 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLD: Fourier Latent Dynamics for Structured Motion Representation and Learning
Feb 21, 2024Motion trajectories offer reliable references for physics-based motion learning but suffer from sparsity, particularly in regions that lack sufficient data coverage. To address this challenge, we introduce a self-supervised, structured representation and generation method that extracts spatial-temporal relationships in periodic or quasi-periodic motions. The motion dynamics in a continuously parameterized latent space enable our method to enhance the interpolation and generalization capabilities of motion learning algorithms. The motion learning controller, informed by the motion parameterization, operates online tracking of a wide range of motions, including targets unseen during training. With a fallback mechanism, the controller dynamically adapts its tracking strategy and automatically resorts to safe action execution when a potentially risky target is proposed. By leveraging the identified spatial-temporal structure, our work opens new possibilities for future advancements in general motion representation and learning algorithms.
Learning Emergent Gaits with Decentralized Phase Oscillators: on the role of Observations, Rewards, and Feedback
Feb 17, 2024



We present a minimal phase oscillator model for learning quadrupedal locomotion. Each of the four oscillators is coupled only to itself and its corresponding leg through local feedback of the ground reaction force, which can be interpreted as an observer feedback gain. We interpret the oscillator itself as a latent contact state-estimator. Through a systematic ablation study, we show that the combination of phase observations, simple phase-based rewards, and the local feedback dynamics induces policies that exhibit emergent gait preferences, while using a reduced set of simple rewards, and without prescribing a specific gait. The code is open-source, and a video synopsis available at https://youtu.be/1NKQ0rSV3jU.
Benchmarking Potential Based Rewards for Learning Humanoid Locomotion
Jul 19, 2023The main challenge in developing effective reinforcement learning (RL) pipelines is often the design and tuning the reward functions. Well-designed shaping reward can lead to significantly faster learning. Naively formulated rewards, however, can conflict with the desired behavior and result in overfitting or even erratic performance if not properly tuned. In theory, the broad class of potential based reward shaping (PBRS) can help guide the learning process without affecting the optimal policy. Although several studies have explored the use of potential based reward shaping to accelerate learning convergence, most have been limited to grid-worlds and low-dimensional systems, and RL in robotics has predominantly relied on standard forms of reward shaping. In this paper, we benchmark standard forms of shaping with PBRS for a humanoid robot. We find that in this high-dimensional system, PBRS has only marginal benefits in convergence speed. However, the PBRS reward terms are significantly more robust to scaling than typical reward shaping approaches, and thus easier to tune.
Learning Fast and Precise Pixel-to-Torque Control
Aug 03, 2022
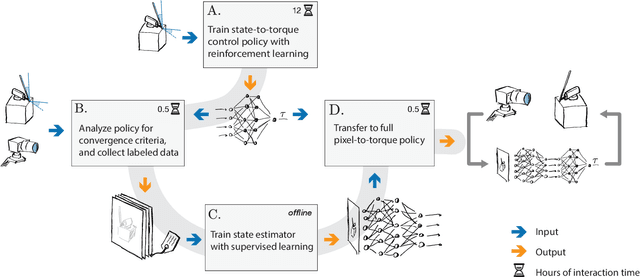
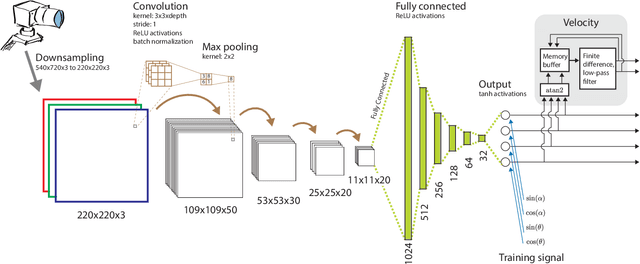
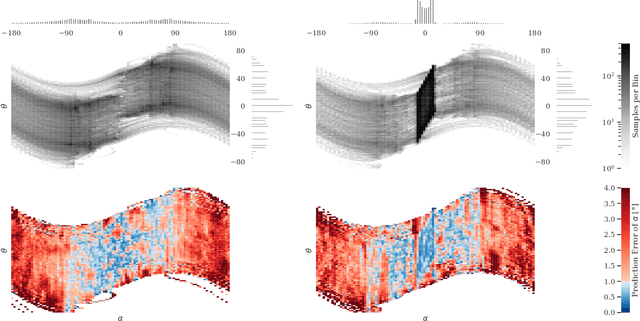
In the field, robots often need to operate in unknown and unstructured environments, where accurate sensing and state estimation (SE) becomes a major challenge. Cameras have been used to great success in mapping and planning in such environments, as well as complex but quasi-static tasks such as grasping, but are rarely integrated into the control loop for unstable systems. Learning pixel-to-torque control promises to allow robots to flexibly handle a wider variety of tasks. Although they do not present additional theoretical obstacles, learning pixel-to-torque control for unstable systems that that require precise and high bandwidth control still poses a significant practical challenge, and best practices have not yet been established. To help drive reproducible research on the practical aspects of learning pixel-to-torque control, we propose a platform that can flexibly represent the entire process, from lab to deployment, for learning pixel-to-torque control on a robot with fast, unstable dynamics: the vision-based Furuta pendulum. The platform can be reproduced with either off-the-shelf or custom-built hardware. We expect that this platform will allow researchers to quickly and systematically test different approaches, as well as reproduce and benchmark case studies from other labs. We also present a first case study on this system using DNNs which, to the best of our knowledge, is the first demonstration of learning pixel-to-torque control on an unstable system with update rates faster than 100 Hz. A video synopsis can be found online at https://youtu.be/S2llScfG-8E, and in the supplementary material.
