 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Rollouts in Model-Based Reinforcement Learning
Jan 28, 2025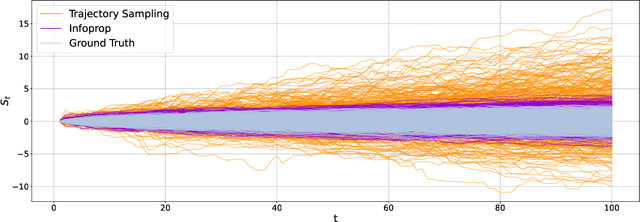

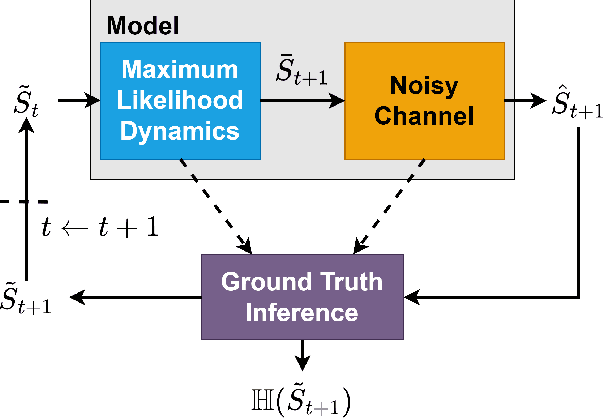
Model-based reinforcement learning (MBRL) seeks to enhance data efficiency by learning a model of the environment and generating synthetic rollouts from it. However, accumulated model errors during these rollouts can distort the data distribution, negatively impacting policy learning and hindering long-term planning. Thus, the accumulation of model errors is a key bottleneck in current MBRL methods. We propose Infoprop, a model-based rollout mechanism that separates aleatoric from epistemic model uncertainty and reduces the influence of the latter on the data distribution. Further, Infoprop keeps track of accumulated model errors along a model rollout and provides termination criteria to limit data corruption. We demonstrate the capabilities of Infoprop in the Infoprop-Dyna algorithm, reporting state-of-the-art performance in Dyna-style MBRL on common MuJoCo benchmark tasks while substantially increasing rollout length and data quality.
Contextualized Hybrid Ensemble Q-learning: Learning Fast with Control Priors
Jun 28, 2024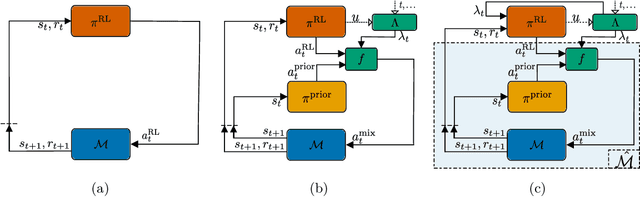
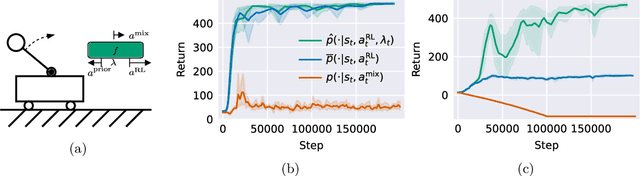
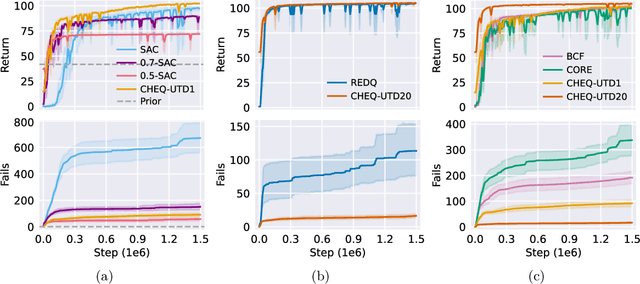
Combining Reinforcement Learning (RL) with a prior controller can yield the best out of two worlds: RL can solve complex nonlinear problems, while the control prior ensures safer exploration and speeds up training. Prior work largely blends both components with a fixed weight, neglecting that the RL agent's performance varies with the training progress and across regions in the state space. Therefore, we advocate for an adaptive strategy that dynamically adjusts the weighting based on the RL agent's current capabilities. We propose a new adaptive hybrid RL algorithm, Contextualized Hybrid Ensemble Q-learning (CHEQ). CHEQ combines three key ingredients: (i) a time-invariant formulation of the adaptive hybrid RL problem treating the adaptive weight as a context variable, (ii) a weight adaption mechanism based on the parametric uncertainty of a critic ensemble, and (iii) ensemble-based acceleration for data-efficient RL. Evaluating CHEQ on a car racing task reveals substantially stronger data efficiency, exploration safety, and transferability to unknown scenarios than state-of-the-art adaptive hybrid RL methods.
Trust the Model Where It Trusts Itself -- Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption
May 29, 2024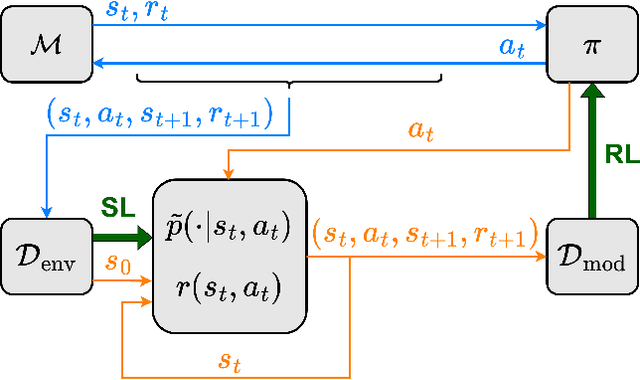
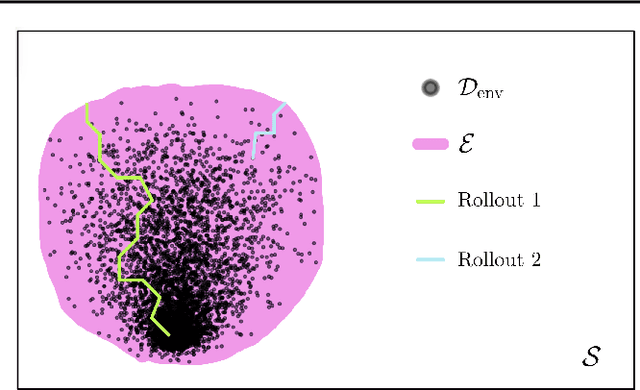

