 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual MPC: Blending Reinforcement Learning with GPU-Parallelized Model Predictive Control
Oct 14, 2025



Model Predictive Control (MPC) provides interpretable, tunable locomotion controllers grounded in physical models, but its robustness depends on frequent replanning and is limited by model mismatch and real-time computational constraints. Reinforcement Learning (RL), by contrast, can produce highly robust behaviors through stochastic training but often lacks interpretability, suffers from out-of-distribution failures, and requires intensive reward engineering. This work presents a GPU-parallelized residual architecture that tightly integrates MPC and RL by blending their outputs at the torque-control level. We develop a kinodynamic whole-body MPC formulation evaluated across thousands of agents in parallel at 100 Hz for RL training. The residual policy learns to make targeted corrections to the MPC outputs, combining the interpretability and constraint handling of model-based control with the adaptability of RL. The model-based control prior acts as a strong bias, initializing and guiding the policy towards desirable behavior with a simple set of rewards. Compared to standalone MPC or end-to-end RL, our approach achieves higher sample efficiency, converges to greater asymptotic rewards, expands the range of trackable velocity commands, and enables zero-shot adaptation to unseen gaits and uneven terrain.
Making Physical Objects with Generative AI and Robotic Assembly: Considering Fabrication Constraints, Sustainability, Time, Functionality, and Accessibility
Apr 27, 2025

3D generative AI enables rapid and accessible creation of 3D models from text or image inputs. However, translating these outputs into physical objects remains a challenge due to the constraints in the physical world. Recent studies have focused on improving the capabilities of 3D generative AI to produce fabricable outputs, with 3D printing as the main fabrication method. However, this workshop paper calls for a broader perspective by considering how fabrication methods align with the capabilities of 3D generative AI. As a case study, we present a novel system using discrete robotic assembly and 3D generative AI to make physical objects. Through this work, we identified five key aspects to consider in a physical making process based on the capabilities of 3D generative AI. 1) Fabrication Constraints: Current text-to-3D models can generate a wide range of 3D designs, requiring fabrication methods that can adapt to the variability of generative AI outputs. 2) Time: While generative AI can generate 3D models in seconds, fabricating physical objects can take hours or even days. Faster production could enable a closer iterative design loop between humans and AI in the making process. 3) Sustainability: Although text-to-3D models can generate thousands of models in the digital world, extending this capability to the real world would be resource-intensive, unsustainable and irresponsible. 4) Functionality: Unlike digital outputs from 3D generative AI models, the fabrication method plays a crucial role in the usability of physical objects. 5) Accessibility: While generative AI simplifies 3D model creation, the need for fabrication equipment can limit participation, making AI-assisted creation less inclusive. These five key aspects provide a framework for assessing how well a physical making process aligns with the capabilities of 3D generative AI and values in the world.
Speech to Reality: On-Demand Production using Natural Language, 3D Generative AI, and Discrete Robotic Assembly
Sep 27, 2024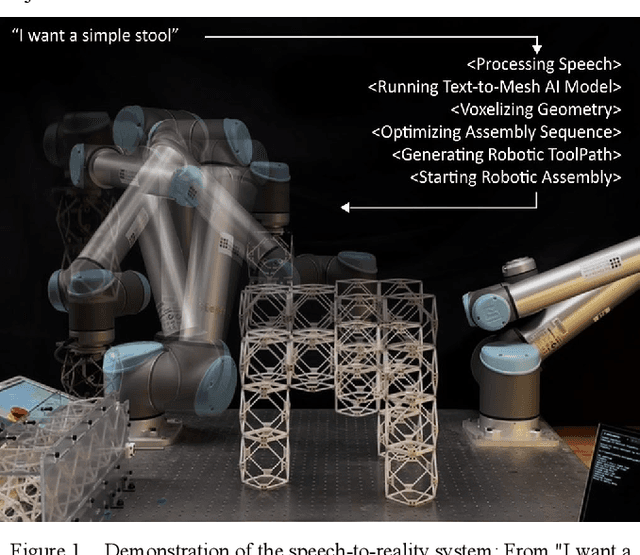
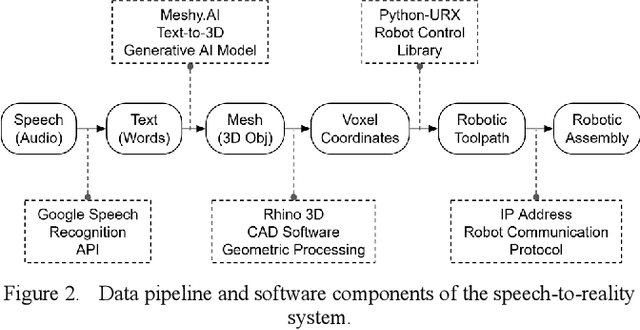