Safe Value Functions
May 25, 2021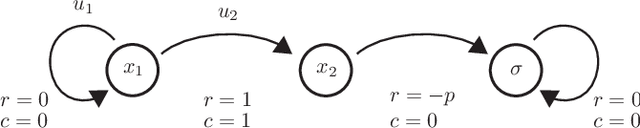
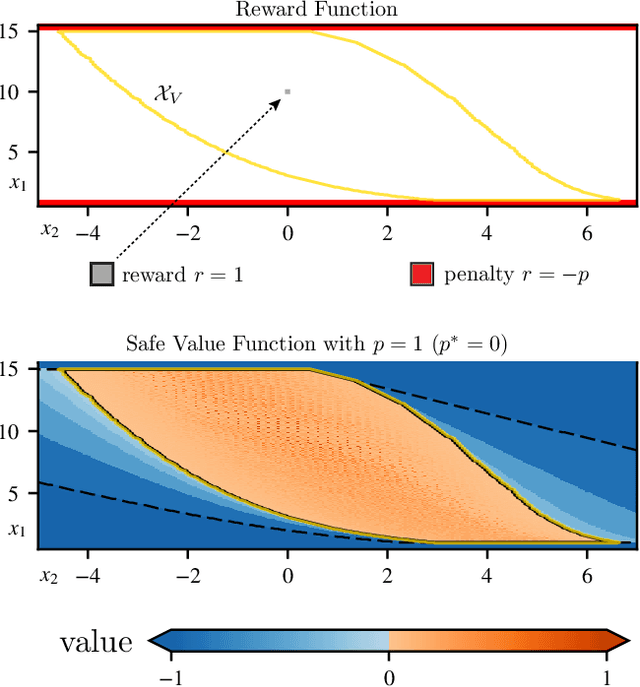
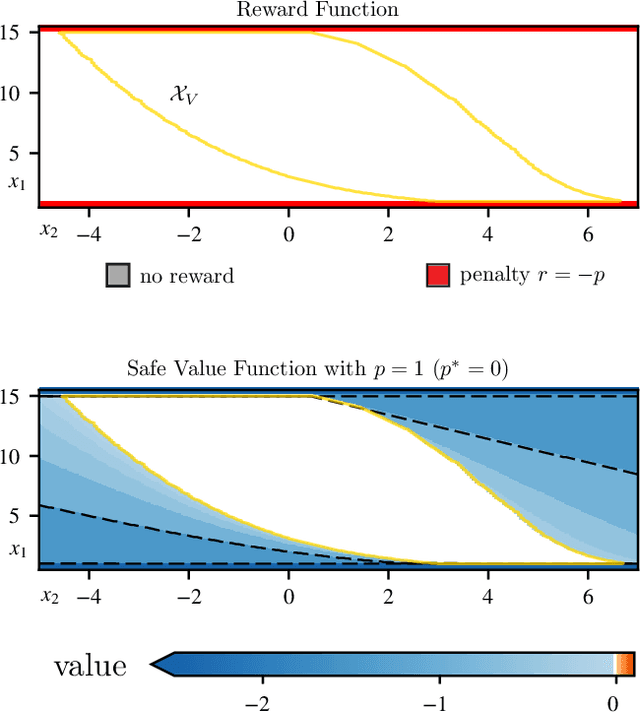
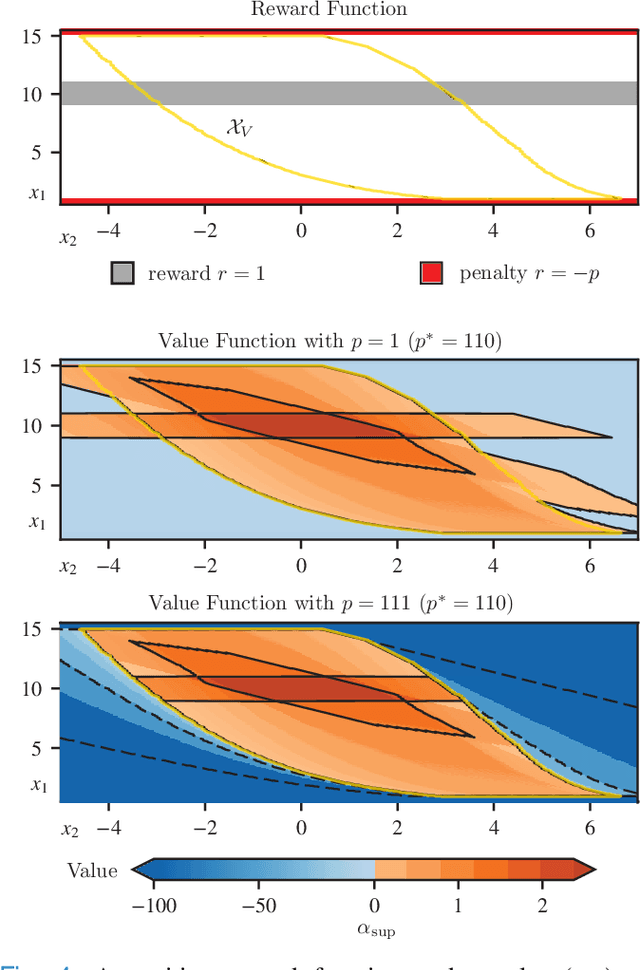
The relationship between safety and optimality in control is not well understood, and they are often seen as important yet conflicting objectives. There is a pressing need to formalize this relationship, especially given the growing prominence of learning-based methods. Indeed, it is common practice in reinforcement learning to simply modify reward functions by penalizing failures, with the penalty treated as a mere heuristic. We rigorously examine this relationship, and formalize the requirements for safe value functions: value functions that are both optimal for a given task, and enforce safety. We reveal the structure of this relationship through a proof of strong duality, showing that there always exists a finite penalty that induces a safe value function. This penalty is not unique, but upper-unbounded: larger penalties do not harm optimality. Although it is often not possible to compute the minimum required penalty, we reveal clear structure of how the penalty, rewards, discount factor, and dynamics interact. This insight suggests practical, theory-guided heuristics to design reward functions for control problems where safety is important.
