 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of FP8 Across Accelerators for LLM Inference
Feb 03, 2025



The introduction of 8-bit floating-point (FP8) computation units in modern AI accelerators has generated significant interest in FP8-based large language model (LLM) inference. Unlike 16-bit floating-point formats, FP8 in deep learning requires a shared scaling factor. Additionally, while E4M3 and E5M2 are well-defined at the individual value level, their scaling and accumulation methods remain unspecified and vary across hardware and software implementations. As a result, FP8 behaves more like a quantization format than a standard numeric representation. In this work, we provide the first comprehensive analysis of FP8 computation and acceleration on two AI accelerators: the NVIDIA H100 and Intel Gaudi 2. Our findings highlight that the Gaudi 2, by leveraging FP8, achieves higher throughput-to-power efficiency during LLM inference, offering valuable insights into the practical implications of FP8 adoption for datacenter-scale LLM serving.
Panacea: Novel DNN Accelerator using Accuracy-Preserving Asymmetric Quantization and Energy-Saving Bit-Slice Sparsity
Dec 13, 2024



Low bit-precisions and their bit-slice sparsity have recently been studied to accelerate general matrix-multiplications (GEMM) during large-scale deep neural network (DNN) inferences. While the conventional symmetric quantization facilitates low-resolution processing with bit-slice sparsity for both weight and activation, its accuracy loss caused by the activation's asymmetric distributions cannot be acceptable, especially for large-scale DNNs. In efforts to mitigate this accuracy loss, recent studies have actively utilized asymmetric quantization for activations without requiring additional operations. However, the cutting-edge asymmetric quantization produces numerous nonzero slices that cannot be compressed and skipped by recent bit-slice GEMM accelerators, naturally consuming more processing energy to handle the quantized DNN models. To simultaneously achieve high accuracy and hardware efficiency for large-scale DNN inferences, this paper proposes an Asymmetrically-Quantized bit-Slice GEMM (AQS-GEMM) for the first time. In contrast to the previous bit-slice computing, which only skips operations of zero slices, the AQS-GEMM compresses frequent nonzero slices, generated by asymmetric quantization, and skips their operations. To increase the slice-level sparsity of activations, we also introduce two algorithm-hardware co-optimization methods: a zero-point manipulation and a distribution-based bit-slicing. To support the proposed AQS-GEMM and optimizations at the hardware-level, we newly introduce a DNN accelerator, Panacea, which efficiently handles sparse/dense workloads of the tiled AQS-GEMM to increase data reuse and utilization. Panacea supports a specialized dataflow and run-length encoding to maximize data reuse and minimize external memory accesses, significantly improving its hardware efficiency. Our benchmark evaluations show Panacea outperforms existing DNN accelerators.
A reproducible 3D convolutional neural network with dual attention module (3D-DAM) for Alzheimer's disease classification
Oct 19, 2023Alzheimer's disease is one of the most common types of neurodegenerative disease, characterized by the accumulation of amyloid-beta plaque and tau tangles. Recently, deep learning approaches have shown promise in Alzheimer's disease diagnosis. In this study, we propose a reproducible model that utilizes a 3D convolutional neural network with a dual attention module for Alzheimer's disease classification. We trained the model in the ADNI database and verified the generalizability of our method in two independent datasets (AIBL and OASIS1). Our method achieved state-of-the-art classification performance, with an accuracy of 91.94% for MCI progression classification and 96.30% for Alzheimer's disease classification on the ADNI dataset. Furthermore, the model demonstrated good generalizability, achieving an accuracy of 86.37% on the AIBL dataset and 83.42% on the OASIS1 dataset. These results indicate that our proposed approach has competitive performance and generalizability when compared to recent studies in the field.
