 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffine-Scaled Attention: Towards Flexible and Stable Transformer Attention
Feb 26, 2026Transformer attention is typically implemented using softmax normalization, which enforces attention weights with unit sum normalization. While effective in many settings, this constraint can limit flexibility in controlling attention magnitudes and may contribute to overly concentrated or unstable attention patterns during training. Prior work has explored modifications such as attention sinks or gating mechanisms, but these approaches provide only limited or indirect control over attention reweighting. We propose Affine-Scaled Attention, a simple extension to standard attention that introduces input-dependent scaling and a corresponding bias term applied to softmax-normalized attention weights. This design relaxes the strict normalization constraint while maintaining aggregation of value representations, allowing the model to adjust both the relative distribution and the scale of attention in a controlled manner. We empirically evaluate Affine-Scaled Attention in large-scale language model pretraining across multiple model sizes. Experimental results show consistent improvements in training stability, optimization behavior, and downstream task performance compared to standard softmax attention and attention sink baselines. These findings suggest that modest reweighting of attention outputs provides a practical and effective way to improve attention behavior in Transformer models.
CodeGEMM: A Codebook-Centric Approach to Efficient GEMM in Quantized LLMs
Dec 19, 2025Weight-only quantization is widely used to mitigate the memory-bound nature of LLM inference. Codebook-based methods extend this trend by achieving strong accuracy in the extremely low-bit regime (e.g., 2-bit). However, current kernels rely on dequantization, which repeatedly fetches centroids and reconstructs weights, incurring substantial latency and cache pressure. We present CodeGEMM, a codebook-centric GEMM kernel that replaces dequantization with precomputed inner products between centroids and activations stored in a lightweight Psumbook. At inference, code indices directly gather these partial sums, eliminating per-element lookups and reducing the on-chip footprint. The kernel supports the systematic exploration of latency-memory-accuracy trade-offs under a unified implementation. On Llama-3 models, CodeGEMM delivers 1.83x (8B) and 8.93x (70B) speedups in the 2-bit configuration compared to state-of-the-art codebook-based quantization at comparable accuracy and further improves computing efficiency and memory subsystem utilization.
An Investigation of FP8 Across Accelerators for LLM Inference
Feb 03, 2025



The introduction of 8-bit floating-point (FP8) computation units in modern AI accelerators has generated significant interest in FP8-based large language model (LLM) inference. Unlike 16-bit floating-point formats, FP8 in deep learning requires a shared scaling factor. Additionally, while E4M3 and E5M2 are well-defined at the individual value level, their scaling and accumulation methods remain unspecified and vary across hardware and software implementations. As a result, FP8 behaves more like a quantization format than a standard numeric representation. In this work, we provide the first comprehensive analysis of FP8 computation and acceleration on two AI accelerators: the NVIDIA H100 and Intel Gaudi 2. Our findings highlight that the Gaudi 2, by leveraging FP8, achieves higher throughput-to-power efficiency during LLM inference, offering valuable insights into the practical implications of FP8 adoption for datacenter-scale LLM serving.
No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization
Feb 28, 2024



Key-Value (KV) Caching has become an essential technique for accelerating the inference speed and throughput of generative Large Language Models~(LLMs). However, the memory footprint of the KV cache poses a critical bottleneck in LLM deployment as the cache size grows with batch size and sequence length, often surpassing even the size of the model itself. Although recent methods were proposed to select and evict unimportant KV pairs from the cache to reduce memory consumption, the potential ramifications of eviction on the generative process are yet to be thoroughly examined. In this paper, we examine the detrimental impact of cache eviction and observe that unforeseen risks arise as the information contained in the KV pairs is exhaustively discarded, resulting in safety breaches, hallucinations, and context loss. Surprisingly, we find that preserving even a small amount of information contained in the evicted KV pairs via reduced precision quantization substantially recovers the incurred degradation. On the other hand, we observe that the important KV pairs must be kept at a relatively higher precision to safeguard the generation quality. Motivated by these observations, we propose \textit{Mixed-precision KV cache}~(MiKV), a reliable cache compression method that simultaneously preserves the context details by retaining the evicted KV pairs in low-precision and ensure generation quality by keeping the important KV pairs in high-precision. Experiments on diverse benchmarks and LLM backbones show that our proposed method offers a state-of-the-art trade-off between compression ratio and performance, compared to other baselines.
