 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Hyperagents
Mar 19, 2026Self-improving AI systems aim to reduce reliance on human engineering by learning to improve their own learning and problem-solving processes. Existing approaches to self-improvement rely on fixed, handcrafted meta-level mechanisms, fundamentally limiting how fast such systems can improve. The Darwin Gödel Machine (DGM) demonstrates open-ended self-improvement in coding by repeatedly generating and evaluating self-modified variants. Because both evaluation and self-modification are coding tasks, gains in coding ability can translate into gains in self-improvement ability. However, this alignment does not generally hold beyond coding domains. We introduce \textbf{hyperagents}, self-referential agents that integrate a task agent (which solves the target task) and a meta agent (which modifies itself and the task agent) into a single editable program. Crucially, the meta-level modification procedure is itself editable, enabling metacognitive self-modification, improving not only the task-solving behavior, but also the mechanism that generates future improvements. We instantiate this framework by extending DGM to create DGM-Hyperagents (DGM-H), eliminating the assumption of domain-specific alignment between task performance and self-modification skill to potentially support self-accelerating progress on any computable task. Across diverse domains, the DGM-H improves performance over time and outperforms baselines without self-improvement or open-ended exploration, as well as prior self-improving systems. Furthermore, the DGM-H improves the process by which it generates new agents (e.g., persistent memory, performance tracking), and these meta-level improvements transfer across domains and accumulate across runs. DGM-Hyperagents offer a glimpse of open-ended AI systems that do not merely search for better solutions, but continually improve their search for how to improve.
APRES: An Agentic Paper Revision and Evaluation System
Mar 03, 2026Scientific discoveries must be communicated clearly to realize their full potential. Without effective communication, even the most groundbreaking findings risk being overlooked or misunderstood. The primary way scientists communicate their work and receive feedback from the community is through peer review. However, the current system often provides inconsistent feedback between reviewers, ultimately hindering the improvement of a manuscript and limiting its potential impact. In this paper, we introduce a novel method APRES powered by Large Language Models (LLMs) to update a scientific papers text based on an evaluation rubric. Our automated method discovers a rubric that is highly predictive of future citation counts, and integrate it with APRES in an automated system that revises papers to enhance their quality and impact. Crucially, this objective should be met without altering the core scientific content. We demonstrate the success of APRES, which improves future citation prediction by 19.6% in mean averaged error over the next best baseline, and show that our paper revision process yields papers that are preferred over the originals by human expert evaluators 79% of the time. Our findings provide strong empirical support for using LLMs as a tool to help authors stress-test their manuscripts before submission. Ultimately, our work seeks to augment, not replace, the essential role of human expert reviewers, for it should be humans who discern which discoveries truly matter, guiding science toward advancing knowledge and enriching lives.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
May 29, 2025Today's AI systems have human-designed, fixed architectures and cannot autonomously and continuously improve themselves. The advance of AI could itself be automated. If done safely, that would accelerate AI development and allow us to reap its benefits much sooner. Meta-learning can automate the discovery of novel algorithms, but is limited by first-order improvements and the human design of a suitable search space. The G\"odel machine proposed a theoretical alternative: a self-improving AI that repeatedly modifies itself in a provably beneficial manner. Unfortunately, proving that most changes are net beneficial is impossible in practice. We introduce the Darwin G\"odel Machine (DGM), a self-improving system that iteratively modifies its own code (thereby also improving its ability to modify its own codebase) and empirically validates each change using coding benchmarks. Inspired by Darwinian evolution and open-endedness research, the DGM maintains an archive of generated coding agents. It grows the archive by sampling an agent from it and using a foundation model to create a new, interesting, version of the sampled agent. This open-ended exploration forms a growing tree of diverse, high-quality agents and allows the parallel exploration of many different paths through the search space. Empirically, the DGM automatically improves its coding capabilities (e.g., better code editing tools, long-context window management, peer-review mechanisms), increasing performance on SWE-bench from 20.0% to 50.0%, and on Polyglot from 14.2% to 30.7%. Furthermore, the DGM significantly outperforms baselines without self-improvement or open-ended exploration. All experiments were done with safety precautions (e.g., sandboxing, human oversight). The DGM is a significant step toward self-improving AI, capable of gathering its own stepping stones along paths that unfold into endless innovation.
