 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSailing Towards Zero-Shot State Estimation using Foundation Models Combined with a UKF
Sep 04, 2025State estimation in control and systems engineering traditionally requires extensive manual system identification or data-collection effort. However, transformer-based foundation models in other domains have reduced data requirements by leveraging pre-trained generalist models. Ultimately, developing zero-shot foundation models of system dynamics could drastically reduce manual deployment effort. While recent work shows that transformer-based end-to-end approaches can achieve zero-shot performance on unseen systems, they are limited to sensor models seen during training. We introduce the foundation model unscented Kalman filter (FM-UKF), which combines a transformer-based model of system dynamics with analytically known sensor models via an UKF, enabling generalization across varying dynamics without retraining for new sensor configurations. We evaluate FM-UKF on a new benchmark of container ship models with complex dynamics, demonstrating a competitive accuracy, effort, and robustness trade-off compared to classical methods with approximate system knowledge and to an end-to-end approach. The benchmark and dataset are open sourced to further support future research in zero-shot state estimation via foundation models.
A kernel conditional two-sample test
Jun 04, 2025We propose a framework for hypothesis testing on conditional probability distributions, which we then use to construct conditional two-sample statistical tests. These tests identify the inputs -- called covariates in this context -- where two conditional expectations differ with high probability. Our key idea is to transform confidence bounds of a learning method into a conditional two-sample test, and we instantiate this principle for kernel ridge regression (KRR) and conditional kernel mean embeddings. We generalize existing pointwise-in-time or time-uniform confidence bounds for KRR to previously-inaccessible yet essential cases such as infinite-dimensional outputs with non-trace-class kernels. These bounds enable circumventing the need for independent data in our statistical tests, since they allow online sampling. We also introduce bootstrapping schemes leveraging the parametric form of testing thresholds identified in theory to avoid tuning inaccessible parameters, making our method readily applicable in practice. Such conditional two-sample tests are especially relevant in applications where data arrive sequentially or non-independently, or when output distributions vary with operational parameters. We demonstrate their utility through examples in process monitoring and comparison of dynamical systems. Overall, our results establish a comprehensive foundation for conditional two-sample testing, from theoretical guarantees to practical implementation, and advance the state-of-the-art on the concentration of vector-valued least squares estimation.
On Rollouts in Model-Based Reinforcement Learning
Jan 28, 2025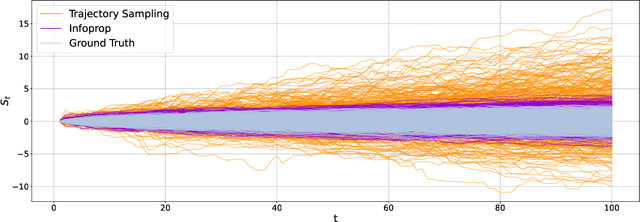

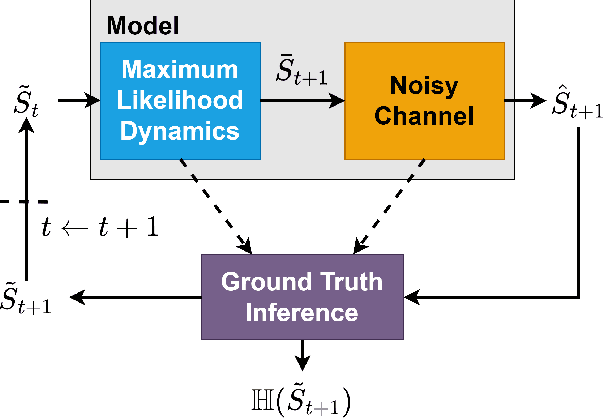
Model-based reinforcement learning (MBRL) seeks to enhance data efficiency by learning a model of the environment and generating synthetic rollouts from it. However, accumulated model errors during these rollouts can distort the data distribution, negatively impacting policy learning and hindering long-term planning. Thus, the accumulation of model errors is a key bottleneck in current MBRL methods. We propose Infoprop, a model-based rollout mechanism that separates aleatoric from epistemic model uncertainty and reduces the influence of the latter on the data distribution. Further, Infoprop keeps track of accumulated model errors along a model rollout and provides termination criteria to limit data corruption. We demonstrate the capabilities of Infoprop in the Infoprop-Dyna algorithm, reporting state-of-the-art performance in Dyna-style MBRL on common MuJoCo benchmark tasks while substantially increasing rollout length and data quality.