nuQmm: Quantized MatMul for Efficient Inference of Large-Scale Generative Language Models
Jun 20, 2022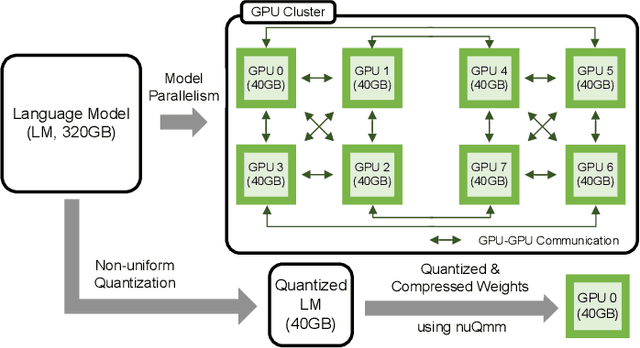
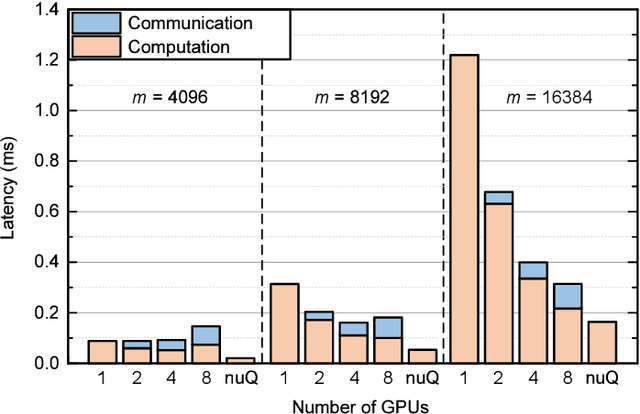
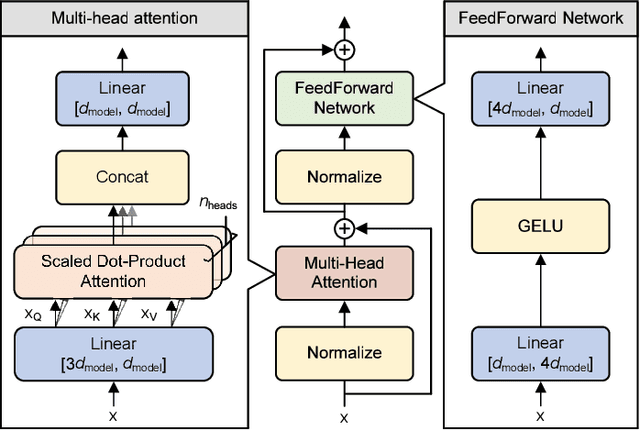
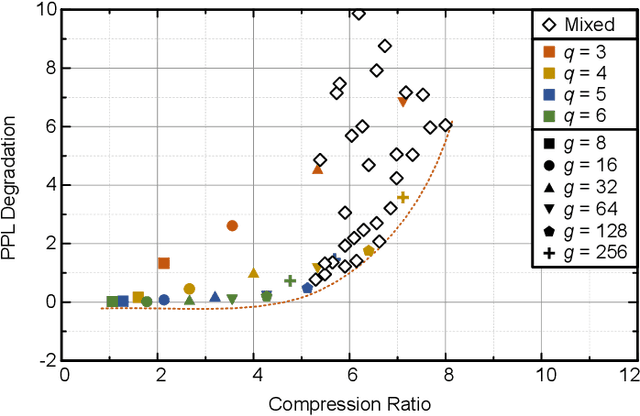
The recent advance of self-supervised learning associated with the Transformer architecture enables natural language processing (NLP) to exhibit extremely low perplexity. Such powerful models demand ever-increasing model size, and thus, large amounts of computations and memory footprints. In this paper, we propose an efficient inference framework for large-scale generative language models. As the key to reducing model size, we quantize weights by a non-uniform quantization method. Then, quantized matrix multiplications are accelerated by our proposed kernel, called nuQmm, which allows a wide trade-off between compression ratio and accuracy. Our proposed nuQmm reduces the latency of not only each GPU but also the entire inference of large LMs because a high compression ratio (by low-bit quantization) mitigates the minimum required number of GPUs. We demonstrate that nuQmm can accelerate the inference speed of the GPT-3 (175B) model by about 14.4 times and save energy consumption by 93%.