 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Timestep Zero-Shot Candidate Selection for Instruction-Guided Image Editing
Apr 18, 2025Despite recent advances in diffusion models, achieving reliable image generation and editing remains challenging due to the inherent diversity induced by stochastic noise in the sampling process. Instruction-guided image editing with diffusion models offers user-friendly capabilities, yet editing failures, such as background distortion, frequently occur. Users often resort to trial and error, adjusting seeds or prompts to achieve satisfactory results, which is inefficient. While seed selection methods exist for Text-to-Image (T2I) generation, they depend on external verifiers, limiting applicability, and evaluating multiple seeds increases computational complexity. To address this, we first establish a multiple-seed-based image editing baseline using background consistency scores, achieving Best-of-N performance without supervision. Building on this, we introduce ELECT (Early-timestep Latent Evaluation for Candidate Selection), a zero-shot framework that selects reliable seeds by estimating background mismatches at early diffusion timesteps, identifying the seed that retains the background while modifying only the foreground. ELECT ranks seed candidates by a background inconsistency score, filtering unsuitable samples early based on background consistency while preserving editability. Beyond standalone seed selection, ELECT integrates into instruction-guided editing pipelines and extends to Multimodal Large-Language Models (MLLMs) for joint seed and prompt selection, further improving results when seed selection alone is insufficient. Experiments show that ELECT reduces computational costs (by 41 percent on average and up to 61 percent) while improving background consistency and instruction adherence, achieving around 40 percent success rates in previously failed cases - without any external supervision or training.
Augmentation-Driven Metric for Balancing Preservation and Modification in Text-Guided Image Editing
Oct 15, 2024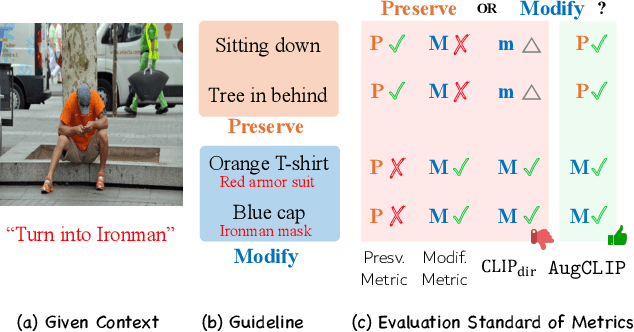

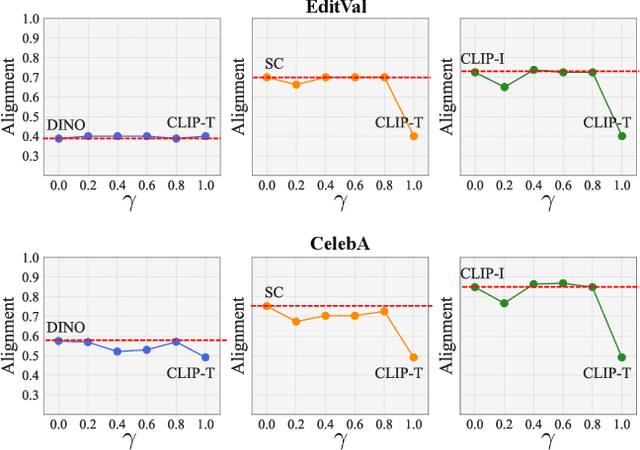
The development of vision-language and generative models has significantly advanced text-guided image editing, which seeks \textit{preservation} of core elements in the source image while implementing \textit{modifications} based on the target text. However, in the absence of evaluation metrics specifically tailored for text-guided image editing, existing metrics are limited in balancing the consideration of preservation and modification. Especially, our analysis reveals that CLIPScore, the most commonly used metric, tends to favor modification and ignore core attributes to be preserved, resulting in inaccurate evaluations. To address this problem, we propose \texttt{AugCLIP}, \black{which balances preservation and modification by estimating the representation of an ideal edited image that aligns with the target text with minimum alteration on the source image. We augment detailed textual descriptions on the source image and the target text using a multi-modal large language model, to model a hyperplane that separates CLIP space into source or target. The representation of the ideal edited image is an orthogonal projection of the source image into the hyperplane, which encapsulates the relative importance of each attribute considering the interdependent relationships.} Our extensive experiments on five benchmark datasets, encompassing a diverse range of editing scenarios, demonstrate that \texttt{AugCLIP} aligns remarkably well with human evaluation standards compared to existing metrics. The code for evaluation will be open-sourced to contribute to the community.