On Foundation Models for Dynamical Systems from Purely Synthetic Data
Nov 30, 2024



Foundation models have demonstrated remarkable generalization, data efficiency, and robustness properties across various domains. In this paper, we explore the feasibility of foundation models for applications in the control domain. The success of these models is enabled by large-scale pretaining on Internet-scale datasets. These are available in fields like natural language processing and computer vision, but do not exist for dynamical systems. We address this challenge by pretraining a transformer-based foundation model exclusively on synthetic data and propose to sample dynamics functions from a reproducing kernel Hilbert space. Our pretrained model generalizes for prediction tasks across different dynamical systems, which we validate in simulation and hardware experiments, including cart-pole and Furuta pendulum setups. Additionally, the model can be fine-tuned effectively to new systems to increase performance even further. Our results demonstrate the feasibility of foundation models for dynamical systems that outperform specialist models in terms of generalization, data efficiency, and robustness.
On the Consistency of Kernel Methods with Dependent Observations
Jun 10, 2024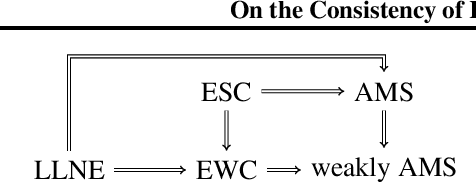
The consistency of a learning method is usually established under the assumption that the observations are a realization of an independent and identically distributed (i.i.d.) or mixing process. Yet, kernel methods such as support vector machines (SVMs), Gaussian processes, or conditional kernel mean embeddings (CKMEs) all give excellent performance under sampling schemes that are obviously non-i.i.d., such as when data comes from a dynamical system. We propose the new notion of empirical weak convergence (EWC) as a general assumption explaining such phenomena for kernel methods. It assumes the existence of a random asymptotic data distribution and is a strict weakening of previous assumptions in the field. Our main results then establish consistency of SVMs, kernel mean embeddings, and general Hilbert-space valued empirical expectations with EWC data. Our analysis holds for both finite- and infinite-dimensional outputs, as we extend classical results of statistical learning to the latter case. In particular, it is also applicable to CKMEs. Overall, our results open new classes of processes to statistical learning and can serve as a foundation for a theory of learning beyond i.i.d. and mixing.
Trust the Model Where It Trusts Itself -- Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption
May 29, 2024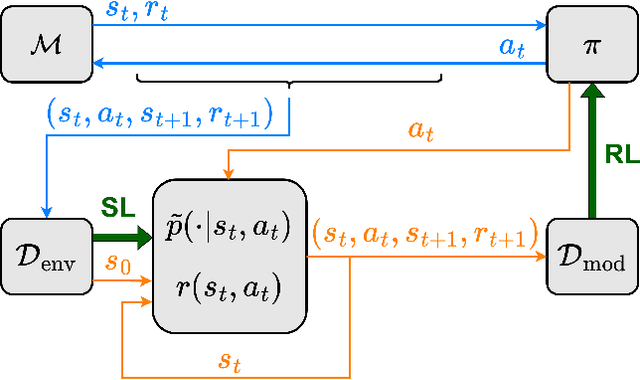
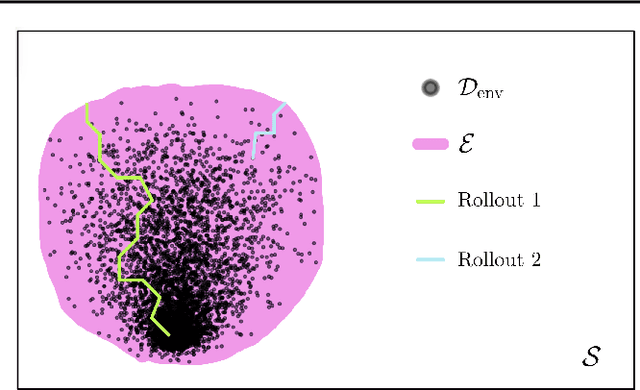

Dyna-style model-based reinforcement learning (MBRL) combines model-free agents with predictive transition models through model-based rollouts. This combination raises a critical question: 'When to trust your model?'; i.e., which rollout length results in the model providing useful data? Janner et al. (2019) address this question by gradually increasing rollout lengths throughout the training. While theoretically tempting, uniform model accuracy is a fallacy that collapses at the latest when extrapolating. Instead, we propose asking the question 'Where to trust your model?'. Using inherent model uncertainty to consider local accuracy, we obtain the Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption (MACURA) algorithm. We propose an easy-to-tune rollout mechanism and demonstrate substantial improvements in data efficiency and performance compared to state-of-the-art deep MBRL methods on the MuJoCo benchmark.