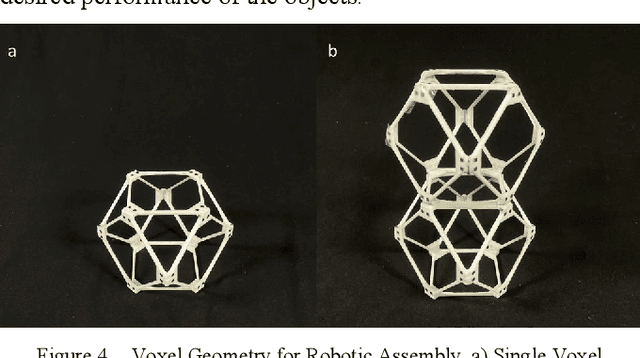
We present a system that transforms speech into physical objects by combining 3D generative Artificial Intelligence with robotic assembly. The system leverages natural language input to make design and manufacturing more accessible, enabling individuals without expertise in 3D modeling or robotic programming to create physical objects. We propose utilizing discrete robotic assembly of lattice-based voxel components to address the challenges of using generative AI outputs in physical production, such as design variability, fabrication speed, structural integrity, and material waste. The system interprets speech to generate 3D objects, discretizes them into voxel components, computes an optimized assembly sequence, and generates a robotic toolpath. The results are demonstrated through the assembly of various objects, ranging from chairs to shelves, which are prompted via speech and realized within 5 minutes using a 6-axis robotic arm.
CusADi: A GPU Parallelization Framework for Symbolic Expressions and Optimal Control
Aug 19, 2024
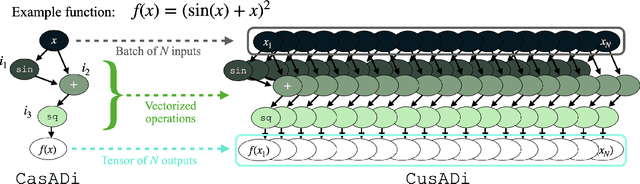
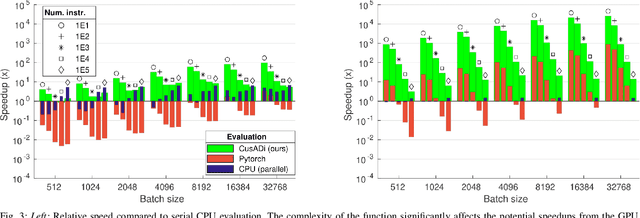
The parallelism afforded by GPUs presents significant advantages in training controllers through reinforcement learning (RL). However, integrating model-based optimization into this process remains challenging due to the complexity of formulating and solving optimization problems across thousands of instances. In this work, we present CusADi, an extension of the CasADi symbolic framework to support the parallelization of arbitrary closed-form expressions on GPUs with CUDA. We also formulate a closed-form approximation for solving general optimal control problems, enabling large-scale parallelization and evaluation of MPC controllers. Our results show a ten-fold speedup relative to similar MPC implementation on the CPU, and we demonstrate the use of CusADi for various applications, including parallel simulation, parameter sweeps, and policy training.
Learning Emergent Gaits with Decentralized Phase Oscillators: on the role of Observations, Rewards, and Feedback
Feb 17, 2024



