 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Timestep Zero-Shot Candidate Selection for Instruction-Guided Image Editing
Apr 18, 2025Despite recent advances in diffusion models, achieving reliable image generation and editing remains challenging due to the inherent diversity induced by stochastic noise in the sampling process. Instruction-guided image editing with diffusion models offers user-friendly capabilities, yet editing failures, such as background distortion, frequently occur. Users often resort to trial and error, adjusting seeds or prompts to achieve satisfactory results, which is inefficient. While seed selection methods exist for Text-to-Image (T2I) generation, they depend on external verifiers, limiting applicability, and evaluating multiple seeds increases computational complexity. To address this, we first establish a multiple-seed-based image editing baseline using background consistency scores, achieving Best-of-N performance without supervision. Building on this, we introduce ELECT (Early-timestep Latent Evaluation for Candidate Selection), a zero-shot framework that selects reliable seeds by estimating background mismatches at early diffusion timesteps, identifying the seed that retains the background while modifying only the foreground. ELECT ranks seed candidates by a background inconsistency score, filtering unsuitable samples early based on background consistency while preserving editability. Beyond standalone seed selection, ELECT integrates into instruction-guided editing pipelines and extends to Multimodal Large-Language Models (MLLMs) for joint seed and prompt selection, further improving results when seed selection alone is insufficient. Experiments show that ELECT reduces computational costs (by 41 percent on average and up to 61 percent) while improving background consistency and instruction adherence, achieving around 40 percent success rates in previously failed cases - without any external supervision or training.
A Simple Remedy for Dataset Bias via Self-Influence: A Mislabeled Sample Perspective
Nov 01, 2024Learning generalized models from biased data is an important undertaking toward fairness in deep learning. To address this issue, recent studies attempt to identify and leverage bias-conflicting samples free from spurious correlations without prior knowledge of bias or an unbiased set. However, spurious correlation remains an ongoing challenge, primarily due to the difficulty in precisely detecting these samples. In this paper, inspired by the similarities between mislabeled samples and bias-conflicting samples, we approach this challenge from a novel perspective of mislabeled sample detection. Specifically, we delve into Influence Function, one of the standard methods for mislabeled sample detection, for identifying bias-conflicting samples and propose a simple yet effective remedy for biased models by leveraging them. Through comprehensive analysis and experiments on diverse datasets, we demonstrate that our new perspective can boost the precision of detection and rectify biased models effectively. Furthermore, our approach is complementary to existing methods, showing performance improvement even when applied to models that have already undergone recent debiasing techniques.
Augmentation-Driven Metric for Balancing Preservation and Modification in Text-Guided Image Editing
Oct 15, 2024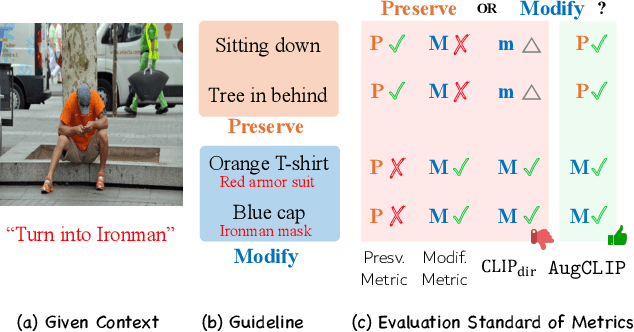

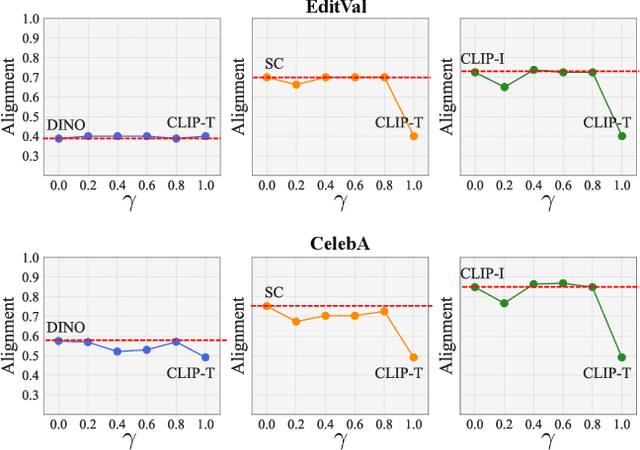
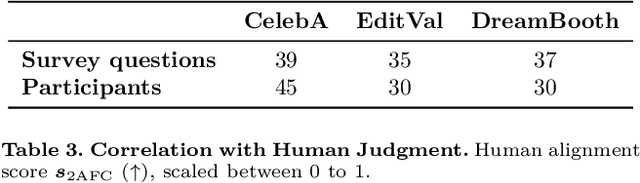
The development of vision-language and generative models has significantly advanced text-guided image editing, which seeks \textit{preservation} of core elements in the source image while implementing \textit{modifications} based on the target text. However, in the absence of evaluation metrics specifically tailored for text-guided image editing, existing metrics are limited in balancing the consideration of preservation and modification. Especially, our analysis reveals that CLIPScore, the most commonly used metric, tends to favor modification and ignore core attributes to be preserved, resulting in inaccurate evaluations. To address this problem, we propose \texttt{AugCLIP}, \black{which balances preservation and modification by estimating the representation of an ideal edited image that aligns with the target text with minimum alteration on the source image. We augment detailed textual descriptions on the source image and the target text using a multi-modal large language model, to model a hyperplane that separates CLIP space into source or target. The representation of the ideal edited image is an orthogonal projection of the source image into the hyperplane, which encapsulates the relative importance of each attribute considering the interdependent relationships.} Our extensive experiments on five benchmark datasets, encompassing a diverse range of editing scenarios, demonstrate that \texttt{AugCLIP} aligns remarkably well with human evaluation standards compared to existing metrics. The code for evaluation will be open-sourced to contribute to the community.
LANTERN: Accelerating Visual Autoregressive Models with Relaxed Speculative Decoding
Oct 04, 2024