Scalable Concept Extraction in Industry 4.0
Jun 06, 2023



The industry 4.0 is leveraging digital technologies and machine learning techniques to connect and optimize manufacturing processes. Central to this idea is the ability to transform raw data into human understandable knowledge for reliable data-driven decision-making. Convolutional Neural Networks (CNNs) have been instrumental in processing image data, yet, their ``black box'' nature complicates the understanding of their prediction process. In this context, recent advances in the field of eXplainable Artificial Intelligence (XAI) have proposed the extraction and localization of concepts, or which visual cues intervene on the prediction process of CNNs. This paper tackles the application of concept extraction (CE) methods to industry 4.0 scenarios. To this end, we modify a recently developed technique, ``Extracting Concepts with Local Aggregated Descriptors'' (ECLAD), improving its scalability. Specifically, we propose a novel procedure for calculating concept importance, utilizing a wrapper function designed for CNNs. This process is aimed at decreasing the number of times each image needs to be evaluated. Subsequently, we demonstrate the potential of CE methods, by applying them in three industrial use cases. We selected three representative use cases in the context of quality control for material design (tailored textiles), manufacturing (carbon fiber reinforcement), and maintenance (photovoltaic module inspection). In these examples, CE was able to successfully extract and locate concepts directly related to each task. This is, the visual cues related to each concept, coincided with what human experts would use to perform the task themselves, even when the visual cues were entangled between multiple classes. Through empirical results, we show that CE can be applied for understanding CNNs in an industrial context, giving useful insights that can relate to domain knowledge.