nuQmm: Quantized MatMul for Efficient Inference of Large-Scale Generative Language Models
Jun 20, 2022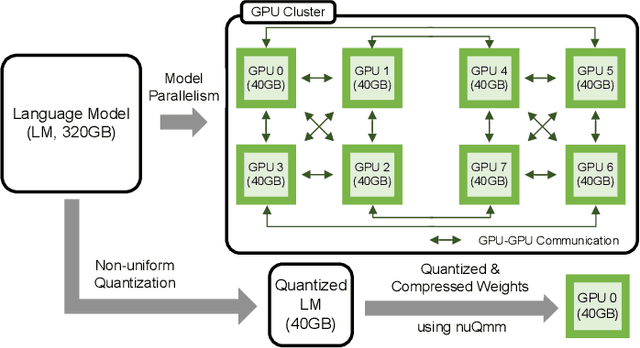
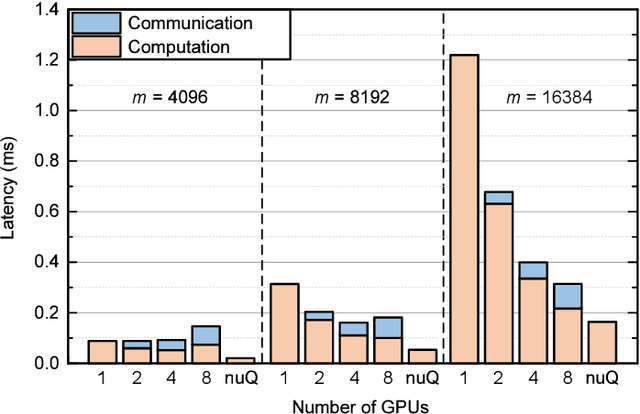
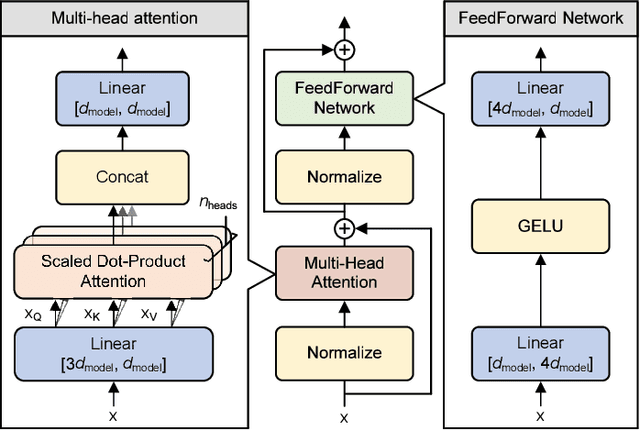
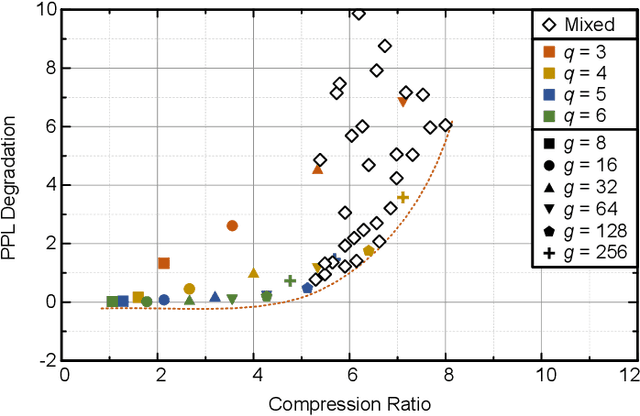
The recent advance of self-supervised learning associated with the Transformer architecture enables natural language processing (NLP) to exhibit extremely low perplexity. Such powerful models demand ever-increasing model size, and thus, large amounts of computations and memory footprints. In this paper, we propose an efficient inference framework for large-scale generative language models. As the key to reducing model size, we quantize weights by a non-uniform quantization method. Then, quantized matrix multiplications are accelerated by our proposed kernel, called nuQmm, which allows a wide trade-off between compression ratio and accuracy. Our proposed nuQmm reduces the latency of not only each GPU but also the entire inference of large LMs because a high compression ratio (by low-bit quantization) mitigates the minimum required number of GPUs. We demonstrate that nuQmm can accelerate the inference speed of the GPT-3 (175B) model by about 14.4 times and save energy consumption by 93%.
