 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Grafting: Innocuous Attribution-Guided Mixup with Calibrated Label Mixing
Paper and Code
Dec 16, 2021
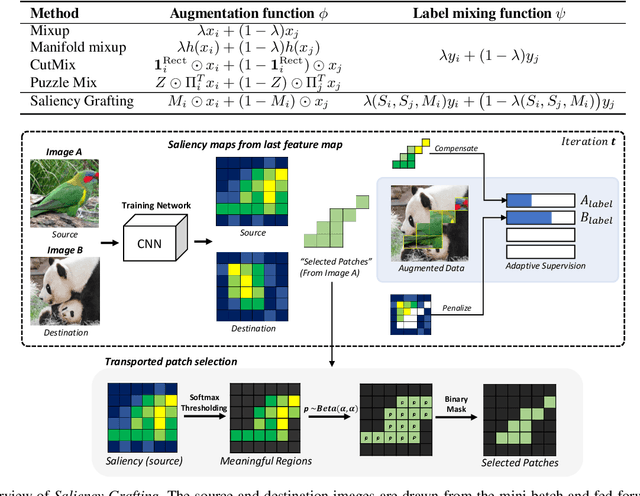
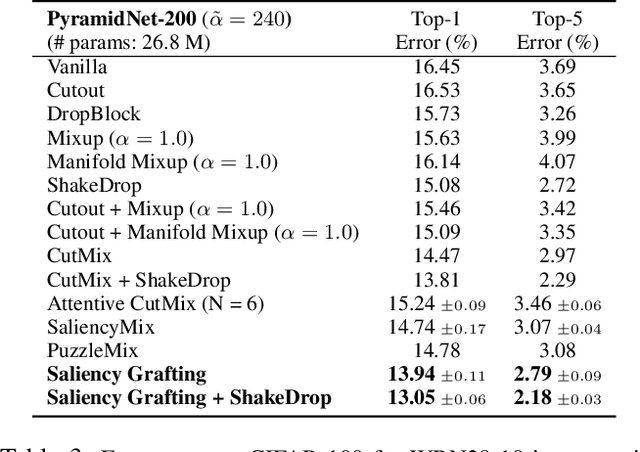

The Mixup scheme suggests mixing a pair of samples to create an augmented training sample and has gained considerable attention recently for improving the generalizability of neural networks. A straightforward and widely used extension of Mixup is to combine with regional dropout-like methods: removing random patches from a sample and replacing it with the features from another sample. Albeit their simplicity and effectiveness, these methods are prone to create harmful samples due to their randomness. To address this issue, 'maximum saliency' strategies were recently proposed: they select only the most informative features to prevent such a phenomenon. However, they now suffer from lack of sample diversification as they always deterministically select regions with maximum saliency, injecting bias into the augmented data. In this paper, we present, a novel, yet simple Mixup-variant that captures the best of both worlds. Our idea is two-fold. By stochastically sampling the features and 'grafting' them onto another sample, our method effectively generates diverse yet meaningful samples. Its second ingredient is to produce the label of the grafted sample by mixing the labels in a saliency-calibrated fashion, which rectifies supervision misguidance introduced by the random sampling procedure. Our experiments under CIFAR, Tiny-ImageNet, and ImageNet datasets show that our scheme outperforms the current state-of-the-art augmentation strategies not only in terms of classification accuracy, but is also superior in coping under stress conditions such as data corruption and object occlusion.