 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCusADi: A GPU Parallelization Framework for Symbolic Expressions and Optimal Control
Aug 19, 2024
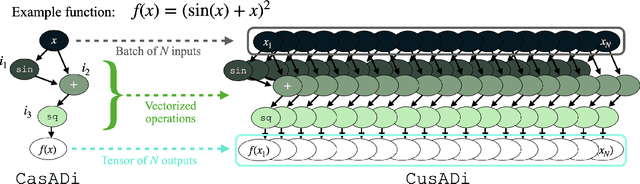
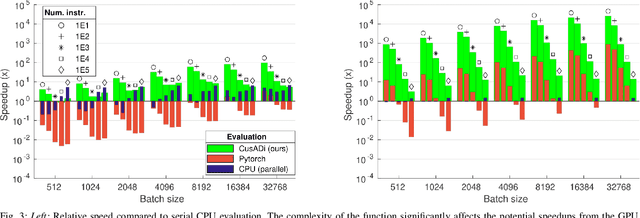
The parallelism afforded by GPUs presents significant advantages in training controllers through reinforcement learning (RL). However, integrating model-based optimization into this process remains challenging due to the complexity of formulating and solving optimization problems across thousands of instances. In this work, we present CusADi, an extension of the CasADi symbolic framework to support the parallelization of arbitrary closed-form expressions on GPUs with CUDA. We also formulate a closed-form approximation for solving general optimal control problems, enabling large-scale parallelization and evaluation of MPC controllers. Our results show a ten-fold speedup relative to similar MPC implementation on the CPU, and we demonstrate the use of CusADi for various applications, including parallel simulation, parameter sweeps, and policy training.
Tailoring Solution Accuracy for Fast Whole-body Model Predictive Control of Legged Robots
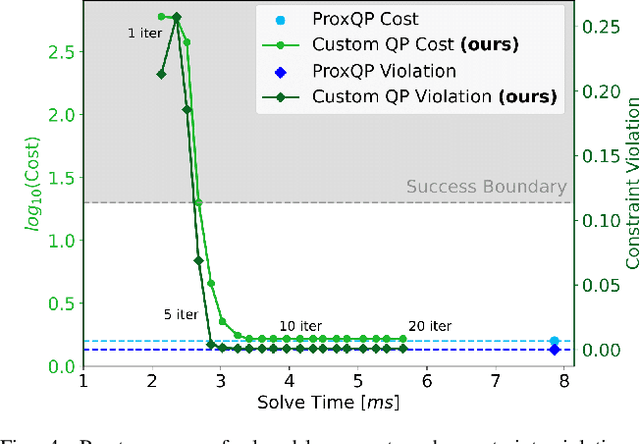
Jul 15, 2024Thanks to recent advancements in accelerating non-linear model predictive control (NMPC), it is now feasible to deploy whole-body NMPC at real-time rates for humanoid robots. However, enforcing inequality constraints in real time for such high-dimensional systems remains challenging due to the need for additional iterations. This paper presents an implementation of whole-body NMPC for legged robots that provides low-accuracy solutions to NMPC with general equality and inequality constraints. Instead of aiming for highly accurate optimal solutions, we leverage the alternating direction method of multipliers to rapidly provide low-accuracy solutions to quadratic programming subproblems. Our extensive simulation results indicate that real robots often cannot benefit from highly accurate solutions due to dynamics discretization errors, inertial modeling errors and delays. We incorporate control barrier functions (CBFs) at the initial timestep of the NMPC for the self-collision constraints, resulting in up to a 26-fold reduction in the number of self-collisions without adding computational burden. The controller is reliably deployed on hardware at 90 Hz for a problem involving 32 timesteps, 2004 variables, and 3768 constraints. The NMPC delivers sufficiently accurate solutions, enabling the MIT Humanoid to plan complex crossed-leg and arm motions that enhance stability when walking and recovering from significant disturbances.