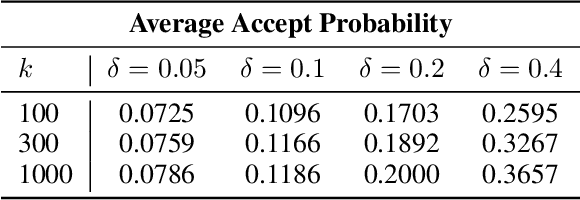
Auto-Regressive (AR) models have recently gained prominence in image generation, often matching or even surpassing the performance of diffusion models. However, one major limitation of AR models is their sequential nature, which processes tokens one at a time, slowing down generation compared to models like GANs or diffusion-based methods that operate more efficiently. While speculative decoding has proven effective for accelerating LLMs by generating multiple tokens in a single forward, its application in visual AR models remains largely unexplored. In this work, we identify a challenge in this setting, which we term \textit{token selection ambiguity}, wherein visual AR models frequently assign uniformly low probabilities to tokens, hampering the performance of speculative decoding. To overcome this challenge, we propose a relaxed acceptance condition referred to as LANTERN that leverages the interchangeability of tokens in latent space. This relaxation restores the effectiveness of speculative decoding in visual AR models by enabling more flexible use of candidate tokens that would otherwise be prematurely rejected. Furthermore, by incorporating a total variation distance bound, we ensure that these speed gains are achieved without significantly compromising image quality or semantic coherence. Experimental results demonstrate the efficacy of our method in providing a substantial speed-up over speculative decoding. In specific, compared to a na\"ive application of the state-of-the-art speculative decoding, LANTERN increases speed-ups by $\mathbf{1.75}\times$ and $\mathbf{1.76}\times$, as compared to greedy decoding and random sampling, respectively, when applied to LlamaGen, a contemporary visual AR model.
PruNeRF: Segment-Centric Dataset Pruning via 3D Spatial Consistency
Jun 02, 2024



Neural Radiance Fields (NeRF) have shown remarkable performance in learning 3D scenes. However, NeRF exhibits vulnerability when confronted with distractors in the training images -- unexpected objects are present only within specific views, such as moving entities like pedestrians or birds. Excluding distractors during dataset construction is a straightforward solution, but without prior knowledge of their types and quantities, it becomes prohibitively expensive. In this paper, we propose PruNeRF, a segment-centric dataset pruning framework via 3D spatial consistency, that effectively identifies and prunes the distractors. We first examine existing metrics for measuring pixel-wise distraction and introduce Influence Functions for more accurate measurements. Then, we assess 3D spatial consistency using a depth-based reprojection technique to obtain 3D-aware distraction. Furthermore, we incorporate segmentation for pixel-to-segment refinement, enabling more precise identification. Our experiments on benchmark datasets demonstrate that PruNeRF consistently outperforms state-of-the-art methods in robustness against distractors.
Fighting Fire with Fire: Contrastive Debiasing without Bias-free Data via Generative Bias-transformation
Dec 02, 2021

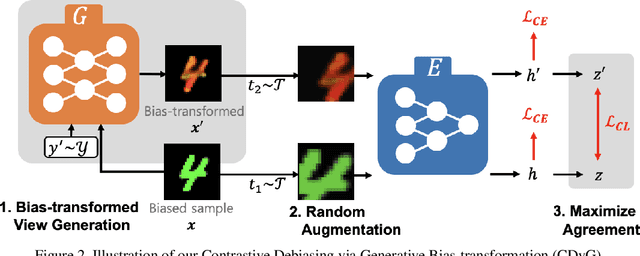
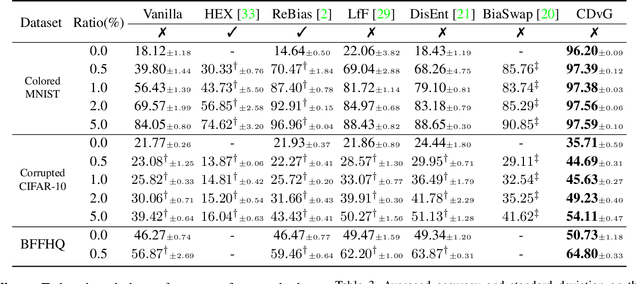
Despite their remarkable ability to generalize with over-capacity networks, deep neural networks often learn to abuse spurious biases in the data instead of using the actual task-related information. Since such shortcuts are only effective within the collected dataset, the resulting biased model underperforms on real-world inputs, or cause unintended social repercussions such as gender discrimination. To counteract the influence of bias, existing methods either exploit auxiliary information which is rarely obtainable in practice, or sift for bias-free samples in the training data, hoping for the sufficient existence of clean samples. However, such presumptions about the data are not always guaranteed. In this paper, we propose Contrastive Debiasing via Generative Bias-transformation~(CDvG) which is capable of operating in more general environments where existing methods break down due to unmet presumptions such as insufficient bias-free samples. Motivated by our observation that not only discriminative models, as previously known, but also generative models tend to focus on the bias when possible, CDvG uses a translation model to transform the bias in the sample to another mode of bias while preserving task-relevant information. Through contrastive learning, we set transformed biased views against another, learning bias-invariant representations. Experimental results on synthetic and real-world datasets demonstrate that our framework outperforms the current state-of-the-arts, and effectively prevents the models from being biased even when bias-free samples are extremely scarce.