Multimodal Multi-User Surface Recognition with the Kernel Two-Sample Test
Mar 08, 2023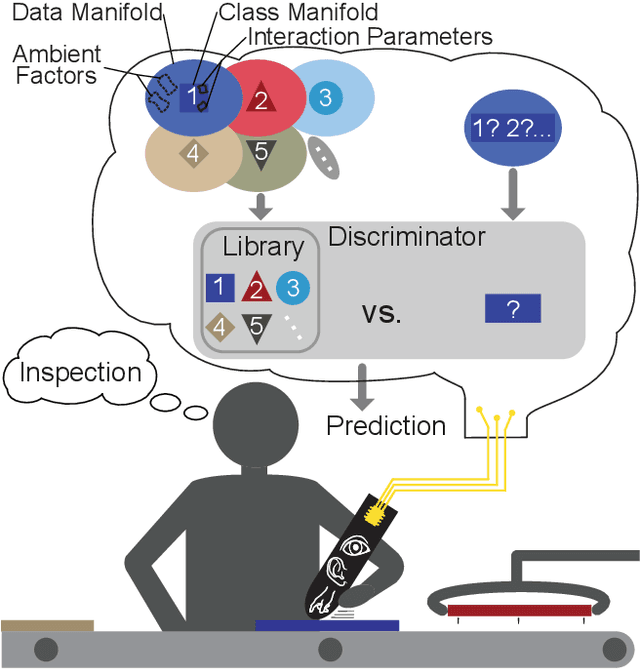
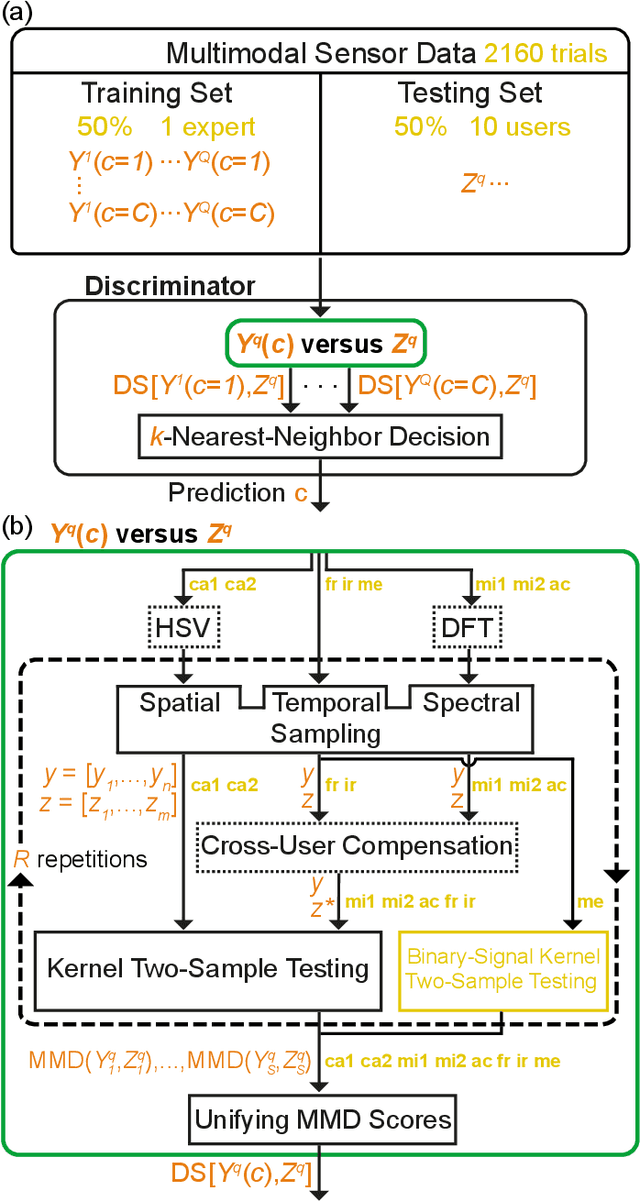
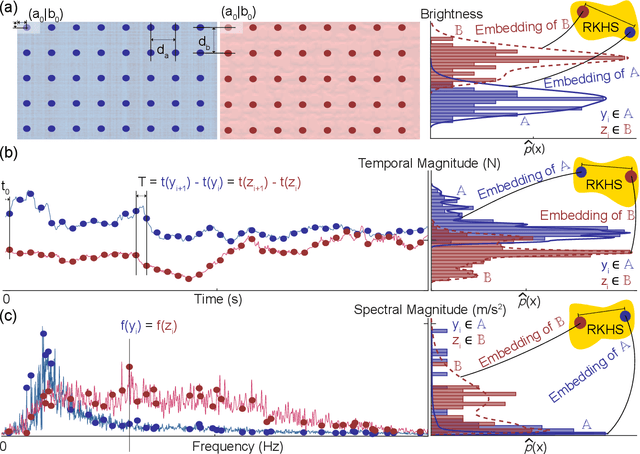

Machine learning and deep learning have been used extensively to classify physical surfaces through images and time-series contact data. However, these methods rely on human expertise and entail the time-consuming processes of data and parameter tuning. To overcome these challenges, we propose an easily implemented framework that can directly handle heterogeneous data sources for classification tasks. Our data-versus-data approach automatically quantifies distinctive differences in distributions in a high-dimensional space via kernel two-sample testing between two sets extracted from multimodal data (e.g., images, sounds, haptic signals). We demonstrate the effectiveness of our technique by benchmarking against expertly engineered classifiers for visual-audio-haptic surface recognition due to the industrial relevance, difficulty, and competitive baselines of this application; ablation studies confirm the utility of key components of our pipeline. As shown in our open-source code, we achieve 97.2% accuracy on a standard multi-user dataset with 108 surface classes, outperforming the state-of-the-art machine-learning algorithm by 6% on a more difficult version of the task. The fact that our classifier obtains this performance with minimal data processing in the standard algorithm setting reinforces the powerful nature of kernel methods for learning to recognize complex patterns.
