 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Remedy for Dataset Bias via Self-Influence: A Mislabeled Sample Perspective
Nov 01, 2024Learning generalized models from biased data is an important undertaking toward fairness in deep learning. To address this issue, recent studies attempt to identify and leverage bias-conflicting samples free from spurious correlations without prior knowledge of bias or an unbiased set. However, spurious correlation remains an ongoing challenge, primarily due to the difficulty in precisely detecting these samples. In this paper, inspired by the similarities between mislabeled samples and bias-conflicting samples, we approach this challenge from a novel perspective of mislabeled sample detection. Specifically, we delve into Influence Function, one of the standard methods for mislabeled sample detection, for identifying bias-conflicting samples and propose a simple yet effective remedy for biased models by leveraging them. Through comprehensive analysis and experiments on diverse datasets, we demonstrate that our new perspective can boost the precision of detection and rectify biased models effectively. Furthermore, our approach is complementary to existing methods, showing performance improvement even when applied to models that have already undergone recent debiasing techniques.
TAM: Topology-Aware Margin Loss for Class-Imbalanced Node Classification
Jun 26, 2022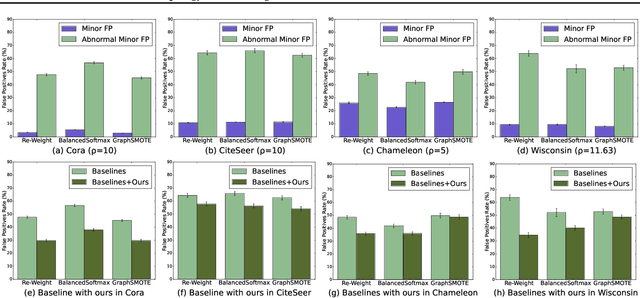
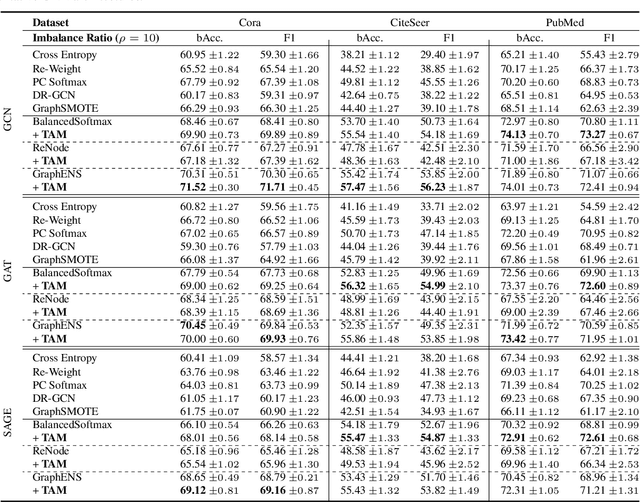
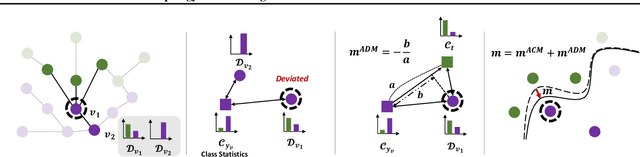
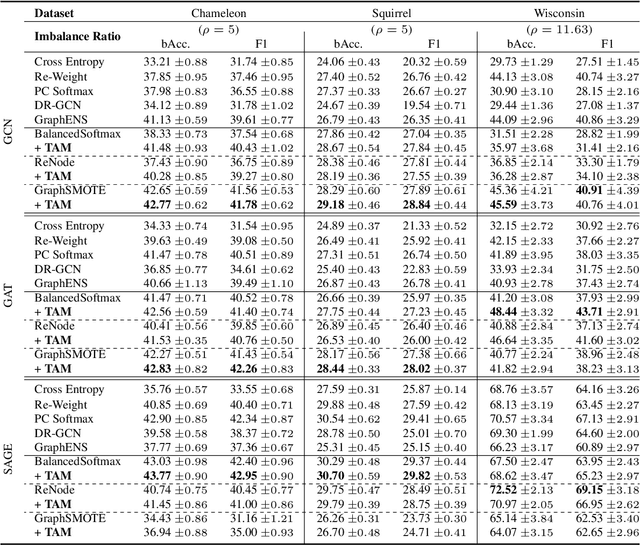
Learning unbiased node representations under class-imbalanced graph data is challenging due to interactions between adjacent nodes. Existing studies have in common that they compensate the minor class nodes `as a group' according to their overall quantity (ignoring node connections in graph), which inevitably increase the false positive cases for major nodes. We hypothesize that the increase in these false positive cases is highly affected by the label distribution around each node and confirm it experimentally. In addition, in order to handle this issue, we propose Topology-Aware Margin (TAM) to reflect local topology on the learning objective. Our method compares the connectivity pattern of each node with the class-averaged counter-part and adaptively adjusts the margin accordingly based on that. Our method consistently exhibits superiority over the baselines on various node classification benchmark datasets with representative GNN architectures.
