-art property alignment in conditional generation tasks.
AdapTable: Test-Time Adaptation for Tabular Data via Shift-Aware Uncertainty Calibrator and Label Distribution Handler
Jul 15, 2024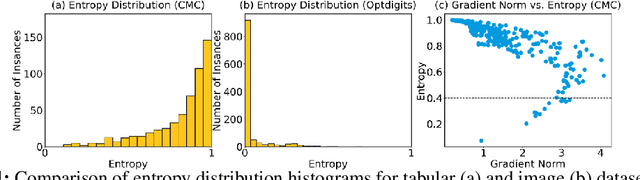
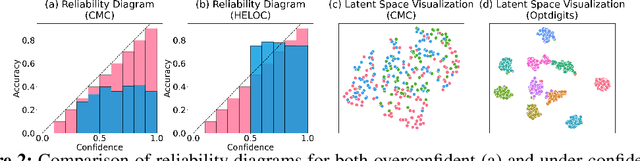
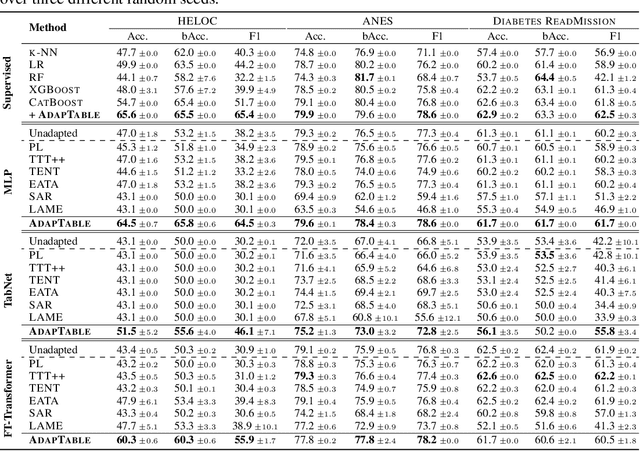
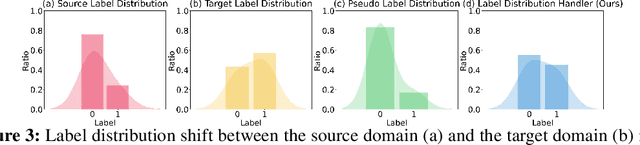
In real-world applications, tabular data often suffer from distribution shifts due to their widespread and abundant nature, leading to erroneous predictions of pre-trained machine learning models. However, addressing such distribution shifts in the tabular domain has been relatively underexplored due to unique challenges such as varying attributes and dataset sizes, as well as the limited representation learning capabilities of deep learning models for tabular data. Particularly, with the recent promising paradigm of test-time adaptation (TTA), where we adapt the off-the-shelf model to the unlabeled target domain during the inference phase without accessing the source domain, we observe that directly adopting commonly used TTA methods from other domains often leads to model collapse. We systematically explore challenges in tabular data test-time adaptation, including skewed entropy, complex latent space decision boundaries, confidence calibration issues with both overconfident and under-confident, and model bias towards source label distributions along with class imbalances. Based on these insights, we introduce AdapTable, a novel tabular test-time adaptation method that directly modifies output probabilities by estimating target label distributions and adjusting initial probabilities based on calibrated uncertainty. Extensive experiments on both natural distribution shifts and synthetic corruptions demonstrate the adaptation efficacy of the proposed method.
Unleashing the Potential of Text-attributed Graphs: Automatic Relation Decomposition via Large Language Models
May 28, 2024Recent advancements in text-attributed graphs (TAGs) have significantly improved the quality of node features by using the textual modeling capabilities of language models. Despite this success, utilizing text attributes to enhance the predefined graph structure remains largely unexplored. Our extensive analysis reveals that conventional edges on TAGs, treated as a single relation (e.g., hyperlinks) in previous literature, actually encompass mixed semantics (e.g., "advised by" and "participates in"). This simplification hinders the representation learning process of Graph Neural Networks (GNNs) on downstream tasks, even when integrated with advanced node features. In contrast, we discover that decomposing these edges into distinct semantic relations significantly enhances the performance of GNNs. Despite this, manually identifying and labeling of edges to corresponding semantic relations is labor-intensive, often requiring domain expertise. To this end, we introduce RoSE (Relation-oriented Semantic Edge-decomposition), a novel framework that leverages the capability of Large Language Models (LLMs) to decompose the graph structure by analyzing raw text attributes - in a fully automated manner. RoSE operates in two stages: (1) identifying meaningful relations using an LLM-based generator and discriminator, and (2) categorizing each edge into corresponding relations by analyzing textual contents associated with connected nodes via an LLM-based decomposer. Extensive experiments demonstrate that our model-agnostic framework significantly enhances node classification performance across various datasets, with improvements of up to 16% on the Wisconsin dataset.
