 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Remedy for Dataset Bias via Self-Influence: A Mislabeled Sample Perspective
Nov 01, 2024Learning generalized models from biased data is an important undertaking toward fairness in deep learning. To address this issue, recent studies attempt to identify and leverage bias-conflicting samples free from spurious correlations without prior knowledge of bias or an unbiased set. However, spurious correlation remains an ongoing challenge, primarily due to the difficulty in precisely detecting these samples. In this paper, inspired by the similarities between mislabeled samples and bias-conflicting samples, we approach this challenge from a novel perspective of mislabeled sample detection. Specifically, we delve into Influence Function, one of the standard methods for mislabeled sample detection, for identifying bias-conflicting samples and propose a simple yet effective remedy for biased models by leveraging them. Through comprehensive analysis and experiments on diverse datasets, we demonstrate that our new perspective can boost the precision of detection and rectify biased models effectively. Furthermore, our approach is complementary to existing methods, showing performance improvement even when applied to models that have already undergone recent debiasing techniques.
Augmentation-Driven Metric for Balancing Preservation and Modification in Text-Guided Image Editing
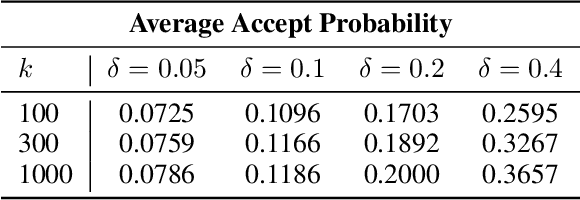
Oct 15, 2024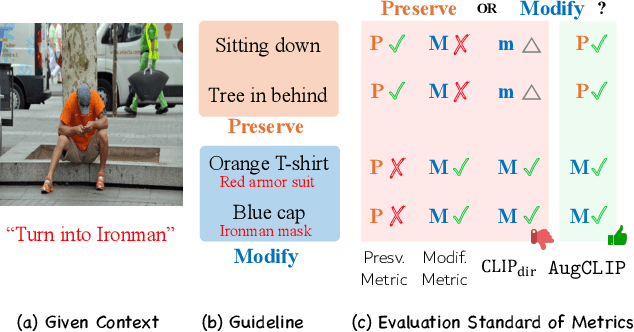

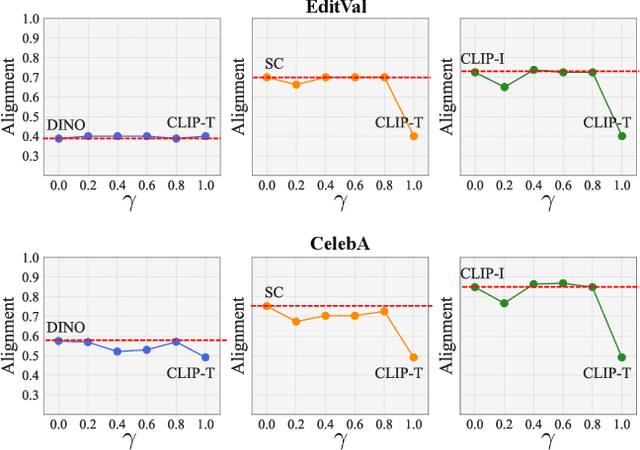
The development of vision-language and generative models has significantly advanced text-guided image editing, which seeks \textit{preservation} of core elements in the source image while implementing \textit{modifications} based on the target text. However, in the absence of evaluation metrics specifically tailored for text-guided image editing, existing metrics are limited in balancing the consideration of preservation and modification. Especially, our analysis reveals that CLIPScore, the most commonly used metric, tends to favor modification and ignore core attributes to be preserved, resulting in inaccurate evaluations. To address this problem, we propose \texttt{AugCLIP}, \black{which balances preservation and modification by estimating the representation of an ideal edited image that aligns with the target text with minimum alteration on the source image. We augment detailed textual descriptions on the source image and the target text using a multi-modal large language model, to model a hyperplane that separates CLIP space into source or target. The representation of the ideal edited image is an orthogonal projection of the source image into the hyperplane, which encapsulates the relative importance of each attribute considering the interdependent relationships.} Our extensive experiments on five benchmark datasets, encompassing a diverse range of editing scenarios, demonstrate that \texttt{AugCLIP} aligns remarkably well with human evaluation standards compared to existing metrics. The code for evaluation will be open-sourced to contribute to the community.
