 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Hybrid Ensemble Q-learning: Learning Fast with Control Priors
Jun 28, 2024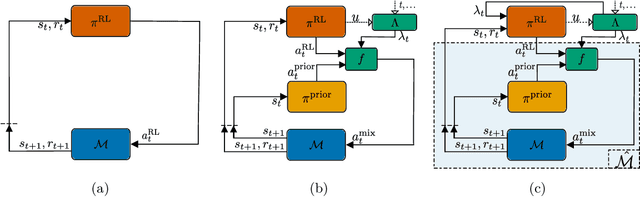
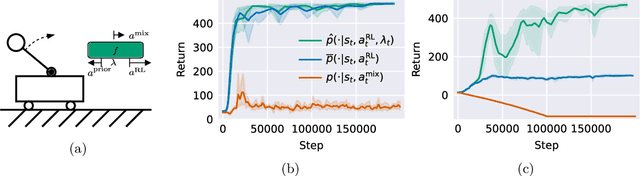
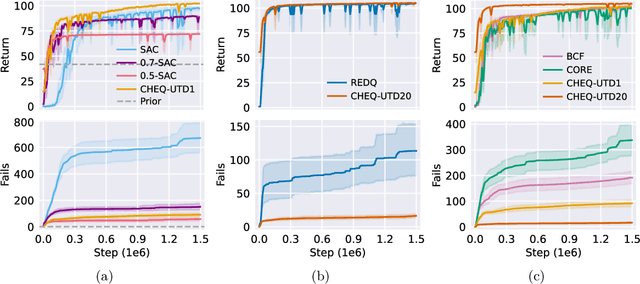
Combining Reinforcement Learning (RL) with a prior controller can yield the best out of two worlds: RL can solve complex nonlinear problems, while the control prior ensures safer exploration and speeds up training. Prior work largely blends both components with a fixed weight, neglecting that the RL agent's performance varies with the training progress and across regions in the state space. Therefore, we advocate for an adaptive strategy that dynamically adjusts the weighting based on the RL agent's current capabilities. We propose a new adaptive hybrid RL algorithm, Contextualized Hybrid Ensemble Q-learning (CHEQ). CHEQ combines three key ingredients: (i) a time-invariant formulation of the adaptive hybrid RL problem treating the adaptive weight as a context variable, (ii) a weight adaption mechanism based on the parametric uncertainty of a critic ensemble, and (iii) ensemble-based acceleration for data-efficient RL. Evaluating CHEQ on a car racing task reveals substantially stronger data efficiency, exploration safety, and transferability to unknown scenarios than state-of-the-art adaptive hybrid RL methods.