We present a minimal phase oscillator model for learning quadrupedal locomotion. Each of the four oscillators is coupled only to itself and its corresponding leg through local feedback of the ground reaction force, which can be interpreted as an observer feedback gain. We interpret the oscillator itself as a latent contact state-estimator. Through a systematic ablation study, we show that the combination of phase observations, simple phase-based rewards, and the local feedback dynamics induces policies that exhibit emergent gait preferences, while using a reduced set of simple rewards, and without prescribing a specific gait. The code is open-source, and a video synopsis available at https://youtu.be/1NKQ0rSV3jU.
Benchmarking Potential Based Rewards for Learning Humanoid Locomotion
Jul 19, 2023The main challenge in developing effective reinforcement learning (RL) pipelines is often the design and tuning the reward functions. Well-designed shaping reward can lead to significantly faster learning. Naively formulated rewards, however, can conflict with the desired behavior and result in overfitting or even erratic performance if not properly tuned. In theory, the broad class of potential based reward shaping (PBRS) can help guide the learning process without affecting the optimal policy. Although several studies have explored the use of potential based reward shaping to accelerate learning convergence, most have been limited to grid-worlds and low-dimensional systems, and RL in robotics has predominantly relied on standard forms of reward shaping. In this paper, we benchmark standard forms of shaping with PBRS for a humanoid robot. We find that in this high-dimensional system, PBRS has only marginal benefits in convergence speed. However, the PBRS reward terms are significantly more robust to scaling than typical reward shaping approaches, and thus easier to tune.
Real-time Optimal Landing Control of the MIT Mini Cheetah
Oct 06, 2021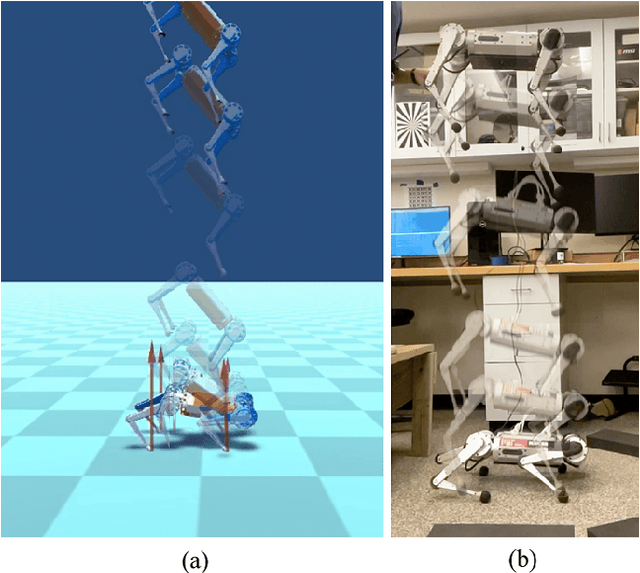
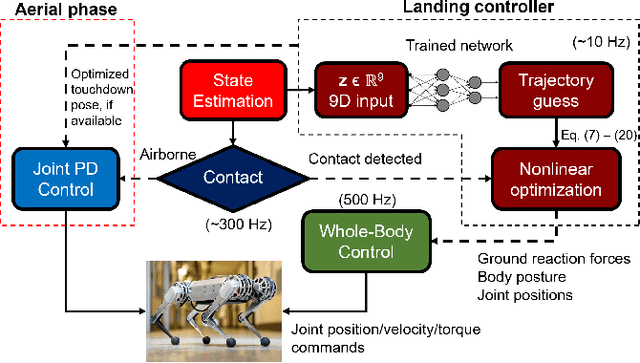

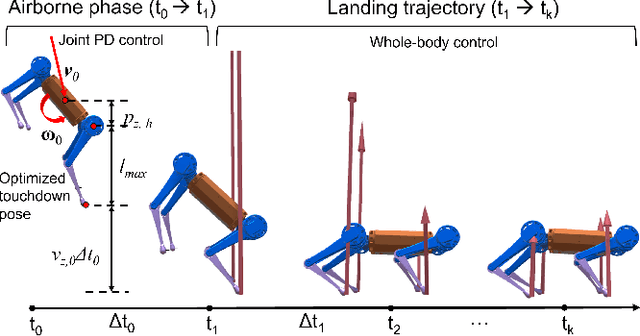
Quadrupedal landing is a complex process involving large impacts, elaborate contact transitions, and is a crucial recovery behavior observed in many biological animals. This work presents a real-time, optimal landing controller that is free of pre-specified contact schedules. The controller determines optimal touchdown postures and reaction force profiles and is able to recover from a variety of falling configurations. The quadrupedal platform used, the MIT Mini Cheetah, recovered safely from drops of up to 8 m in simulation, as well as from a range of orientations and planar velocities. The controller is also tested on hardware, successfully recovering from drops of up to 2 m.