Data-Driven Observability Analysis for Nonlinear Stochastic Systems
Feb 23, 2023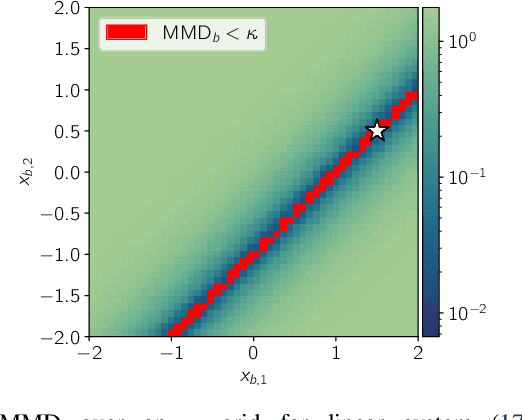
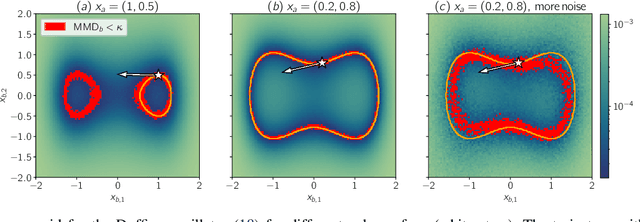
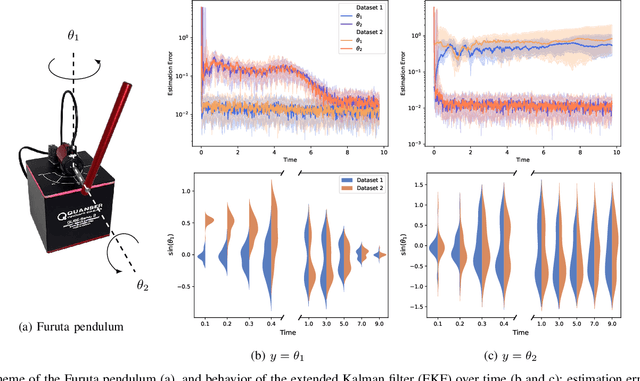
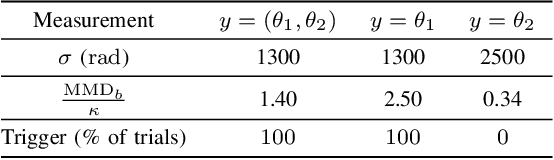
Distinguishability and, by extension, observability are key properties of dynamical systems. Establishing these properties is challenging, especially when no analytical model is available and they are to be inferred directly from measurement data. The presence of noise further complicates this analysis, as standard notions of distinguishability are tailored to deterministic systems. We build on distributional distinguishability, which extends the deterministic notion by comparing distributions of outputs of stochastic systems. We first show that both concepts are equivalent for a class of systems that includes linear systems. We then present a method to assess and quantify distributional distinguishability from output data. Specifically, our quantification measures how much data is required to tell apart two initial states, inducing a continuous spectrum of distinguishability. We propose a statistical test to determine a threshold above which two states can be considered distinguishable with high confidence. We illustrate these tools by computing distinguishability maps over the state space in simulation, then leverage the test to compare sensor configurations on hardware.
Event-Triggered Time-Varying Bayesian Optimization
Aug 23, 2022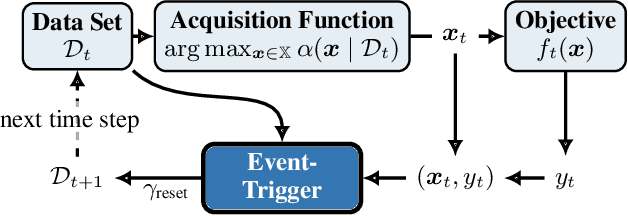

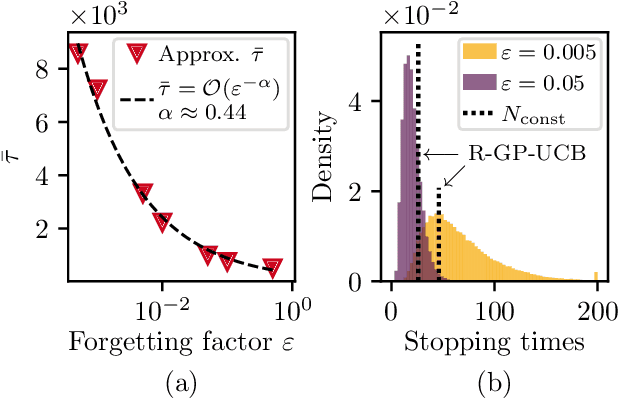
We consider the problem of sequentially optimizing a time-varying objective function using time-varying Bayesian optimization (TVBO). Here, the key challenge is to cope with old data. Current approaches to TVBO require prior knowledge of a constant rate of change. However, the rate of change is usually neither known nor constant. We propose an event-triggered algorithm, ET-GP-UCB, that detects changes in the objective function online. The event-trigger is based on probabilistic uniform error bounds used in Gaussian process regression. The trigger automatically detects when significant change in the objective functions occurs. The algorithm then adapts to the temporal change by resetting the accumulated dataset. We provide regret bounds for ET-GP-UCB and show in numerical experiments that it is competitive with state-of-the-art algorithms even though it requires no knowledge about the temporal changes. Further, ET-GP-UCB outperforms these competitive baselines if the rate of change is misspecified and we demonstrate that it is readily applicable to various settings without tuning hyperparameters.