 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCusADi: A GPU Parallelization Framework for Symbolic Expressions and Optimal Control
Paper and Code

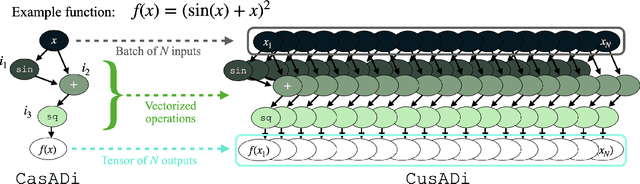
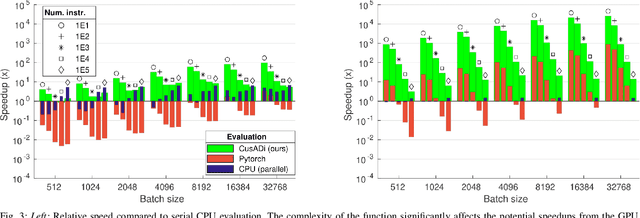
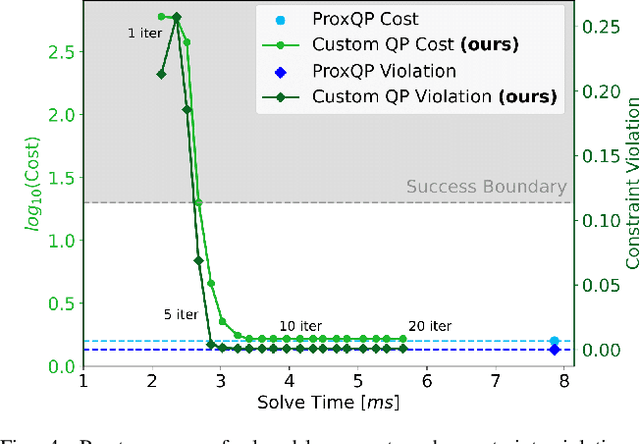
The parallelism afforded by GPUs presents significant advantages in training controllers through reinforcement learning (RL). However, integrating model-based optimization into this process remains challenging due to the complexity of formulating and solving optimization problems across thousands of instances. In this work, we present CusADi, an extension of the CasADi symbolic framework to support the parallelization of arbitrary closed-form expressions on GPUs with CUDA. We also formulate a closed-form approximation for solving general optimal control problems, enabling large-scale parallelization and evaluation of MPC controllers. Our results show a ten-fold speedup relative to similar MPC implementation on the CPU, and we demonstrate the use of CusADi for various applications, including parallel simulation, parameter sweeps, and policy training.