 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Flexible Forward Trajectories for Masked Molecular Diffusion
May 22, 2025Masked diffusion models (MDMs) have achieved notable progress in modeling discrete data, while their potential in molecular generation remains underexplored. In this work, we explore their potential and introduce the surprising result that naively applying standards MDMs severely degrades the performance. We identify the critical cause of this issue as a state-clashing problem-where the forward diffusion of distinct molecules collapse into a common state, resulting in a mixture of reconstruction targets that cannot be learned using typical reverse diffusion process with unimodal predictions. To mitigate this, we propose Masked Element-wise Learnable Diffusion (MELD) that orchestrates per-element corruption trajectories to avoid collision between distinct molecular graphs. This is achieved through a parameterized noise scheduling network that assigns distinct corruption rates to individual graph elements, i.e., atoms and bonds. Extensive experiments on diverse molecular benchmarks reveal that MELD markedly enhances overall generation quality compared to element-agnostic noise scheduling, increasing the chemical validity of vanilla MDMs on ZINC250K from 15% to 93%, Furthermore, it achieves state-of-the-art property alignment in conditional generation tasks.
Towards Precise Prediction Uncertainty in GNNs: Refining GNNs with Topology-grouping Strategy
Dec 18, 2024



Recent advancements in graph neural networks (GNNs) have highlighted the critical need of calibrating model predictions, with neighborhood prediction similarity recognized as a pivotal component. Existing studies suggest that nodes with analogous neighborhood prediction similarity often exhibit similar calibration characteristics. Building on this insight, recent approaches incorporate neighborhood similarity into node-wise temperature scaling techniques. However, our analysis reveals that this assumption does not hold universally. Calibration errors can differ significantly even among nodes with comparable neighborhood similarity, depending on their confidence levels. This necessitates a re-evaluation of existing GNN calibration methods, as a single, unified approach may lead to sub-optimal calibration. In response, we introduce **Simi-Mailbox**, a novel approach that categorizes nodes by both neighborhood similarity and their own confidence, irrespective of proximity or connectivity. Our method allows fine-grained calibration by employing *group-specific* temperature scaling, with each temperature tailored to address the specific miscalibration level of affiliated nodes, rather than adhering to a uniform trend based on neighborhood similarity. Extensive experiments demonstrate the effectiveness of our **Simi-Mailbox** across diverse datasets on different GNN architectures, achieving up to 13.79\% error reduction compared to uncalibrated GNN predictions.
Unleashing the Potential of Text-attributed Graphs: Automatic Relation Decomposition via Large Language Models
May 28, 2024Recent advancements in text-attributed graphs (TAGs) have significantly improved the quality of node features by using the textual modeling capabilities of language models. Despite this success, utilizing text attributes to enhance the predefined graph structure remains largely unexplored. Our extensive analysis reveals that conventional edges on TAGs, treated as a single relation (e.g., hyperlinks) in previous literature, actually encompass mixed semantics (e.g., "advised by" and "participates in"). This simplification hinders the representation learning process of Graph Neural Networks (GNNs) on downstream tasks, even when integrated with advanced node features. In contrast, we discover that decomposing these edges into distinct semantic relations significantly enhances the performance of GNNs. Despite this, manually identifying and labeling of edges to corresponding semantic relations is labor-intensive, often requiring domain expertise. To this end, we introduce RoSE (Relation-oriented Semantic Edge-decomposition), a novel framework that leverages the capability of Large Language Models (LLMs) to decompose the graph structure by analyzing raw text attributes - in a fully automated manner. RoSE operates in two stages: (1) identifying meaningful relations using an LLM-based generator and discriminator, and (2) categorizing each edge into corresponding relations by analyzing textual contents associated with connected nodes via an LLM-based decomposer. Extensive experiments demonstrate that our model-agnostic framework significantly enhances node classification performance across various datasets, with improvements of up to 16% on the Wisconsin dataset.