LANTERN: Accelerating Visual Autoregressive Models with Relaxed Speculative Decoding
Oct 04, 2024


Auto-Regressive (AR) models have recently gained prominence in image generation, often matching or even surpassing the performance of diffusion models. However, one major limitation of AR models is their sequential nature, which processes tokens one at a time, slowing down generation compared to models like GANs or diffusion-based methods that operate more efficiently. While speculative decoding has proven effective for accelerating LLMs by generating multiple tokens in a single forward, its application in visual AR models remains largely unexplored. In this work, we identify a challenge in this setting, which we term \textit{token selection ambiguity}, wherein visual AR models frequently assign uniformly low probabilities to tokens, hampering the performance of speculative decoding. To overcome this challenge, we propose a relaxed acceptance condition referred to as LANTERN that leverages the interchangeability of tokens in latent space. This relaxation restores the effectiveness of speculative decoding in visual AR models by enabling more flexible use of candidate tokens that would otherwise be prematurely rejected. Furthermore, by incorporating a total variation distance bound, we ensure that these speed gains are achieved without significantly compromising image quality or semantic coherence. Experimental results demonstrate the efficacy of our method in providing a substantial speed-up over speculative decoding. In specific, compared to a na\"ive application of the state-of-the-art speculative decoding, LANTERN increases speed-ups by $\mathbf{1.75}\times$ and $\mathbf{1.76}\times$, as compared to greedy decoding and random sampling, respectively, when applied to LlamaGen, a contemporary visual AR model.
LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices
Jul 16, 2024



With the commercialization of large language models (LLMs), weight-activation quantization has emerged to compress and accelerate LLMs, achieving high throughput while reducing inference costs. However, existing post-training quantization (PTQ) techniques for quantizing weights and activations of LLMs still suffer from non-negligible accuracy drops, especially on massive multitask language understanding. To address this issue, we propose Low-Rank Quantization (LRQ) $-$ a simple yet effective post-training weight quantization method for LLMs that reconstructs the outputs of an intermediate Transformer block by leveraging low-rank weight-scaling matrices, replacing the conventional full weight-scaling matrices that entail as many learnable scales as their associated weights. Thanks to parameter sharing via low-rank structure, LRQ only needs to learn significantly fewer parameters while enabling the individual scaling of weights, thus boosting the generalization capability of quantized LLMs. We show the superiority of LRQ over prior LLM PTQ works under (i) $8$-bit weight and per-tensor activation quantization, (ii) $4$-bit weight and $8$-bit per-token activation quantization, and (iii) low-bit weight-only quantization schemes. Our code is available at \url{https://github.com/onliwad101/FlexRound_LRQ} to inspire LLM researchers and engineers.
