 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mini Wheelbot Dataset: High-Fidelity Data for Robot Learning
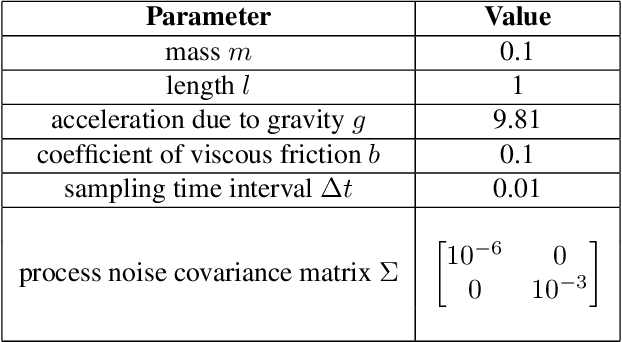
Jan 16, 2026The development of robust learning-based control algorithms for unstable systems requires high-quality, real-world data, yet access to specialized robotic hardware remains a significant barrier for many researchers. This paper introduces a comprehensive dynamics dataset for the Mini Wheelbot, an open-source, quasi-symmetric balancing reaction wheel unicycle. The dataset provides 1 kHz synchronized data encompassing all onboard sensor readings, state estimates, ground-truth poses from a motion capture system, and third-person video logs. To ensure data diversity, we include experiments across multiple hardware instances and surfaces using various control paradigms, including pseudo-random binary excitation, nonlinear model predictive control, and reinforcement learning agents. We include several example applications in dynamics model learning, state estimation, and time-series classification to illustrate common robotics algorithms that can be benchmarked on our dataset.
On Rollouts in Model-Based Reinforcement Learning
Jan 28, 2025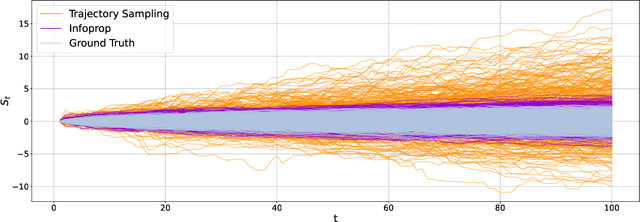

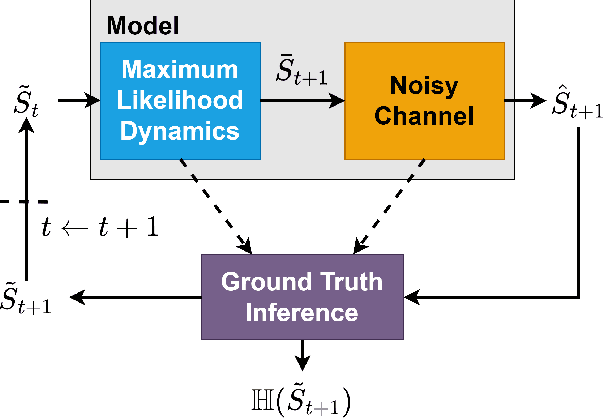
Model-based reinforcement learning (MBRL) seeks to enhance data efficiency by learning a model of the environment and generating synthetic rollouts from it. However, accumulated model errors during these rollouts can distort the data distribution, negatively impacting policy learning and hindering long-term planning. Thus, the accumulation of model errors is a key bottleneck in current MBRL methods. We propose Infoprop, a model-based rollout mechanism that separates aleatoric from epistemic model uncertainty and reduces the influence of the latter on the data distribution. Further, Infoprop keeps track of accumulated model errors along a model rollout and provides termination criteria to limit data corruption. We demonstrate the capabilities of Infoprop in the Infoprop-Dyna algorithm, reporting state-of-the-art performance in Dyna-style MBRL on common MuJoCo benchmark tasks while substantially increasing rollout length and data quality.
Trust the Model Where It Trusts Itself -- Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption
May 29, 2024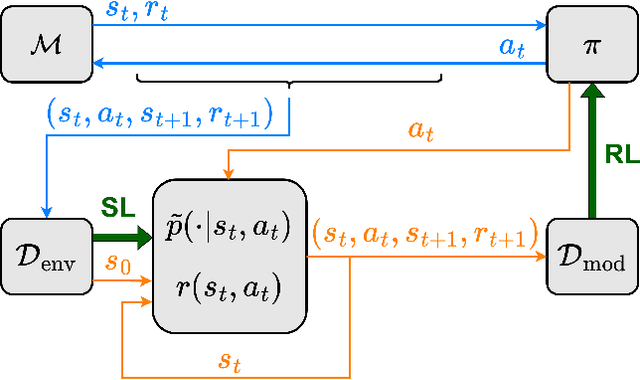
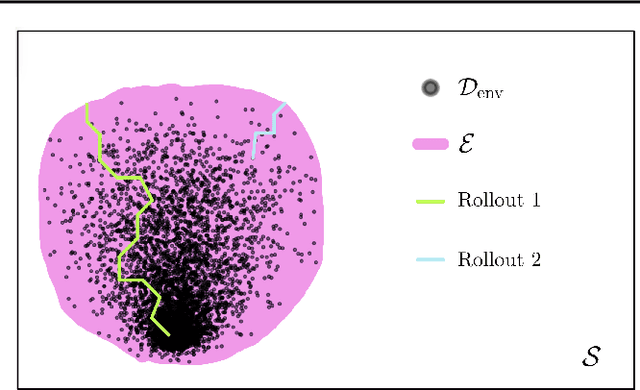

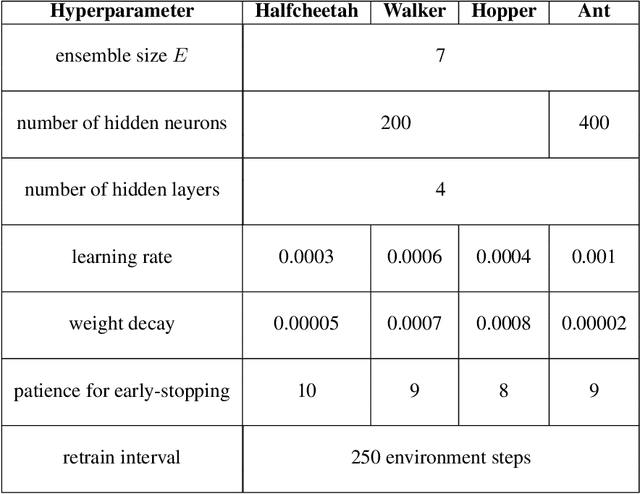
Dyna-style model-based reinforcement learning (MBRL) combines model-free agents with predictive transition models through model-based rollouts. This combination raises a critical question: 'When to trust your model?'; i.e., which rollout length results in the model providing useful data? Janner et al. (2019) address this question by gradually increasing rollout lengths throughout the training. While theoretically tempting, uniform model accuracy is a fallacy that collapses at the latest when extrapolating. Instead, we propose asking the question 'Where to trust your model?'. Using inherent model uncertainty to consider local accuracy, we obtain the Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption (MACURA) algorithm. We propose an easy-to-tune rollout mechanism and demonstrate substantial improvements in data efficiency and performance compared to state-of-the-art deep MBRL methods on the MuJoCo benchmark.