TEDDY: Trimming Edges with Degree-based Discrimination strategY
Feb 02, 2024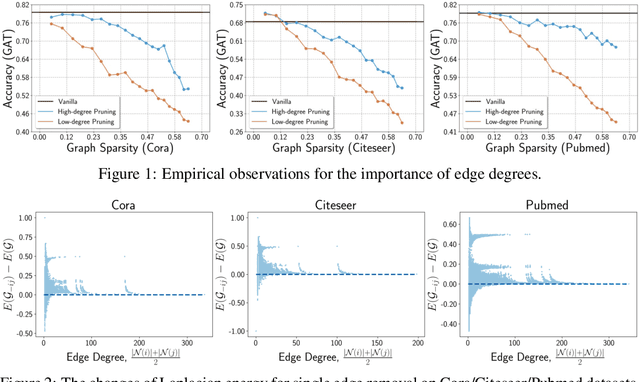
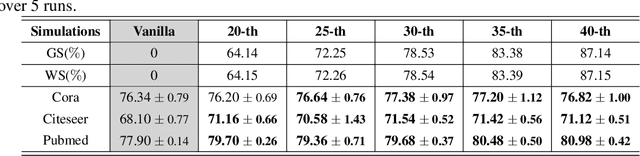
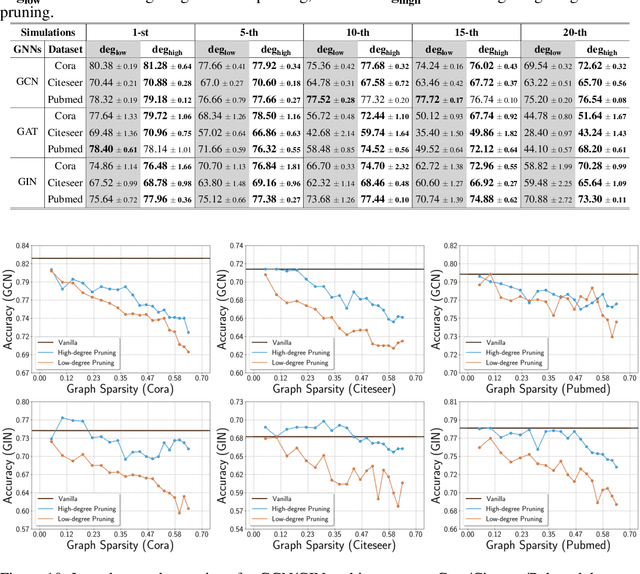
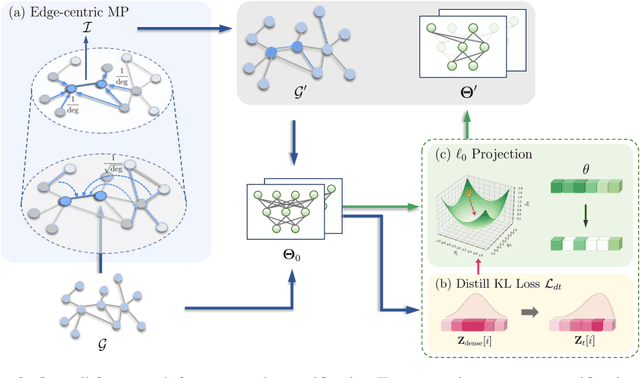
Since the pioneering work on the lottery ticket hypothesis for graph neural networks (GNNs) was proposed in Chen et al. (2021), the study on finding graph lottery tickets (GLT) has become one of the pivotal focus in the GNN community, inspiring researchers to discover sparser GLT while achieving comparable performance to original dense networks. In parallel, the graph structure has gained substantial attention as a crucial factor in GNN training dynamics, also elucidated by several recent studies. Despite this, contemporary studies on GLT, in general, have not fully exploited inherent pathways in the graph structure and identified tickets in an iterative manner, which is time-consuming and inefficient. To address these limitations, we introduce TEDDY, a one-shot edge sparsification framework that leverages structural information by incorporating edge-degree information. Following edge sparsification, we encourage the parameter sparsity during training via simple projected gradient descent on the $\ell_0$ ball. Given the target sparsity levels for both the graph structure and the model parameters, our TEDDY facilitates efficient and rapid realization of GLT within a single training. Remarkably, our experimental results demonstrate that TEDDY significantly surpasses conventional iterative approaches in generalization, even when conducting one-shot sparsification that solely utilizes graph structures, without taking node features into account.