AdapTable: Test-Time Adaptation for Tabular Data via Shift-Aware Uncertainty Calibrator and Label Distribution Handler
Jul 15, 2024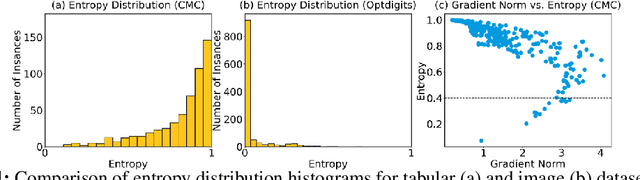
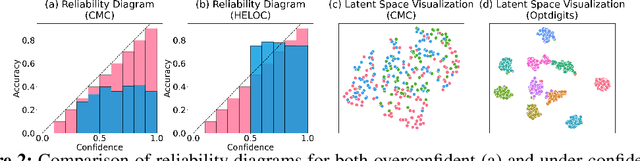
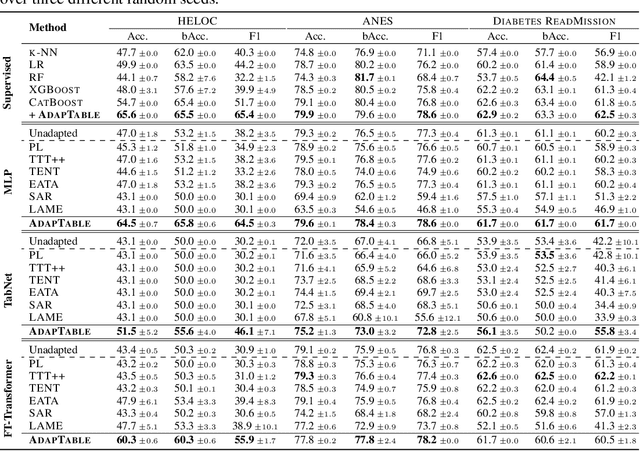
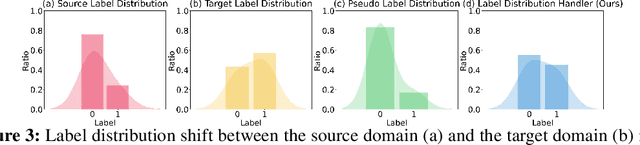
In real-world applications, tabular data often suffer from distribution shifts due to their widespread and abundant nature, leading to erroneous predictions of pre-trained machine learning models. However, addressing such distribution shifts in the tabular domain has been relatively underexplored due to unique challenges such as varying attributes and dataset sizes, as well as the limited representation learning capabilities of deep learning models for tabular data. Particularly, with the recent promising paradigm of test-time adaptation (TTA), where we adapt the off-the-shelf model to the unlabeled target domain during the inference phase without accessing the source domain, we observe that directly adopting commonly used TTA methods from other domains often leads to model collapse. We systematically explore challenges in tabular data test-time adaptation, including skewed entropy, complex latent space decision boundaries, confidence calibration issues with both overconfident and under-confident, and model bias towards source label distributions along with class imbalances. Based on these insights, we introduce AdapTable, a novel tabular test-time adaptation method that directly modifies output probabilities by estimating target label distributions and adjusting initial probabilities based on calibrated uncertainty. Extensive experiments on both natural distribution shifts and synthetic corruptions demonstrate the adaptation efficacy of the proposed method.
Token-Supervised Value Models for Enhancing Mathematical Reasoning Capabilities of Large Language Models
Jul 12, 2024Large Language Models (LLMs) have demonstrated impressive problem-solving capabilities in mathematics through step-by-step reasoning chains. However, they are susceptible to reasoning errors that impact the quality of subsequent reasoning chains and the final answer due to language models' autoregressive token-by-token generating nature. Recent works have proposed adopting external verifiers to guide the generation of reasoning paths, but existing works utilize models that have been trained with step-by-step labels to assess the correctness of token-by-token reasoning chains. Consequently, they struggle to recognize discriminative details of tokens within a reasoning path and lack the ability to evaluate whether an intermediate reasoning path is on a promising track toward the correct final answer. To amend the lack of sound and token-grained math-verification signals, we devise a novel training scheme for verifiers that apply token-level supervision with the expected cumulative reward (i.e., value). Furthermore, we propose a practical formulation of the cumulative reward by reducing it to finding the probability of future correctness of the final answer and thereby enabling the empirical estimation of the value. Experimental results on mathematical reasoning benchmarks show that Token-Supervised Value Model (TVM) can outperform step-by-step verifiers on GSM8K and MATH with Mistral and Llama.