Dyna-style model-based reinforcement learning (MBRL) combines model-free agents with predictive transition models through model-based rollouts. This combination raises a critical question: 'When to trust your model?'; i.e., which rollout length results in the model providing useful data? Janner et al. (2019) address this question by gradually increasing rollout lengths throughout the training. While theoretically tempting, uniform model accuracy is a fallacy that collapses at the latest when extrapolating. Instead, we propose asking the question 'Where to trust your model?'. Using inherent model uncertainty to consider local accuracy, we obtain the Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption (MACURA) algorithm. We propose an easy-to-tune rollout mechanism and demonstrate substantial improvements in data efficiency and performance compared to state-of-the-art deep MBRL methods on the MuJoCo benchmark.
Data-efficient Deep Reinforcement Learning for Vehicle Trajectory Control
Nov 30, 2023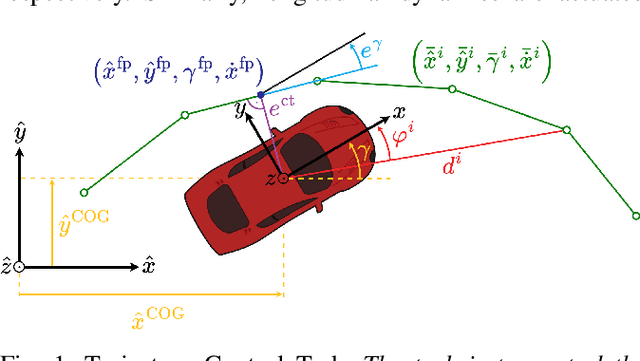
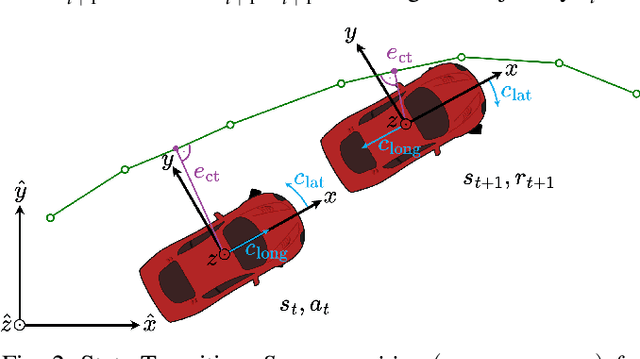
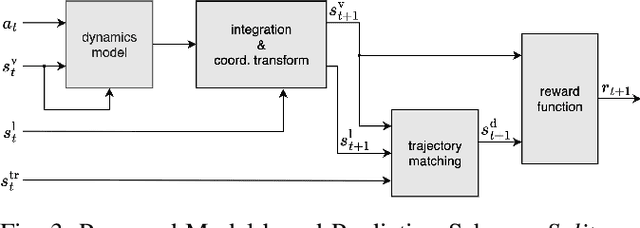

Advanced vehicle control is a fundamental building block in the development of autonomous driving systems. Reinforcement learning (RL) promises to achieve control performance superior to classical approaches while keeping computational demands low during deployment. However, standard RL approaches like soft-actor critic (SAC) require extensive amounts of training data to be collected and are thus impractical for real-world application. To address this issue, we apply recently developed data-efficient deep RL methods to vehicle trajectory control. Our investigation focuses on three methods, so far unexplored for vehicle control: randomized ensemble double Q-learning (REDQ), probabilistic ensembles with trajectory sampling and model predictive path integral optimizer (PETS-MPPI), and model-based policy optimization (MBPO). We find that in the case of trajectory control, the standard model-based RL formulation used in approaches like PETS-MPPI and MBPO is not suitable. We, therefore, propose a new formulation that splits dynamics prediction and vehicle localization. Our benchmark study on the CARLA simulator reveals that the three identified data-efficient deep RL approaches learn control strategies on a par with or better than SAC, yet reduce the required number of environment interactions by more than one order of magnitude.