PC-Adapter: Topology-Aware Adapter for Efficient Domain Adaption on Point Clouds with Rectified Pseudo-label
Sep 29, 2023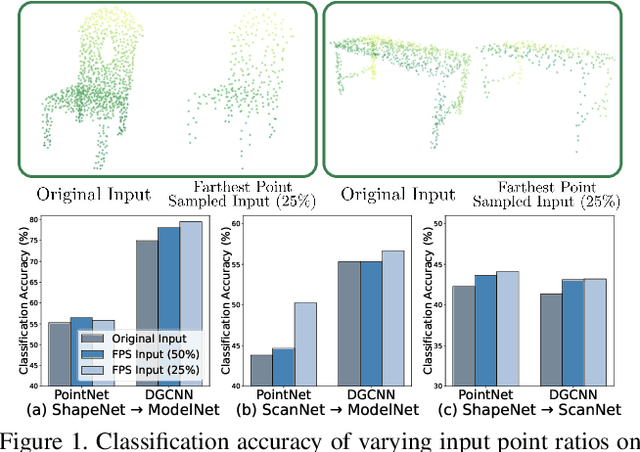
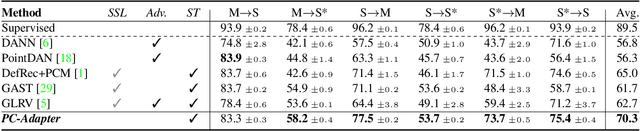
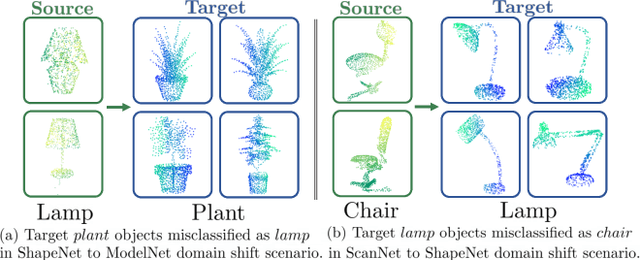
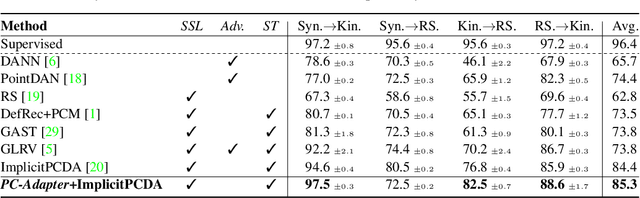
Understanding point clouds captured from the real-world is challenging due to shifts in data distribution caused by varying object scales, sensor angles, and self-occlusion. Prior works have addressed this issue by combining recent learning principles such as self-supervised learning, self-training, and adversarial training, which leads to significant computational overhead.Toward succinct yet powerful domain adaptation for point clouds, we revisit the unique challenges of point cloud data under domain shift scenarios and discover the importance of the global geometry of source data and trends of target pseudo-labels biased to the source label distribution. Motivated by our observations, we propose an adapter-guided domain adaptation method, PC-Adapter, that preserves the global shape information of the source domain using an attention-based adapter, while learning the local characteristics of the target domain via another adapter equipped with graph convolution. Additionally, we propose a novel pseudo-labeling strategy resilient to the classifier bias by adjusting confidence scores using their class-wise confidence distributions to consider relative confidences. Our method demonstrates superiority over baselines on various domain shift settings in benchmark datasets - PointDA, GraspNetPC, and PointSegDA.