Unleashing the Potential of Text-attributed Graphs: Automatic Relation Decomposition via Large Language Models
May 28, 2024Recent advancements in text-attributed graphs (TAGs) have significantly improved the quality of node features by using the textual modeling capabilities of language models. Despite this success, utilizing text attributes to enhance the predefined graph structure remains largely unexplored. Our extensive analysis reveals that conventional edges on TAGs, treated as a single relation (e.g., hyperlinks) in previous literature, actually encompass mixed semantics (e.g., "advised by" and "participates in"). This simplification hinders the representation learning process of Graph Neural Networks (GNNs) on downstream tasks, even when integrated with advanced node features. In contrast, we discover that decomposing these edges into distinct semantic relations significantly enhances the performance of GNNs. Despite this, manually identifying and labeling of edges to corresponding semantic relations is labor-intensive, often requiring domain expertise. To this end, we introduce RoSE (Relation-oriented Semantic Edge-decomposition), a novel framework that leverages the capability of Large Language Models (LLMs) to decompose the graph structure by analyzing raw text attributes - in a fully automated manner. RoSE operates in two stages: (1) identifying meaningful relations using an LLM-based generator and discriminator, and (2) categorizing each edge into corresponding relations by analyzing textual contents associated with connected nodes via an LLM-based decomposer. Extensive experiments demonstrate that our model-agnostic framework significantly enhances node classification performance across various datasets, with improvements of up to 16% on the Wisconsin dataset.
No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization
Feb 28, 2024



Key-Value (KV) Caching has become an essential technique for accelerating the inference speed and throughput of generative Large Language Models~(LLMs). However, the memory footprint of the KV cache poses a critical bottleneck in LLM deployment as the cache size grows with batch size and sequence length, often surpassing even the size of the model itself. Although recent methods were proposed to select and evict unimportant KV pairs from the cache to reduce memory consumption, the potential ramifications of eviction on the generative process are yet to be thoroughly examined. In this paper, we examine the detrimental impact of cache eviction and observe that unforeseen risks arise as the information contained in the KV pairs is exhaustively discarded, resulting in safety breaches, hallucinations, and context loss. Surprisingly, we find that preserving even a small amount of information contained in the evicted KV pairs via reduced precision quantization substantially recovers the incurred degradation. On the other hand, we observe that the important KV pairs must be kept at a relatively higher precision to safeguard the generation quality. Motivated by these observations, we propose \textit{Mixed-precision KV cache}~(MiKV), a reliable cache compression method that simultaneously preserves the context details by retaining the evicted KV pairs in low-precision and ensure generation quality by keeping the important KV pairs in high-precision. Experiments on diverse benchmarks and LLM backbones show that our proposed method offers a state-of-the-art trade-off between compression ratio and performance, compared to other baselines.