A Learnable Safety Measure
Oct 07, 2019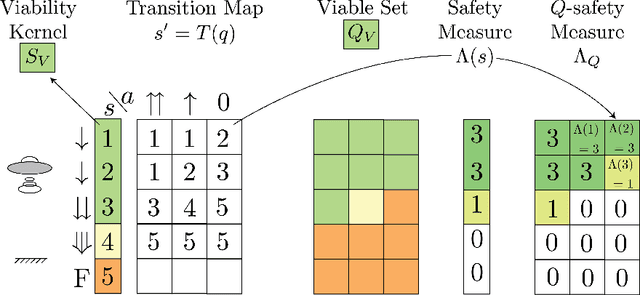
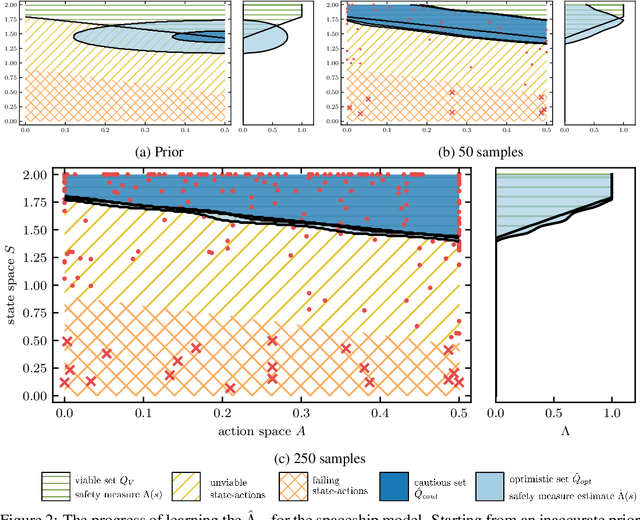
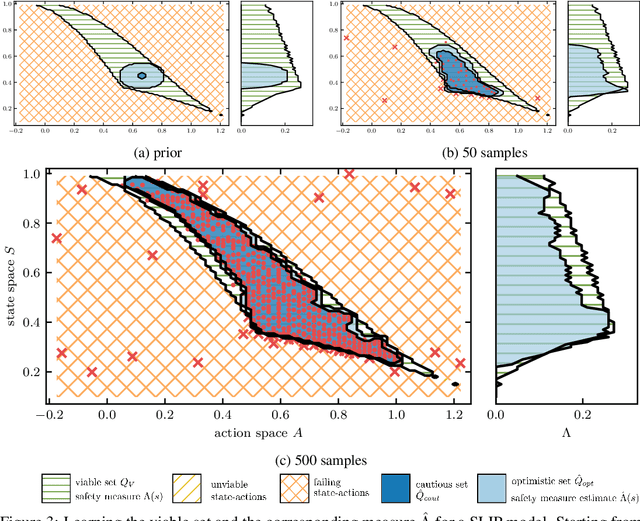
Failures are challenging for learning to control physical systems since they risk damage, time-consuming resets, and often provide little gradient information. Adding safety constraints to exploration typically requires a lot of prior knowledge and domain expertise. We present a safety measure which implicitly captures how the system dynamics relate to a set of failure states. Not only can this measure be used as a safety function, but also to directly compute the set of safe state-action pairs. Further, we show a model-free approach to learn this measure by active sampling using Gaussian processes. While safety can only be guaranteed after learning the safety measure, we show that failures can already be greatly reduced by using the estimated measure during learning.
An Open Torque-Controlled Modular Robot Architecture for Legged Locomotion Research
Sep 30, 2019

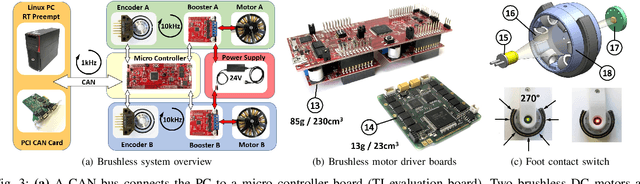
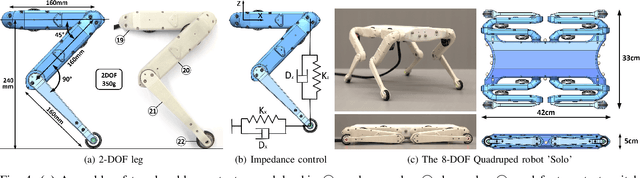
We present a new open-source torque-controlled legged robot system, with a low cost and low complexity actuator module at its core. It consists of a low-weight high torque brushless DC motor and a low gear ratio transmission suitable for impedance and force control. We also present a novel foot contact sensor suitable for legged locomotion with hard impacts. A 2.2 kg quadruped robot with a large range of motion is assembled from 8 identical actuator modules and 4 lower legs with foot contact sensors. To the best of our knowledge, it is the most lightest force-controlled quadruped robot. We leverage standard plastic 3D printing and off-the-shelf parts, resulting in light-weight and inexpensive robots, allowing for rapid distribution and duplication within the research community. In order to quantify the capabilities of our design, we systematically measure the achieved impedance at the foot in static and dynamic scenarios. We measured up to 10.8 dimensionless leg stiffness without active damping, which is comparable to the leg stiffness of a running human. Finally, in order to demonstrate the capabilities of our quadruped robot, we propose a novel controller which combines feedforward contact forces computed from a kino-dynamic optimizer with impedance control of the robot center of mass and base orientation. The controller is capable of regulating complex motions which are robust to environmental uncertainty.