Learning to Place Unseen Objects Stably using a Large-scale Simulation
Mar 15, 2023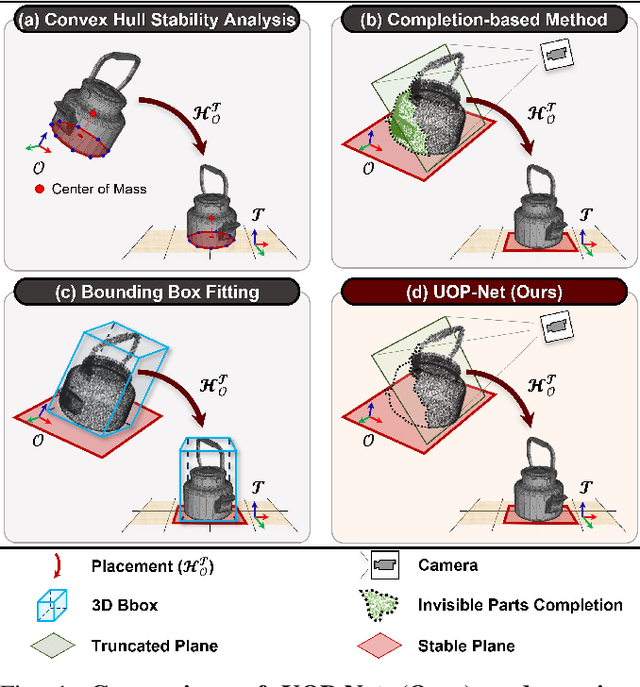
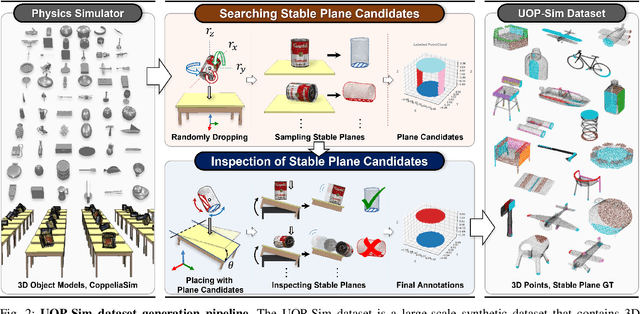
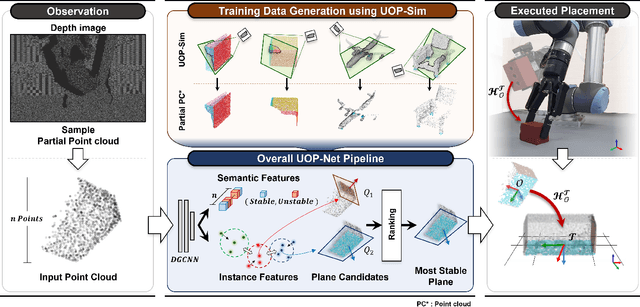
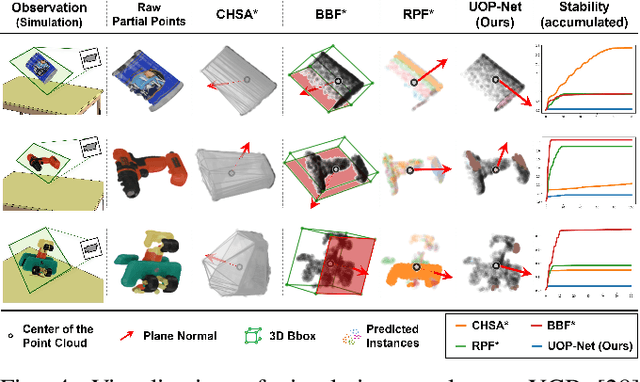
Object placement is a crucial task for robots in unstructured environments as it enables them to manipulate and arrange objects safely and efficiently. However, existing methods for object placement have limitations, such as the requirement for a complete 3D model of the object or the inability to handle complex object shapes, which restrict the applicability of robots in unstructured scenarios. In this paper, we propose an Unseen Object Placement (UOP) method that directly detects stable planes of unseen objects from a single-view and partial point cloud. We trained our model on large-scale simulation data to generalize over relationships between the shape and properties of stable planes with a 3D point cloud. We verify our approach through simulation and real-world robot experiments, demonstrating state-of-the-art performance for placing single-view and partial objects. Our UOP approach enables robots to place objects stably, even when the object's shape and properties are not fully known, providing a promising solution for object placement in unstructured environments. Our research has potential applications in various domains such as manufacturing, logistics, and home automation. Additional results can be viewed on https://sites.google.com/uop-net, and we will release our code, dataset upon publication.