GROW: A Row-Stationary Sparse-Dense GEMM Accelerator for Memory-Efficient Graph Convolutional Neural Networks
Mar 02, 2022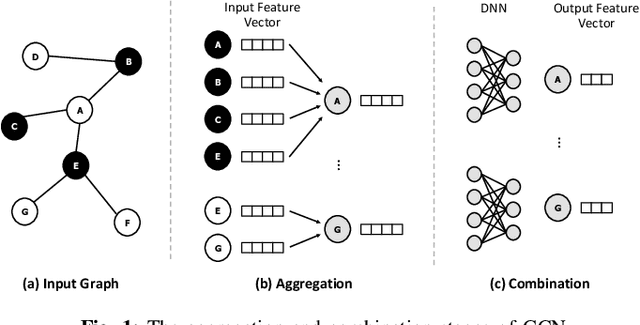
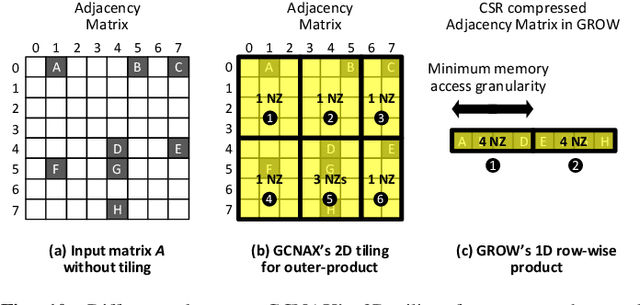
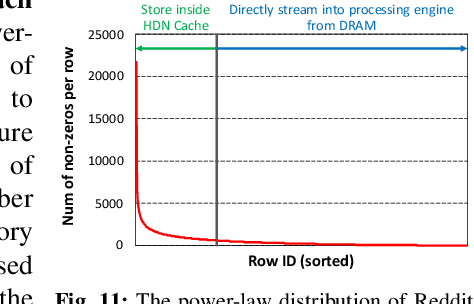
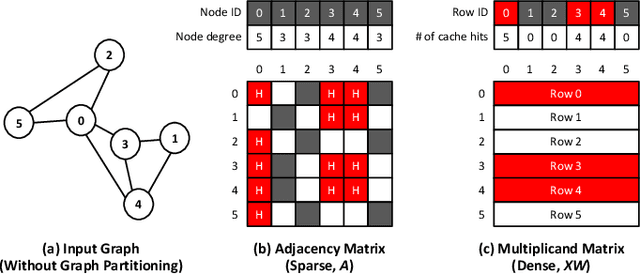
Graph convolutional neural networks (GCNs) have emerged as a key technology in various application domains where the input data is relational. A unique property of GCNs is that its two primary execution stages, aggregation and combination, exhibit drastically different dataflows. Consequently, prior GCN accelerators tackle this research space by casting the aggregation and combination stages as a series of sparse-dense matrix multiplication. However, prior work frequently suffers from inefficient data movements, leaving significant performance left on the table. We present GROW, a GCN accelerator based on Gustavson's algorithm to architect a row-wise product based sparse-dense GEMM accelerator. GROW co-designs the software/hardware that strikes a balance in locality and parallelism for GCNs, achieving significant energy-efficiency improvements vs. state-of-the-art GCN accelerators.
Selective Deep Convolutional Neural Network for Low Cost Distorted Image Classification
Jul 04, 2018
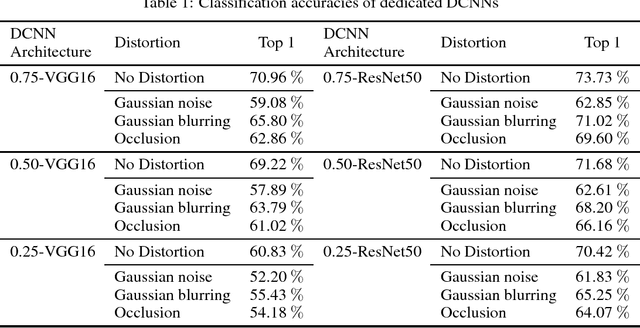

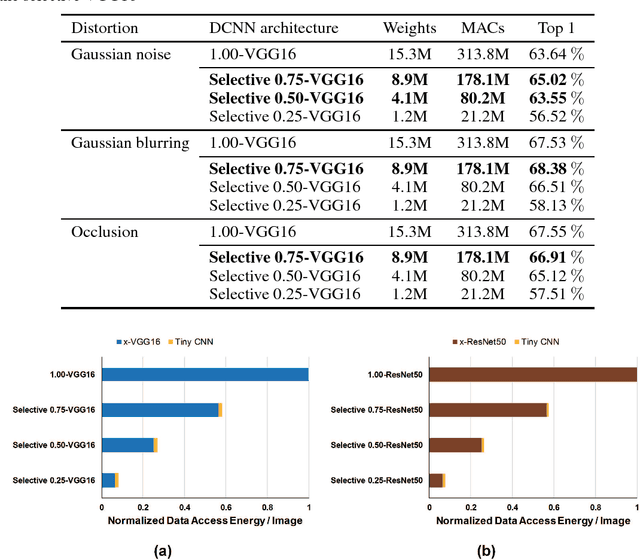
Deep convolutional neural networks have proven to be well suited for image classification applications. However, if there is distortion in the image, the classification accuracy can be significantly degraded, even with state-of-the-art neural networks. The accuracy cannot be significantly improved by simply training with distorted images. Instead, this paper proposes a multiple neural network topology referred to as a selective deep convolutional neural network. By modifying existing state-of-the-art neural networks in the proposed manner, it is shown that a similar level of classification accuracy can be achieved, but at a significantly lower cost. The cost reduction is obtained primarily through the use of fewer weight parameters. Using fewer weights reduces the number of multiply-accumulate operations and also reduces the energy required for data accesses. Finally, it is shown that the effectiveness of the proposed selective deep convolutional neural network can be further improved by combining it with previously proposed network cost reduction methods.