Beyond Basins of Attraction: Evaluating Robustness of Natural Dynamics
Jun 21, 2018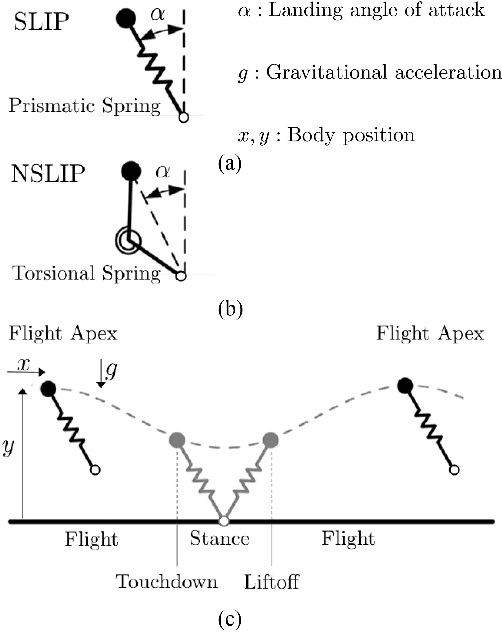



It is commonly accepted that properly designing a system to exhibit favorable natural dynamics can greatly simplify designing or learning the control policy. It is however still unclear what constitutes favorable natural dynamics, and how to quantify its effect. Most studies of simple walking and running models have focused on the basins of attraction of passive limit-cycles, and the notion of self-stability. We emphasize instead the importance of stepping beyond basins of attraction. We show an approach based on viability theory to quantify robustness, valid for the family of all robust control policies. This allows us to evaluate the robustness inherent to the natural dynamics before designing the control policy or specifying a control objective. We illustrate this approach on simple spring mass models of running and show previously unexplored advantages to using a nonlinear leg stiffness. We believe designing robots with robust natural dynamics is partic- ularly important for enabling learning control policies directly in hardware.
Learning from Outside the Viability Kernel: Why we Should Build Robots that can Fall with Grace
Jun 18, 2018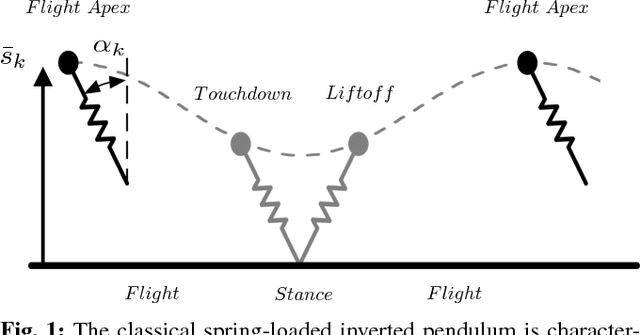
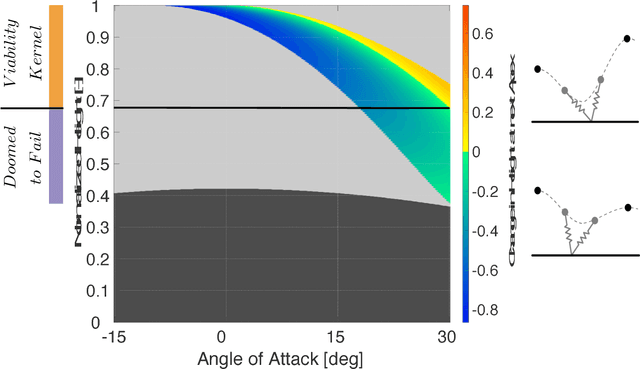
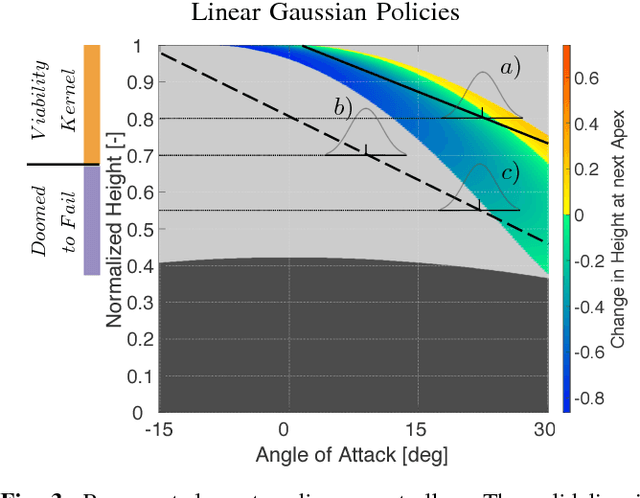
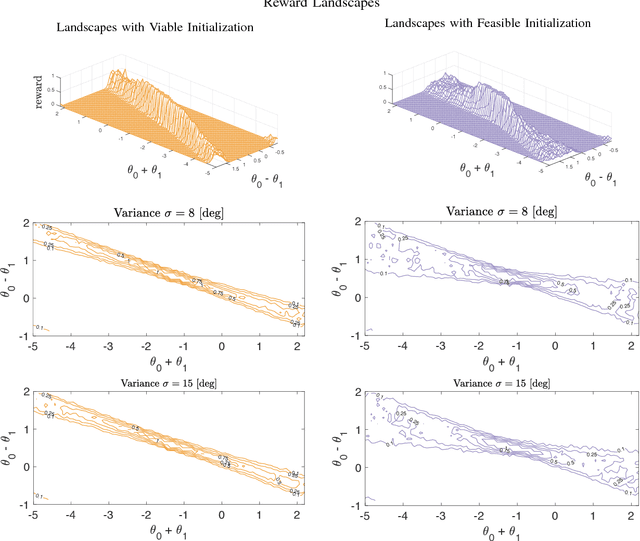
Despite impressive results using reinforcement learning to solve complex problems from scratch, in robotics this has still been largely limited to model-based learning with very informative reward functions. One of the major challenges is that the reward landscape often has large patches with no gradient, making it difficult to sample gradients effectively. We show here that the robot state-initialization can have a more important effect on the reward landscape than is generally expected. In particular, we show the counter-intuitive benefit of including initializations that are unviable, in other words initializing in states that are doomed to fail.
