 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenuQmm: Quantized MatMul for Efficient Inference of Large-Scale Generative Language Models
Paper and Code
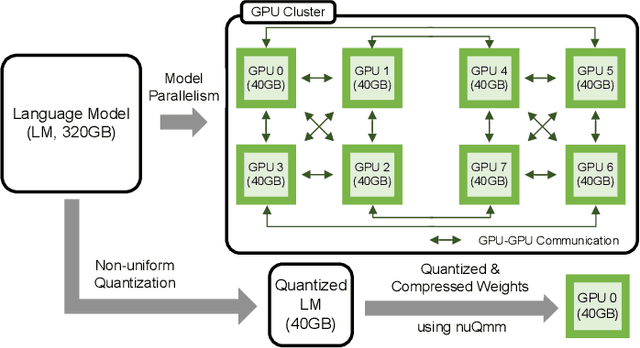
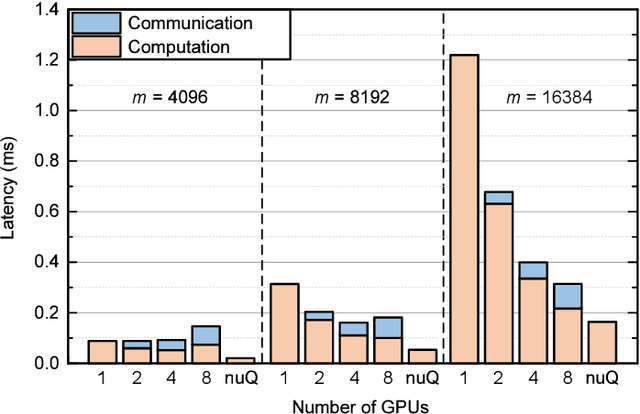
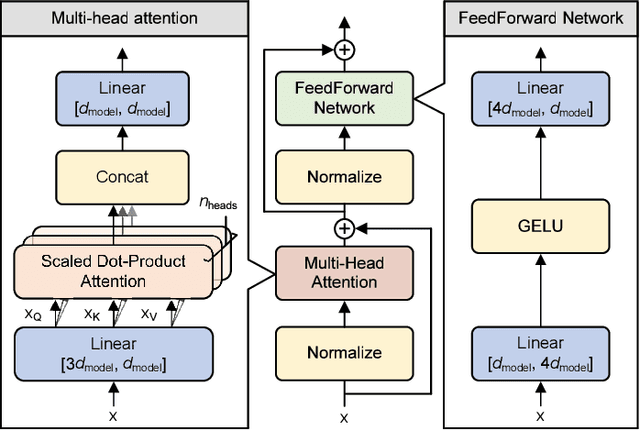
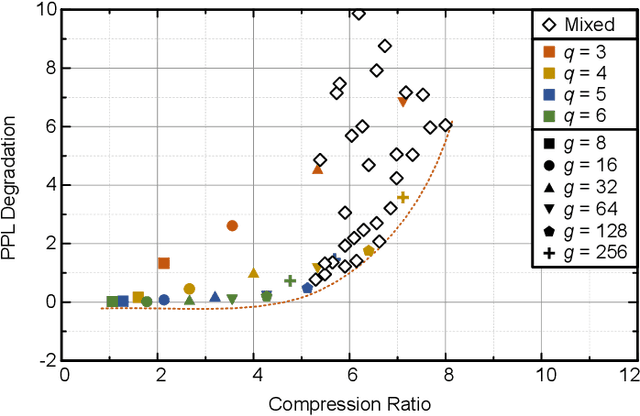
The recent advance of self-supervised learning associated with the Transformer architecture enables natural language processing (NLP) to exhibit extremely low perplexity. Such powerful models demand ever-increasing model size, and thus, large amounts of computations and memory footprints. In this paper, we propose an efficient inference framework for large-scale generative language models. As the key to reducing model size, we quantize weights by a non-uniform quantization method. Then, quantized matrix multiplications are accelerated by our proposed kernel, called nuQmm, which allows a wide trade-off between compression ratio and accuracy. Our proposed nuQmm reduces the latency of not only each GPU but also the entire inference of large LMs because a high compression ratio (by low-bit quantization) mitigates the minimum required number of GPUs. We demonstrate that nuQmm can accelerate the inference speed of the GPT-3 (175B) model by about 14.4 times and save energy consumption by 93%.