OMNI-EPIC: Open-endedness via Models of human Notions of Interestingness with Environments Programmed in Code
May 24, 2024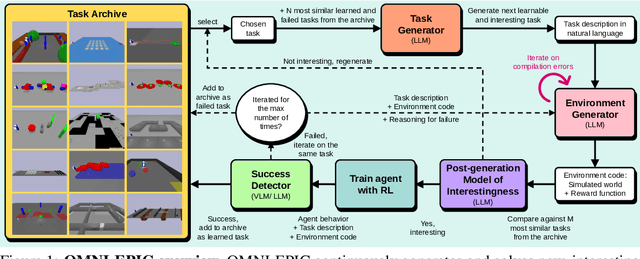
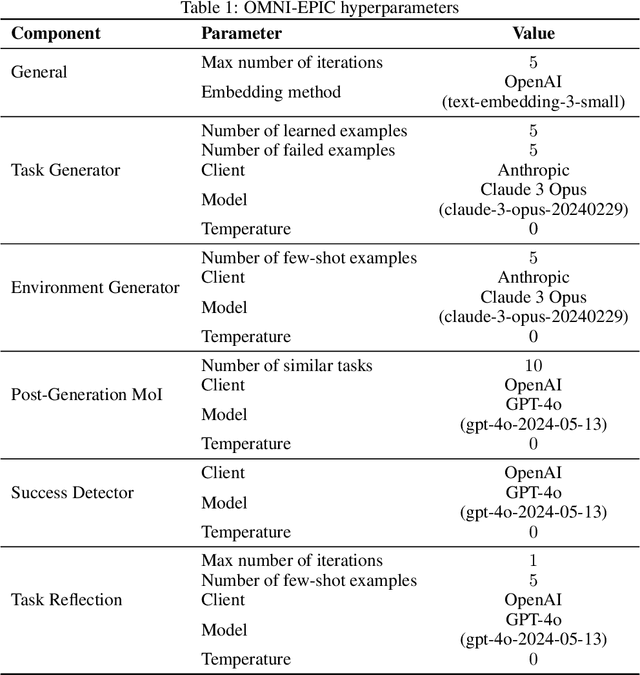
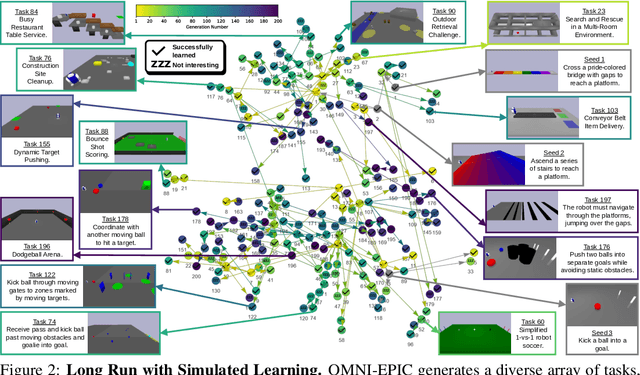
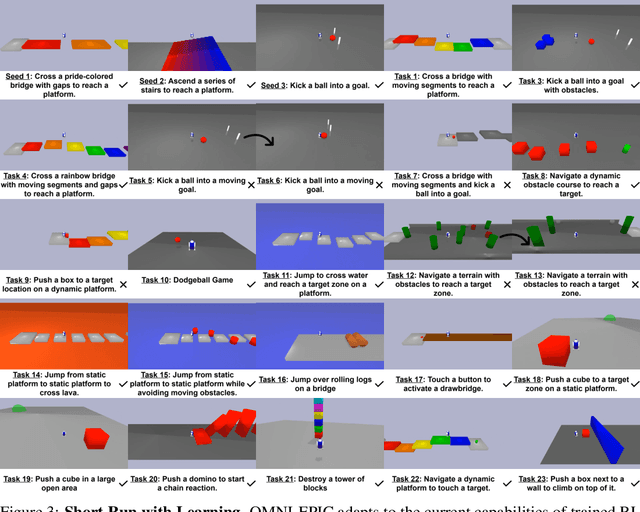
Open-ended and AI-generating algorithms aim to continuously generate and solve increasingly complex tasks indefinitely, offering a promising path toward more general intelligence. To accomplish this grand vision, learning must occur within a vast array of potential tasks. Existing approaches to automatically generating environments are constrained within manually predefined, often narrow distributions of environment, limiting their ability to create any learning environment. To address this limitation, we introduce a novel framework, OMNI-EPIC, that augments previous work in Open-endedness via Models of human Notions of Interestingness (OMNI) with Environments Programmed in Code (EPIC). OMNI-EPIC leverages foundation models to autonomously generate code specifying the next learnable (i.e., not too easy or difficult for the agent's current skill set) and interesting (e.g., worthwhile and novel) tasks. OMNI-EPIC generates both environments (e.g., an obstacle course) and reward functions (e.g., progress through the obstacle course quickly without touching red objects), enabling it, in principle, to create any simulatable learning task. We showcase the explosive creativity of OMNI-EPIC, which continuously innovates to suggest new, interesting learning challenges. We also highlight how OMNI-EPIC can adapt to reinforcement learning agents' learning progress, generating tasks that are of suitable difficulty. Overall, OMNI-EPIC can endlessly create learnable and interesting environments, further propelling the development of self-improving AI systems and AI-Generating Algorithms. Project website with videos: https://dub.sh/omniepic
Learning Emergent Gaits with Decentralized Phase Oscillators: on the role of Observations, Rewards, and Feedback
Feb 17, 2024



We present a minimal phase oscillator model for learning quadrupedal locomotion. Each of the four oscillators is coupled only to itself and its corresponding leg through local feedback of the ground reaction force, which can be interpreted as an observer feedback gain. We interpret the oscillator itself as a latent contact state-estimator. Through a systematic ablation study, we show that the combination of phase observations, simple phase-based rewards, and the local feedback dynamics induces policies that exhibit emergent gait preferences, while using a reduced set of simple rewards, and without prescribing a specific gait. The code is open-source, and a video synopsis available at https://youtu.be/1NKQ0rSV3jU.
