 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual MPC: Blending Reinforcement Learning with GPU-Parallelized Model Predictive Control
Oct 14, 2025



Model Predictive Control (MPC) provides interpretable, tunable locomotion controllers grounded in physical models, but its robustness depends on frequent replanning and is limited by model mismatch and real-time computational constraints. Reinforcement Learning (RL), by contrast, can produce highly robust behaviors through stochastic training but often lacks interpretability, suffers from out-of-distribution failures, and requires intensive reward engineering. This work presents a GPU-parallelized residual architecture that tightly integrates MPC and RL by blending their outputs at the torque-control level. We develop a kinodynamic whole-body MPC formulation evaluated across thousands of agents in parallel at 100 Hz for RL training. The residual policy learns to make targeted corrections to the MPC outputs, combining the interpretability and constraint handling of model-based control with the adaptability of RL. The model-based control prior acts as a strong bias, initializing and guiding the policy towards desirable behavior with a simple set of rewards. Compared to standalone MPC or end-to-end RL, our approach achieves higher sample efficiency, converges to greater asymptotic rewards, expands the range of trackable velocity commands, and enables zero-shot adaptation to unseen gaits and uneven terrain.
Panacea: Novel DNN Accelerator using Accuracy-Preserving Asymmetric Quantization and Energy-Saving Bit-Slice Sparsity
Dec 13, 2024



Low bit-precisions and their bit-slice sparsity have recently been studied to accelerate general matrix-multiplications (GEMM) during large-scale deep neural network (DNN) inferences. While the conventional symmetric quantization facilitates low-resolution processing with bit-slice sparsity for both weight and activation, its accuracy loss caused by the activation's asymmetric distributions cannot be acceptable, especially for large-scale DNNs. In efforts to mitigate this accuracy loss, recent studies have actively utilized asymmetric quantization for activations without requiring additional operations. However, the cutting-edge asymmetric quantization produces numerous nonzero slices that cannot be compressed and skipped by recent bit-slice GEMM accelerators, naturally consuming more processing energy to handle the quantized DNN models. To simultaneously achieve high accuracy and hardware efficiency for large-scale DNN inferences, this paper proposes an Asymmetrically-Quantized bit-Slice GEMM (AQS-GEMM) for the first time. In contrast to the previous bit-slice computing, which only skips operations of zero slices, the AQS-GEMM compresses frequent nonzero slices, generated by asymmetric quantization, and skips their operations. To increase the slice-level sparsity of activations, we also introduce two algorithm-hardware co-optimization methods: a zero-point manipulation and a distribution-based bit-slicing. To support the proposed AQS-GEMM and optimizations at the hardware-level, we newly introduce a DNN accelerator, Panacea, which efficiently handles sparse/dense workloads of the tiled AQS-GEMM to increase data reuse and utilization. Panacea supports a specialized dataflow and run-length encoding to maximize data reuse and minimize external memory accesses, significantly improving its hardware efficiency. Our benchmark evaluations show Panacea outperforms existing DNN accelerators.
CusADi: A GPU Parallelization Framework for Symbolic Expressions and Optimal Control
Aug 19, 2024
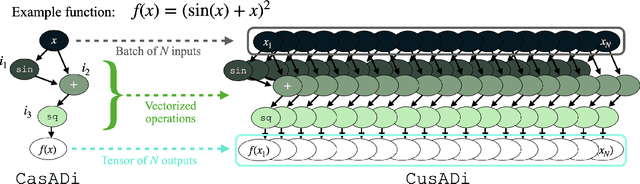
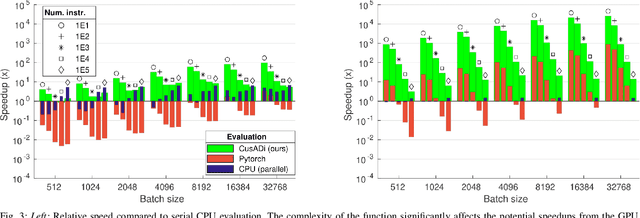
The parallelism afforded by GPUs presents significant advantages in training controllers through reinforcement learning (RL). However, integrating model-based optimization into this process remains challenging due to the complexity of formulating and solving optimization problems across thousands of instances. In this work, we present CusADi, an extension of the CasADi symbolic framework to support the parallelization of arbitrary closed-form expressions on GPUs with CUDA. We also formulate a closed-form approximation for solving general optimal control problems, enabling large-scale parallelization and evaluation of MPC controllers. Our results show a ten-fold speedup relative to similar MPC implementation on the CPU, and we demonstrate the use of CusADi for various applications, including parallel simulation, parameter sweeps, and policy training.
Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning for Dynamic Legged Locomotion
Aug 05, 2024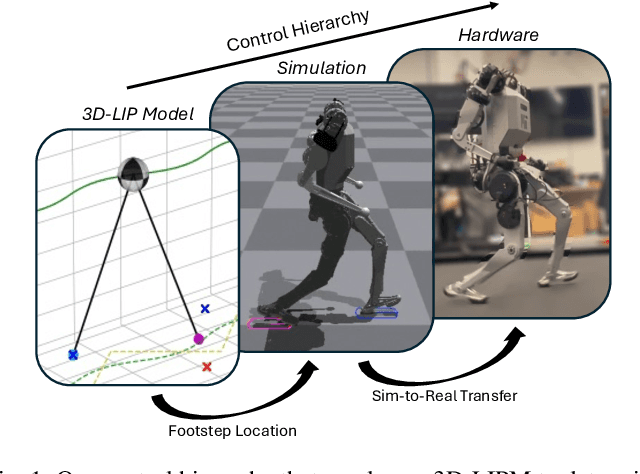
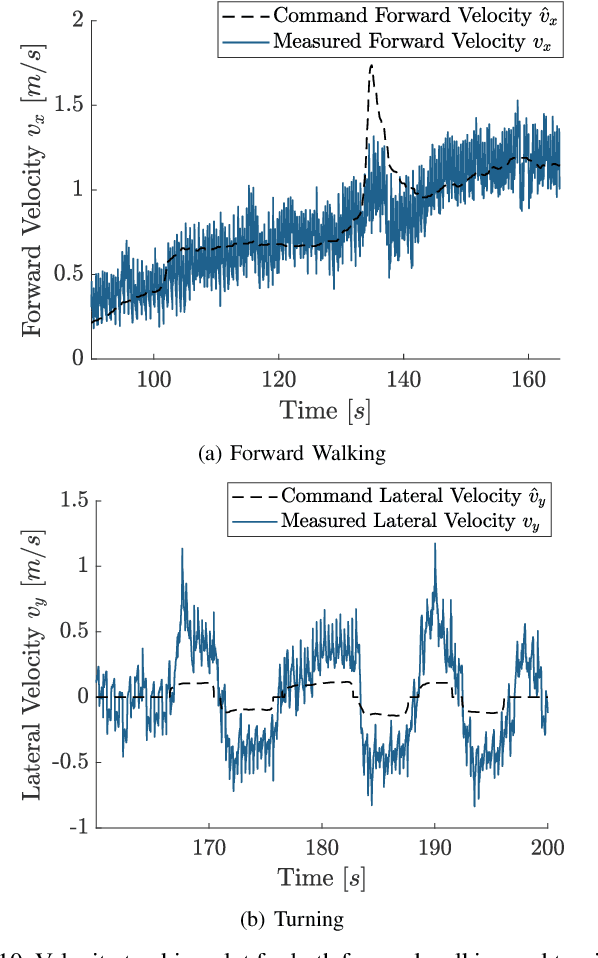
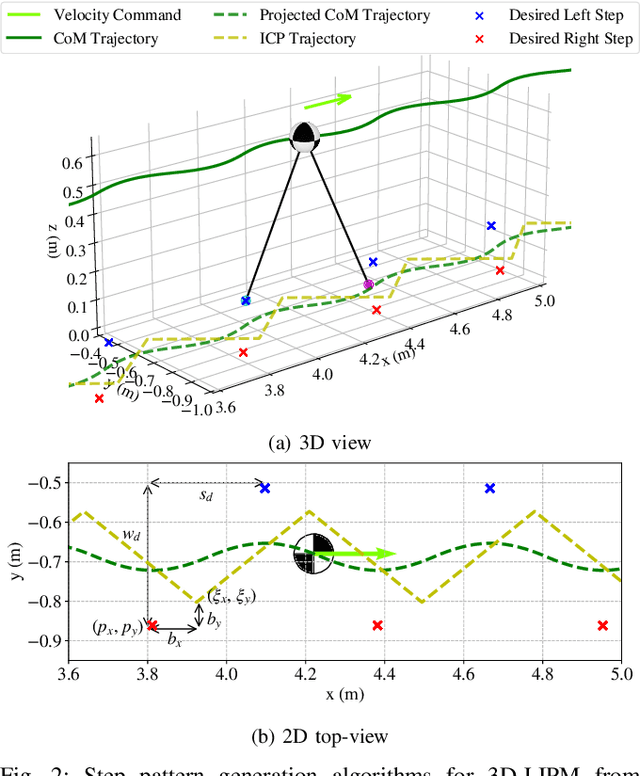
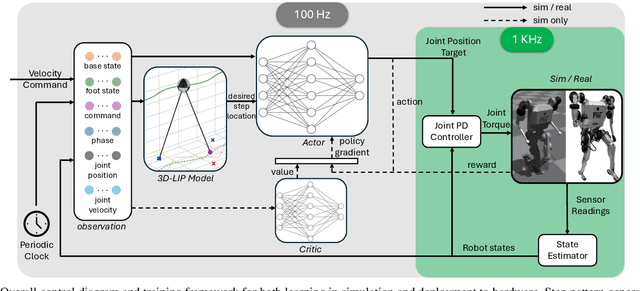
In this work, we introduce a control framework that combines model-based footstep planning with Reinforcement Learning (RL), leveraging desired footstep patterns derived from the Linear Inverted Pendulum (LIP) dynamics. Utilizing the LIP model, our method forward predicts robot states and determines the desired foot placement given the velocity commands. We then train an RL policy to track the foot placements without following the full reference motions derived from the LIP model. This partial guidance from the physics model allows the RL policy to integrate the predictive capabilities of the physics-informed dynamics and the adaptability characteristics of the RL controller without overfitting the policy to the template model. Our approach is validated on the MIT Humanoid, demonstrating that our policy can achieve stable yet dynamic locomotion for walking and turning. We further validate the adaptability and generalizability of our policy by extending the locomotion task to unseen, uneven terrain. During the hardware deployment, we have achieved forward walking speeds of up to 1.5 m/s on a treadmill and have successfully performed dynamic locomotion maneuvers such as 90-degree and 180-degree turns.