Benchmarking Potential Based Rewards for Learning Humanoid Locomotion
Jul 19, 2023The main challenge in developing effective reinforcement learning (RL) pipelines is often the design and tuning the reward functions. Well-designed shaping reward can lead to significantly faster learning. Naively formulated rewards, however, can conflict with the desired behavior and result in overfitting or even erratic performance if not properly tuned. In theory, the broad class of potential based reward shaping (PBRS) can help guide the learning process without affecting the optimal policy. Although several studies have explored the use of potential based reward shaping to accelerate learning convergence, most have been limited to grid-worlds and low-dimensional systems, and RL in robotics has predominantly relied on standard forms of reward shaping. In this paper, we benchmark standard forms of shaping with PBRS for a humanoid robot. We find that in this high-dimensional system, PBRS has only marginal benefits in convergence speed. However, the PBRS reward terms are significantly more robust to scaling than typical reward shaping approaches, and thus easier to tune.
Humanoid Self-Collision Avoidance Using Whole-Body Control with Control Barrier Functions
Jul 01, 2022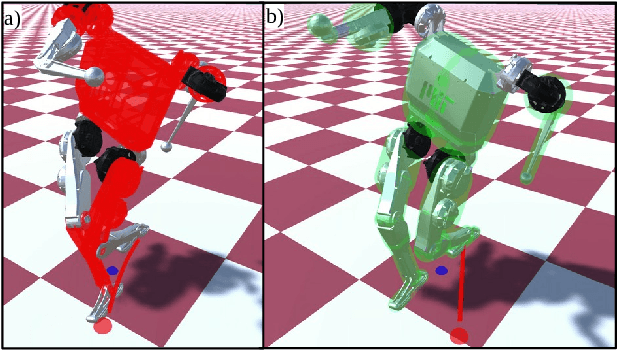

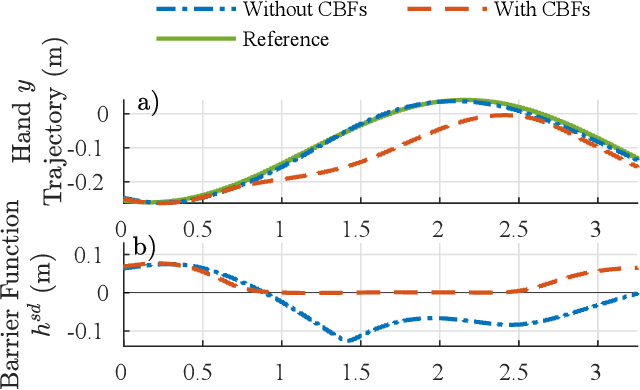
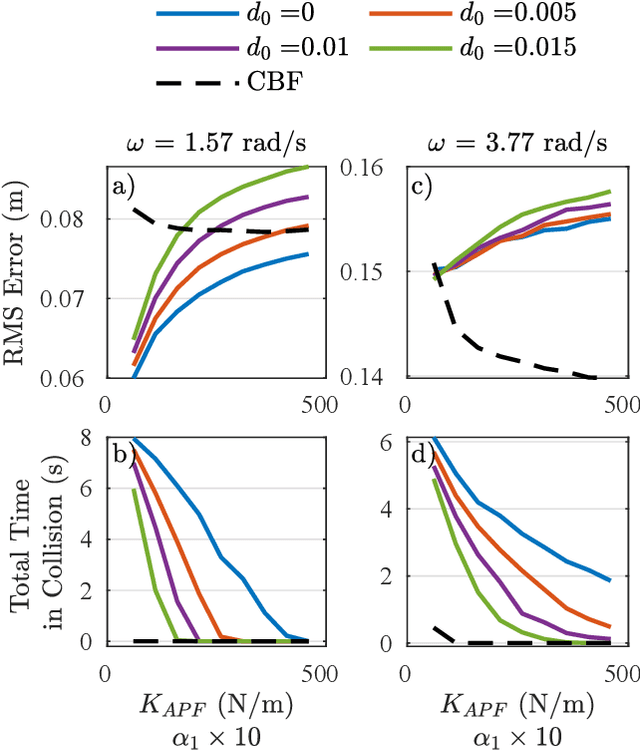
This work combines control barrier functions (CBFs) with a whole-body controller to enable self-collision avoidance for the MIT Humanoid. Existing reactive controllers for self-collision avoidance cannot guarantee collision-free trajectories as they do not leverage the robot's full dynamics, thus compromising kinematic feasibility. In comparison, the proposed CBF-WBC controller can reason about the robot's underactuated dynamics in real-time to guarantee collision-free motions. The effectiveness of this approach is validated in simulation. First, a simple hand-reaching experiment shows that the CBF-WBC enables the robot's hand to deviate from an infeasible reference trajectory to avoid self-collisions. Second, the CBF-WBC is combined with a linear model predictive controller (LMPC) designed for dynamic locomotion, and the CBF-WBC is used to track the LMPC predictions. A centroidal angular momentum task is also used to generate arm motions that assist humanoid locomotion and disturbance recovery. Walking experiments show that CBFs allow the centroidal angular momentum task to generate feasible arm motions and avoid leg self-collisions when the footstep location or swing trajectory provided by the high-level planner are infeasible for the real robot.