Robust Continual Test-time Adaptation: Instance-aware BN and Prediction-balanced Memory
Aug 10, 2022
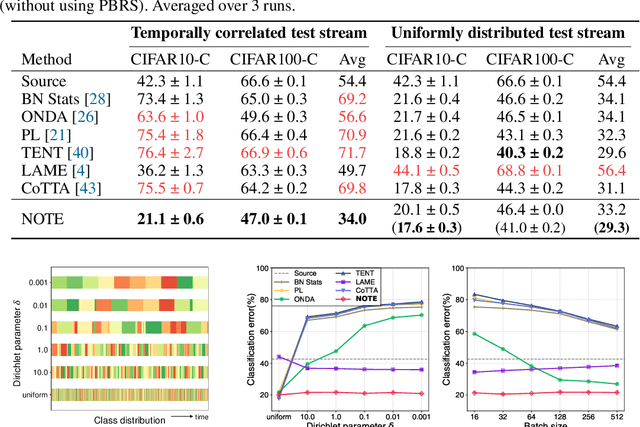
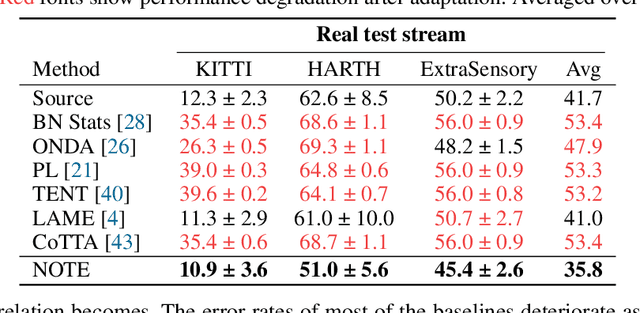

Test-time adaptation (TTA) is an emerging paradigm that addresses distributional shifts between training and testing phases without additional data acquisition or labeling cost; only unlabeled test data streams are used for continual model adaptation. Previous TTA schemes assume that the test samples are independent and identically distributed (i.i.d.), even though they are often temporally correlated (non-i.i.d.) in application scenarios, e.g., autonomous driving. We discover that most existing TTA methods fail dramatically under such scenarios. Motivated by this, we present a new test-time adaptation scheme that is robust against non-i.i.d. test data streams. Our novelty is mainly two-fold: (a) Instance-Aware Batch Normalization (IABN) that corrects normalization for out-of-distribution samples, and (b) Prediction-balanced Reservoir Sampling (PBRS) that simulates i.i.d. data stream from non-i.i.d. stream in a class-balanced manner. Our evaluation with various datasets, including real-world non-i.i.d. streams, demonstrates that the proposed robust TTA not only outperforms state-of-the-art TTA algorithms in the non-i.i.d. setting, but also achieves comparable performance to those algorithms under the i.i.d. assumption.
Unseen Object Amodal Instance Segmentation via Hierarchical Occlusion Modeling
Sep 23, 2021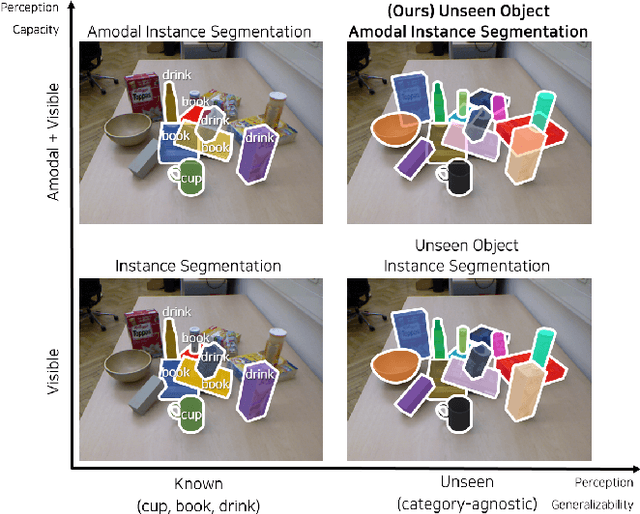
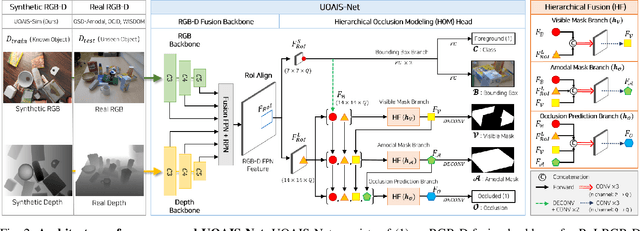
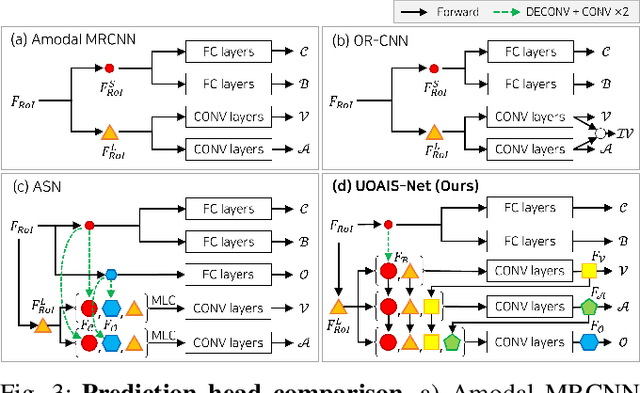

Instance-aware segmentation of unseen objects is essential for a robotic system in an unstructured environment. Although previous works achieved encouraging results, they were limited to segmenting the only visible regions of unseen objects. For robotic manipulation in a cluttered scene, amodal perception is required to handle the occluded objects behind others. This paper addresses Unseen Object Amodal Instance