Mutually-Constrained Monotonic Multihead Attention for Online ASR
Mar 26, 2021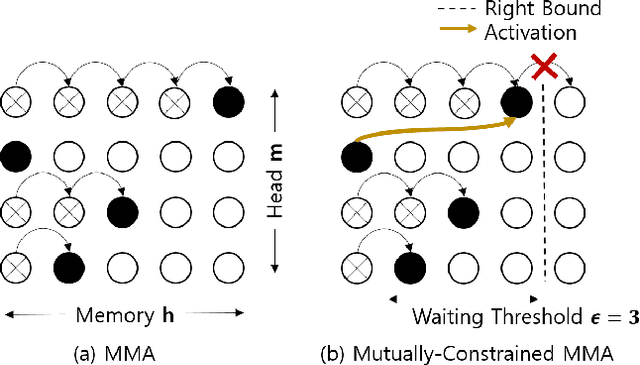
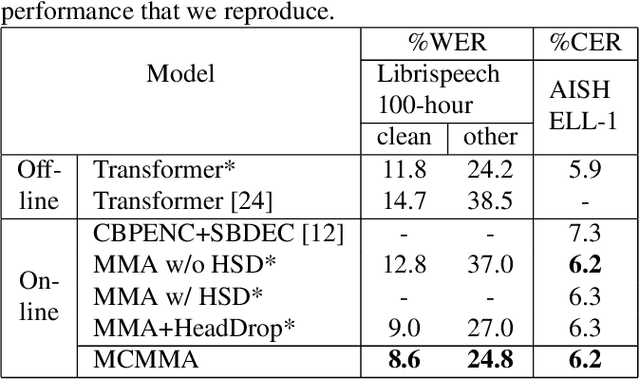
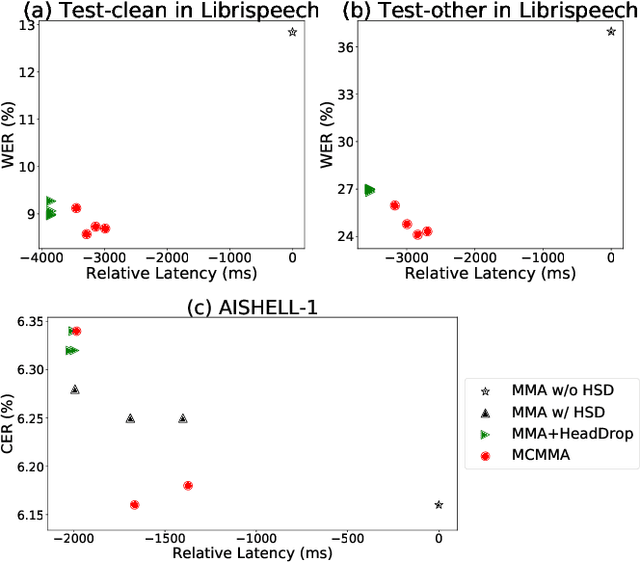
Despite the feature of real-time decoding, Monotonic Multihead Attention (MMA) shows comparable performance to the state-of-the-art offline methods in machine translation and automatic speech recognition (ASR) tasks. However, the latency of MMA is still a major issue in ASR and should be combined with a technique that can reduce the test latency at inference time, such as head-synchronous beam search decoding, which forces all non-activated heads to activate after a small fixed delay from the first head activation. In this paper, we remove the discrepancy between training and test phases by considering, in the training of MMA, the interactions across multiple heads that will occur in the test time. Specifically, we derive the expected alignments from monotonic attention by considering the boundaries of other heads and reflect them in the learning process. We validate our proposed method on the two standard benchmark datasets for ASR and show that our approach, MMA with the mutually-constrained heads from the training stage, provides better performance than baselines.