Saliency Grafting: Innocuous Attribution-Guided Mixup with Calibrated Label Mixing
Dec 16, 2021
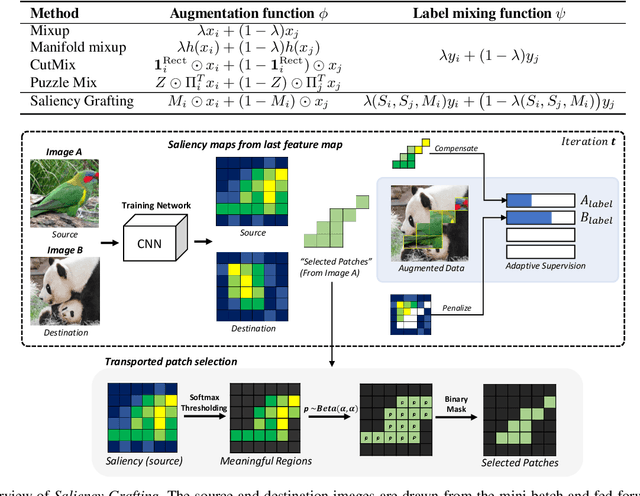
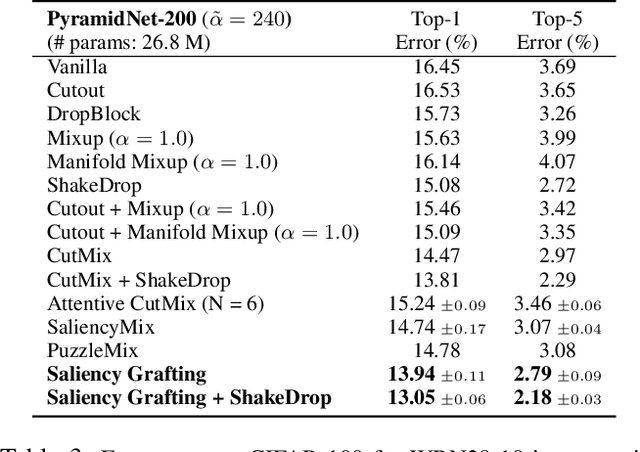

The Mixup scheme suggests mixing a pair of samples to create an augmented training sample and has gained considerable attention recently for improving the generalizability of neural networks. A straightforward and widely used extension of Mixup is to combine with regional dropout-like methods: removing random patches from a sample and replacing it with the features from another sample. Albeit their simplicity and effectiveness, these methods are prone to create harmful samples due to their randomness. To address this issue, 'maximum saliency' strategies were recently proposed: they select only the most informative features to prevent such a phenomenon. However, they now suffer from lack of sample diversification as they always deterministically select regions with maximum saliency, injecting bias into the augmented data. In this paper, we present, a novel, yet simple Mixup-variant that captures the best of both worlds. Our idea is two-fold. By stochastically sampling the features and 'grafting' them onto another sample, our method effectively generates diverse yet meaningful samples. Its second ingredient is to produce the label of the grafted sample by mixing the labels in a saliency-calibrated fashion, which rectifies supervision misguidance introduced by the random sampling procedure. Our experiments under CIFAR, Tiny-ImageNet, and ImageNet datasets show that our scheme outperforms the current state-of-the-art augmentation strategies not only in terms of classification accuracy, but is also superior in coping under stress conditions such as data corruption and object occlusion.
Fighting Fire with Fire: Contrastive Debiasing without Bias-free Data via Generative Bias-transformation
Dec 02, 2021

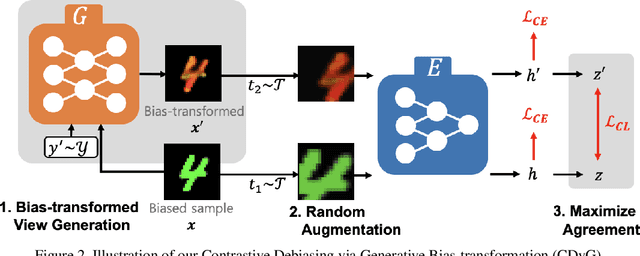
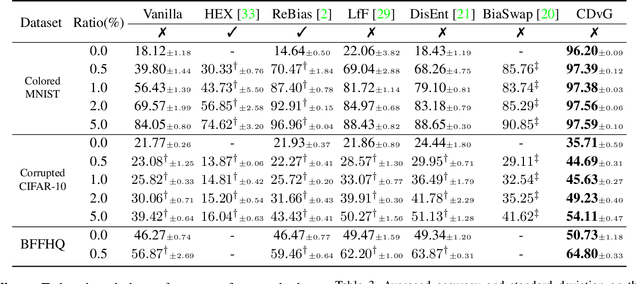
Despite their remarkable ability to generalize with over-capacity networks, deep neural networks often learn to abuse spurious biases in the data instead of using the actual task-related information. Since such shortcuts are only effective within the collected dataset, the resulting biased model underperforms on real-world inputs, or cause unintended social repercussions such as gender discrimination. To counteract the influence of bias, existing methods either exploit auxiliary information which is rarely obtainable in practice, or sift for bias-free samples in the training data, hoping for the sufficient existence of clean samples. However, such presumptions about the data are not always guaranteed. In this paper, we propose Contrastive Debiasing via Generative Bias-transformation~(CDvG) which is capable of operating in more general environments where existing methods break down due to unmet presumptions such as insufficient bias-free samples. Motivated by our observation that not only discriminative models, as previously known, but also generative models tend to focus on the bias when possible, CDvG uses a translation model to transform the bias in the sample to another mode of bias while preserving task-relevant information. Through contrastive learning, we set transformed biased views against another, learning bias-invariant representations. Experimental results on synthetic and real-world datasets demonstrate that our framework outperforms the current state-of-the-arts, and effectively prevents the models from being biased even when bias-free samples are extremely scarce.