Segmentation (UOAIS) to detect 1) visible masks, 2) amodal masks, and 3) occlusions on unseen object instances. For this, we propose a Hierarchical Occlusion Modeling (HOM) scheme designed to reason about the occlusion by assigning a hierarchy to a feature fusion and prediction order. We evaluated our method on three benchmarks (tabletop, indoors, and bin environments) and achieved state-of-the-art (SOTA) performance. Robot demos for picking up occluded objects, codes, and datasets are available at https://sites.google.com/view/uoais
Acceleration of Actor-Critic Deep Reinforcement Learning for Visual Grasping in Clutter by State Representation Learning Based on Disentanglement of a Raw Input Image
Feb 27, 2020
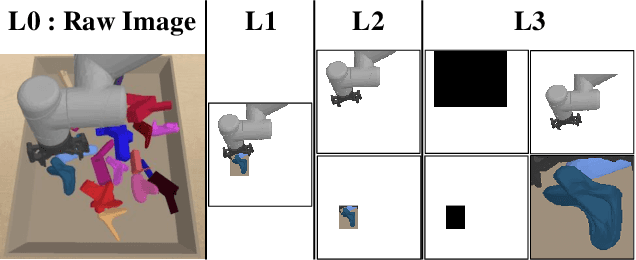
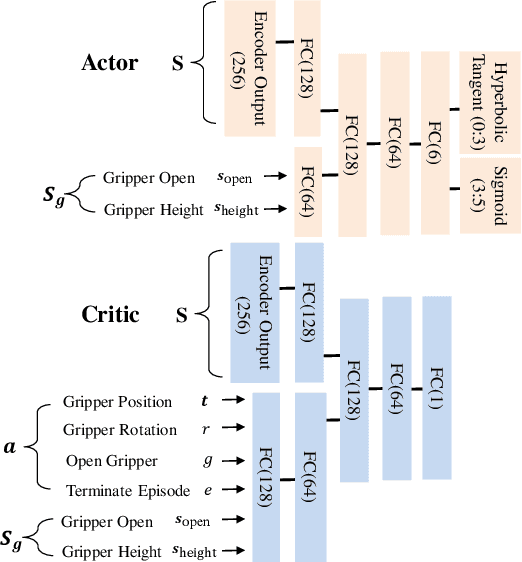
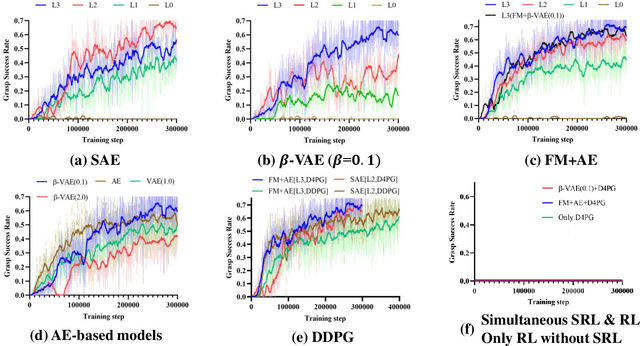
For a robotic grasping task in which diverse unseen target objects exist in a cluttered environment, some deep learning-based methods have achieved state-of-the-art results using visual input directly. In contrast, actor-critic deep reinforcement learning (RL) methods typically perform very poorly when grasping diverse objects, especially when learning from raw images and sparse rewards. To make these RL techniques feasible for vision-based grasping tasks, we employ state representation learning (SRL), where we encode essential information first for subsequent use in RL. However, typical representation learning procedures are unsuitable for extracting pertinent information for learning the grasping skill, because the visual inputs for representation learning, where a robot attempts to grasp a target object in clutter, are extremely complex. We found that preprocessing based on the disentanglement of a raw input image is the key to effectively capturing a compact representation. This enables deep RL to learn robotic grasping skills from highly varied and diverse visual inputs. We demonstrate the effectiveness of this approach with varying levels of disentanglement in a realistic simulated environment.