Quality-Diversity through AI Feedback
Oct 31, 2023



In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society's capacity for innovation.
Quality Diversity through Human Feedback
Oct 18, 2023



Reinforcement learning from human feedback (RLHF) has exhibited the potential to enhance the performance of foundation models for qualitative tasks. Despite its promise, its efficacy is often restricted when conceptualized merely as a mechanism to maximize learned reward models of averaged human preferences, especially in areas such as image generation which demand diverse model responses. Meanwhile, quality diversity (QD) algorithms, dedicated to seeking diverse, high-quality solutions, are often constrained by the dependency on manually defined diversity metrics. Interestingly, such limitations of RLHF and QD can be overcome by blending insights from both. This paper introduces Quality Diversity through Human Feedback (QDHF), which employs human feedback for inferring diversity metrics, expanding the applicability of QD algorithms. Empirical results reveal that QDHF outperforms existing QD methods regarding automatic diversity discovery, and matches the search capabilities of QD with human-constructed metrics. Notably, when deployed for a latent space illumination task, QDHF markedly enhances the diversity of images generated by a Diffusion model. The study concludes with an in-depth analysis of QDHF's sample efficiency and the quality of its derived diversity metrics, emphasizing its promise for enhancing exploration and diversity in optimization for complex, open-ended tasks.
OMNI: Open-endedness via Models of human Notions of Interestingness
Jun 02, 2023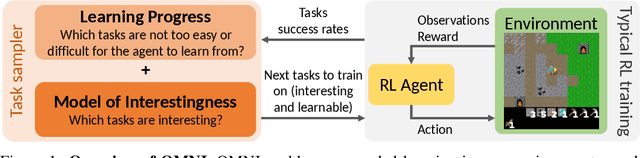

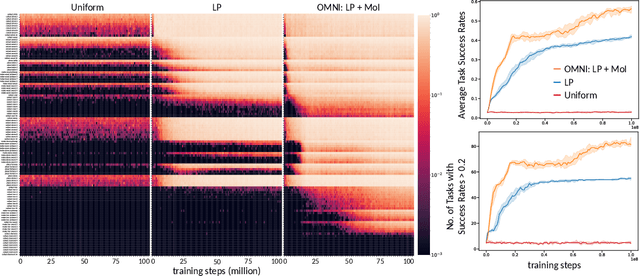
Open-ended algorithms aim to learn new, interesting behaviors forever. That requires a vast environment search space, but there are thus infinitely many possible tasks. Even after filtering for tasks the current agent can learn (i.e., learning progress), countless learnable yet uninteresting tasks remain (e.g., minor variations of previously learned tasks). An Achilles Heel of open-endedness research is the inability to quantify (and thus prioritize) tasks that are not just learnable, but also $\textit{interesting}$ (e.g., worthwhile and novel). We propose solving this problem by $\textit{Open-endedness via Models of human Notions of Interestingness}$ (OMNI). The insight is that we can utilize large (language) models (LMs) as a model of interestingness (MoI), because they $\textit{already}$ internalize human concepts of interestingness from training on vast amounts of human-generated data, where humans naturally write about what they find interesting or boring. We show that LM-based MoIs improve open-ended learning by focusing on tasks that are both learnable $\textit{and interesting}$, outperforming baselines based on uniform task sampling or learning progress alone. This approach has the potential to dramatically advance the ability to intelligently select which tasks to focus on next (i.e., auto-curricula), and could be seen as AI selecting its own next task to learn, facilitating self-improving AI and AI-Generating Algorithms.