 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHEQ-ing the Box: Safe Variable Impedance Learning for Robotic Polishing
Jan 14, 2025



Robotic systems are increasingly employed for industrial automation, with contact-rich tasks like polishing requiring dexterity and compliant behaviour. These tasks are difficult to model, making classical control challenging. Deep reinforcement learning (RL) offers a promising solution by enabling the learning of models and control policies directly from data. However, its application to real-world problems is limited by data inefficiency and unsafe exploration. Adaptive hybrid RL methods blend classical control and RL adaptively, combining the strengths of both: structure from control and learning from RL. This has led to improvements in data efficiency and exploration safety. However, their potential for hardware applications remains underexplored, with no evaluations on physical systems to date. Such evaluations are critical to fully assess the practicality and effectiveness of these methods in real-world settings. This work presents an experimental demonstration of the hybrid RL algorithm CHEQ for robotic polishing with variable impedance, a task requiring precise force and velocity tracking. In simulation, we show that variable impedance enhances polishing performance. We compare standalone RL with adaptive hybrid RL, demonstrating that CHEQ achieves effective learning while adhering to safety constraints. On hardware, CHEQ achieves effective polishing behaviour, requiring only eight hours of training and incurring just five failures. These results highlight the potential of adaptive hybrid RL for real-world, contact-rich tasks trained directly on hardware.
Contextualized Hybrid Ensemble Q-learning: Learning Fast with Control Priors
Jun 28, 2024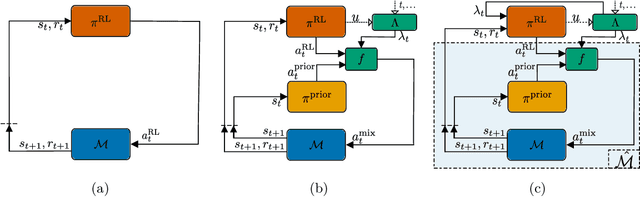
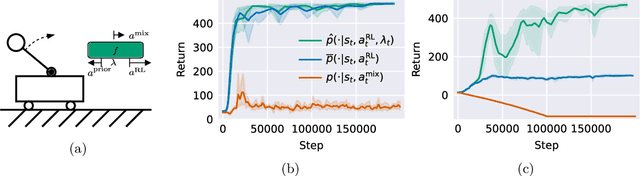
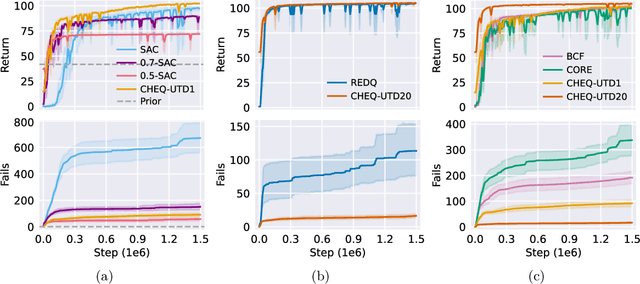
Combining Reinforcement Learning (RL) with a prior controller can yield the best out of two worlds: RL can solve complex nonlinear problems, while the control prior ensures safer exploration and speeds up training. Prior work largely blends both components with a fixed weight, neglecting that the RL agent's performance varies with the training progress and across regions in the state space. Therefore, we advocate for an adaptive strategy that dynamically adjusts the weighting based on the RL agent's current capabilities. We propose a new adaptive hybrid RL algorithm, Contextualized Hybrid Ensemble Q-learning (CHEQ). CHEQ combines three key ingredients: (i) a time-invariant formulation of the adaptive hybrid RL problem treating the adaptive weight as a context variable, (ii) a weight adaption mechanism based on the parametric uncertainty of a critic ensemble, and (iii) ensemble-based acceleration for data-efficient RL. Evaluating CHEQ on a car racing task reveals substantially stronger data efficiency, exploration safety, and transferability to unknown scenarios than state-of-the-art adaptive hybrid RL methods.
Combining Automated Optimisation of Hyperparameters and Reward Shape
Jun 26, 2024



There has been significant progress in deep reinforcement learning (RL) in recent years. Nevertheless, finding suitable hyperparameter configurations and reward functions remains challenging even for experts, and performance heavily relies on these design choices. Also, most RL research is conducted on known benchmarks where knowledge about these choices already exists. However, novel practical applications often pose complex tasks for which no prior knowledge about good hyperparameters and reward functions is available, thus necessitating their derivation from scratch. Prior work has examined automatically tuning either hyperparameters or reward functions individually. We demonstrate empirically that an RL algorithm's hyperparameter configurations and reward function are often mutually dependent, meaning neither can be fully optimised without appropriate values for the other. We then propose a methodology for the combined optimisation of hyperparameters and the reward function. Furthermore, we include a variance penalty as an optimisation objective to improve the stability of learned policies. We conducted extensive experiments using Proximal Policy Optimisation and Soft Actor-Critic on four environments. Our results show that combined optimisation significantly improves over baseline performance in half of the environments and achieves competitive performance in the others, with only a minor increase in computational costs. This suggests that combined optimisation should be best practice.
Tracking Object Positions in Reinforcement Learning: A Metric for Keypoint Detection (extended version)
Dec 01, 2023



Reinforcement learning (RL) for robot control typically requires a detailed representation of the environment state, including information about task-relevant objects not directly measurable. Keypoint detectors, such as spatial autoencoders (SAEs), are a common approach to extracting a low-dimensional representation from high-dimensional image data. SAEs aim at spatial features such as object positions, which are often useful representations in robotic RL. However, whether an SAE is actually able to track objects in the scene and thus yields a spatial state representation well suited for RL tasks has rarely been examined due to a lack of established metrics. In this paper, we propose to assess the performance of an SAE instance by measuring how well keypoints track ground truth objects in images. We present a computationally lightweight metric and use it to evaluate common baseline SAE architectures on image data from a simulated robot task. We find that common SAEs differ substantially in their spatial extraction capability. Furthermore, we validate that SAEs that perform well in our metric achieve superior performance when used in downstream RL. Thus, our metric is an effective and lightweight indicator of RL performance before executing expensive RL training. Building on these insights, we identify three key modifications of SAE architectures to improve tracking performance. We make our code available at anonymous.4open.science/r/sae-rl.