Dynamic Walking with Footstep Adaptation on the MIT Humanoid via Linear Model Predictive Control
Jun 08, 2022
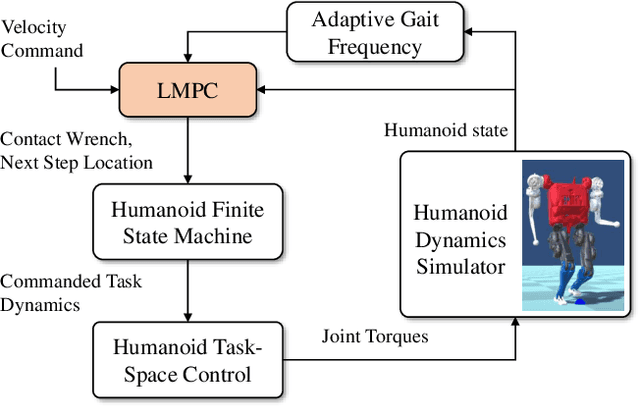
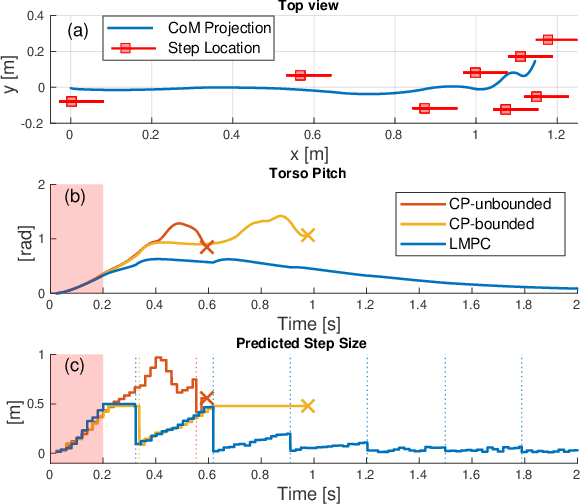
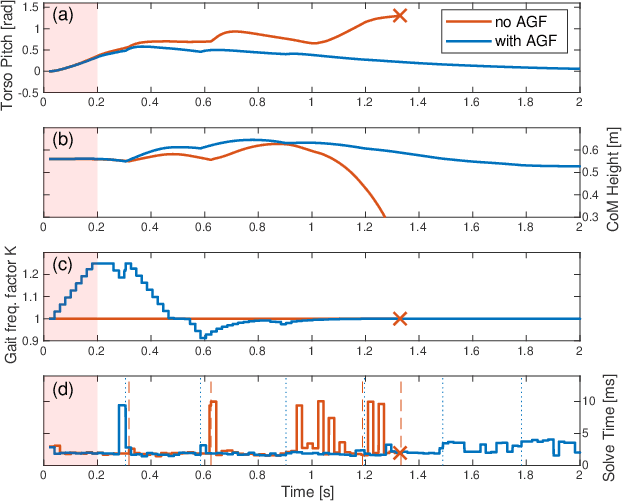
This paper proposes a model predictive control (MPC) framework for realizing dynamic walking gaits on the MIT Humanoid. In addition to adapting footstep location and timing online, the proposed method can reason about varying height, contact wrench, torso rotation, kinematic limit and negotiating uneven terrains. Specifically, a linear MPC (LMPC) optimizes for the desired footstep location by linearizing the single rigid body dynamics with respect to the current footstep location. A low-level task-space controller tracks the predicted state and control trajectories from the LMPC to leverage the full-body dynamics. Finally, an adaptive gait frequency scheme is employed to modify the step frequency and enhance the robustness of the walking controller. Both LMPC and task-space control can be efficiently solved as quadratic programs (QP), and thus amenable for real-time applications. Simulation studies where the MIT Humanoid traverses a wave field and recovers from impulsive disturbances validated the proposed approach.