Tailoring Solution Accuracy for Fast Whole-body Model Predictive Control of Legged Robots
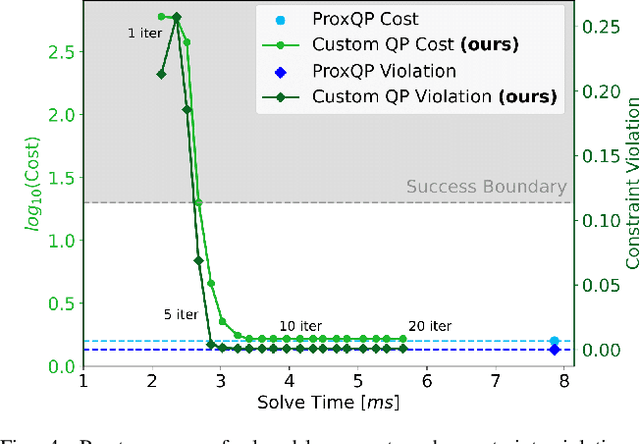
Jul 15, 2024Thanks to recent advancements in accelerating non-linear model predictive control (NMPC), it is now feasible to deploy whole-body NMPC at real-time rates for humanoid robots. However, enforcing inequality constraints in real time for such high-dimensional systems remains challenging due to the need for additional iterations. This paper presents an implementation of whole-body NMPC for legged robots that provides low-accuracy solutions to NMPC with general equality and inequality constraints. Instead of aiming for highly accurate optimal solutions, we leverage the alternating direction method of multipliers to rapidly provide low-accuracy solutions to quadratic programming subproblems. Our extensive simulation results indicate that real robots often cannot benefit from highly accurate solutions due to dynamics discretization errors, inertial modeling errors and delays. We incorporate control barrier functions (CBFs) at the initial timestep of the NMPC for the self-collision constraints, resulting in up to a 26-fold reduction in the number of self-collisions without adding computational burden. The controller is reliably deployed on hardware at 90 Hz for a problem involving 32 timesteps, 2004 variables, and 3768 constraints. The NMPC delivers sufficiently accurate solutions, enabling the MIT Humanoid to plan complex crossed-leg and arm motions that enhance stability when walking and recovering from significant disturbances.
Contact-Implicit MPC: Controlling Diverse Quadruped Motions Without Pre-Planned Contact Modes or Trajectories
Dec 14, 2023



This paper presents a contact-implicit model predictive control (MPC) framework for the real-time discovery of multi-contact motions, without predefined contact mode sequences or foothold positions. This approach utilizes the contact-implicit differential dynamic programming (DDP) framework, merging the hard contact model with a linear complementarity constraint. We propose the analytical gradient of the contact impulse based on relaxed complementarity constraints to further the exploration of a variety of contact modes. By leveraging a hard contact model-based simulation and computation of search direction through a smooth gradient, our methodology identifies dynamically feasible state trajectories, control inputs, and contact forces while simultaneously unveiling new contact mode sequences. However, the broadened scope of contact modes does not always ensure real-world applicability. Recognizing this, we implemented differentiable cost terms to guide foot trajectories and make gait patterns. Furthermore, to address the challenge of unstable initial roll-outs in an MPC setting, we employ the multiple shooting variant of DDP. The efficacy of the proposed framework is validated through simulations and real-world demonstrations using a 45 kg HOUND quadruped robot, performing various tasks in simulation and showcasing actual experiments involving a forward trot and a front-leg rearing motion.