Shaping in Practice: Training Wheels to Learn Fast Hopping Directly in Hardware
Mar 07, 2018
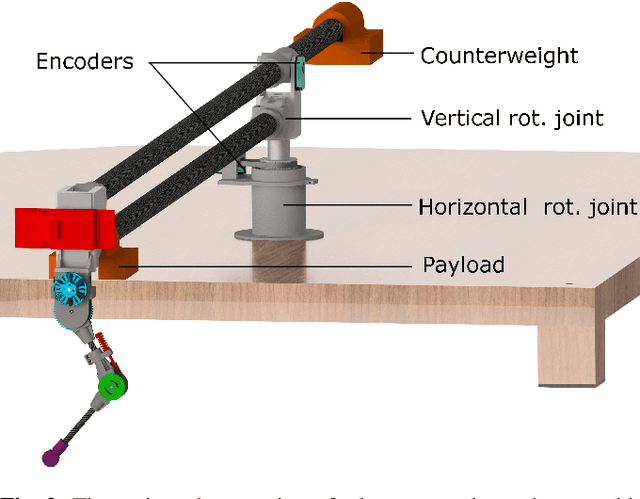
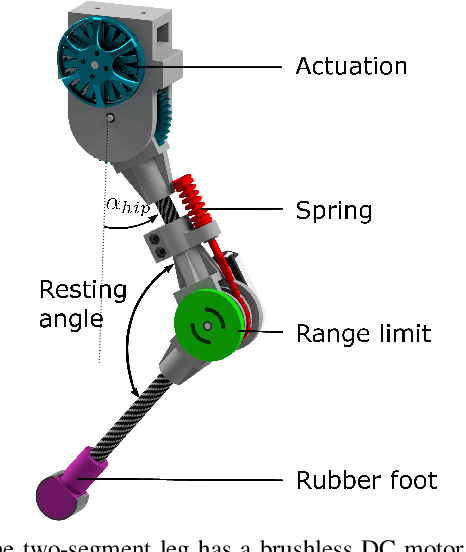
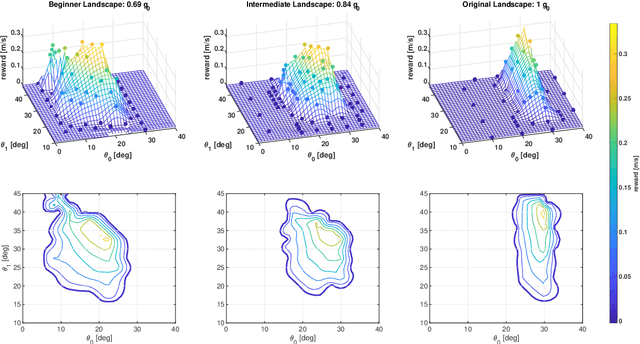
Learning instead of designing robot controllers can greatly reduce engineering effort required, while also emphasizing robustness. Despite considerable progress in simulation, applying learning directly in hardware is still challenging, in part due to the necessity to explore potentially unstable parameters. We explore the concept of shaping the reward landscape with training wheels: temporary modifications of the physical hardware that facilitate learning. We demonstrate the concept with a robot leg mounted on a boom learning to hop fast. This proof of concept embodies typical challenges such as instability and contact, while being simple enough to empirically map out and visualize the reward landscape. Based on our results we propose three criteria for designing effective training wheels for learning in robotics. A video synopsis can be found at https://youtu.be/6iH5E3LrYh8.