 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnboard MuJoCo-based Model Predictive Control for Shipboard Crane with Double-Pendulum Sway Suppression
Mar 17, 2026Transferring heavy payloads in maritime settings relies on efficient crane operation, limited by hazardous double-pendulum payload sway. This sway motion is further exacerbated in offshore environments by external perturbations from wind and ocean waves. Manual suppression of these oscillations on an underactuated crane system by human operators is challenging. Existing control methods struggle in such settings, often relying on simplified analytical models, while deep reinforcement learning (RL) approaches tend to generalise poorly to unseen conditions. Deploying a predictive controller onto compute-constrained, highly non-linear physical systems without relying on extensive offline training or complex analytical models remains a significant challenge. Here we show a complete real-time control pipeline centered on the MuJoCo MPC framework that leverages a cross-entropy method planner to evaluate candidate action sequences directly within a physics simulator. By using simulated rollouts, this sampling-based approach successfully reconciles the conflicting objectives of dynamic target tracking and sway damping without relying on complex analytical models. We demonstrate that the controller can run effectively on a resource-constrained embedded hardware, while outperforming traditional PID and RL baselines in counteracting external base perturbations. Furthermore, our system demonstrates robustness even when subjected to unmodeled physical discrepancies like the introduction of a second payload.
CODE-SHARP: Continuous Open-ended Discovery and Evolution of Skills as Hierarchical Reward Programs
Feb 11, 2026Developing agents capable of open-endedly discovering and learning novel skills is a grand challenge in Artificial Intelligence. While reinforcement learning offers a powerful framework for training agents to master complex skills, it typically relies on hand-designed reward functions. This is infeasible for open-ended skill discovery, where the set of meaningful skills is not known a priori. While recent methods have shown promising results towards automating reward function design, they remain limited to refining rewards for pre-defined tasks. To address this limitation, we introduce Continuous Open-ended Discovery and Evolution of Skills as Hierarchical Reward Programs (CODE-SHARP), a novel framework leveraging Foundation Models (FM) to open-endedly expand and refine a hierarchical skill archive, structured as a directed graph of executable reward functions in code. We show that a goal-conditioned agent trained exclusively on the rewards generated by the discovered SHARP skills learns to solve increasingly long-horizon goals in the Craftax environment. When composed by a high-level FM-based planner, the discovered skills enable a single goal-conditioned agent to solve complex, long-horizon tasks, outperforming both pretrained agents and task-specific expert policies by over $134$% on average. We will open-source our code and provide additional videos at https://sites.google.com/view/code-sharp/homepage.
Dreaming in Code for Curriculum Learning in Open-Ended Worlds
Feb 09, 2026Open-ended learning frames intelligence as emerging from continual interaction with an ever-expanding space of environments. While recent advances have utilized foundation models to programmatically generate diverse environments, these approaches often focus on discovering isolated behaviors rather than orchestrating sustained progression. In complex open-ended worlds, the large combinatorial space of possible challenges makes it difficult for agents to discover sequences of experiences that remain consistently learnable. To address this, we propose Dreaming in Code (DiCode), a framework in which foundation models synthesize executable environment code to scaffold learning toward increasing competence. In DiCode, "dreaming" takes the form of materializing code-level variations of the world. We instantiate DiCode in Craftax, a challenging open-ended benchmark characterized by rich mechanics and long-horizon progression. Empirically, DiCode enables agents to acquire long-horizon skills, achieving a $16\%$ improvement in mean return over the strongest baseline and non-zero success on late-game combat tasks where prior methods fail. Our results suggest that code-level environment design provides a practical mechanism for curriculum control, enabling the construction of intermediate environments that bridge competence gaps in open-ended worlds. Project page and source code are available at https://konstantinosmitsides.github.io/dreaming-in-code and https://github.com/konstantinosmitsides/dreaming-in-code.
From Tabula Rasa to Emergent Abilities: Discovering Robot Skills via Real-World Unsupervised Quality-Diversity
Aug 28, 2025



Autonomous skill discovery aims to enable robots to acquire diverse behaviors without explicit supervision. Learning such behaviors directly on physical hardware remains challenging due to safety and data efficiency constraints. Existing methods, including Quality-Diversity Actor-Critic (QDAC), require manually defined skill spaces and carefully tuned heuristics, limiting real-world applicability. We propose Unsupervised Real-world Skill Acquisition (URSA), an extension of QDAC that enables robots to autonomously discover and master diverse, high-performing skills directly in the real world. We demonstrate that URSA successfully discovers diverse locomotion skills on a Unitree A1 quadruped in both simulation and the real world. Our approach supports both heuristic-driven skill discovery and fully unsupervised settings. We also show that the learned skill repertoire can be reused for downstream tasks such as real-world damage adaptation, where URSA outperforms all baselines in 5 out of 9 simulated and 3 out of 5 real-world damage scenarios. Our results establish a new framework for real-world robot learning that enables continuous skill discovery with limited human intervention, representing a significant step toward more autonomous and adaptable robotic systems. Demonstration videos are available at https://adaptive-intelligent-robotics.github.io/URSA.
A Path to Universal Neural Cellular Automata
May 19, 2025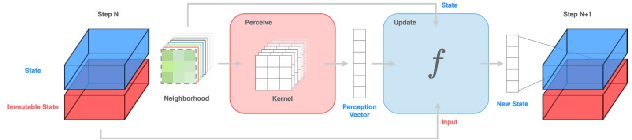



Cellular automata have long been celebrated for their ability to generate complex behaviors from simple, local rules, with well-known discrete models like Conway's Game of Life proven capable of universal computation. Recent advancements have extended cellular automata into continuous domains, raising the question of whether these systems retain the capacity for universal computation. In parallel, neural cellular automata have emerged as a powerful paradigm where rules are learned via gradient descent rather than manually designed. This work explores the potential of neural cellular automata to develop a continuous Universal Cellular Automaton through training by gradient descent. We introduce a cellular automaton model, objective functions and training strategies to guide neural cellular automata toward universal computation in a continuous setting. Our experiments demonstrate the successful training of fundamental computational primitives - such as matrix multiplication and transposition - culminating in the emulation of a neural network solving the MNIST digit classification task directly within the cellular automata state. These results represent a foundational step toward realizing analog general-purpose computers, with implications for understanding universal computation in continuous dynamics and advancing the automated discovery of complex cellular automata behaviors via machine learning.
Overcoming Deceptiveness in Fitness Optimization with Unsupervised Quality-Diversity
Apr 02, 2025
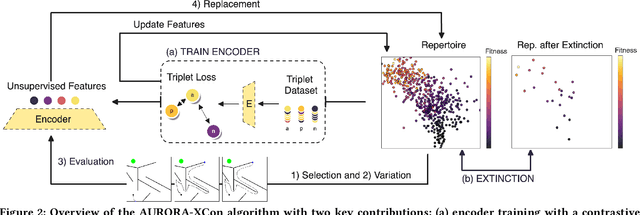
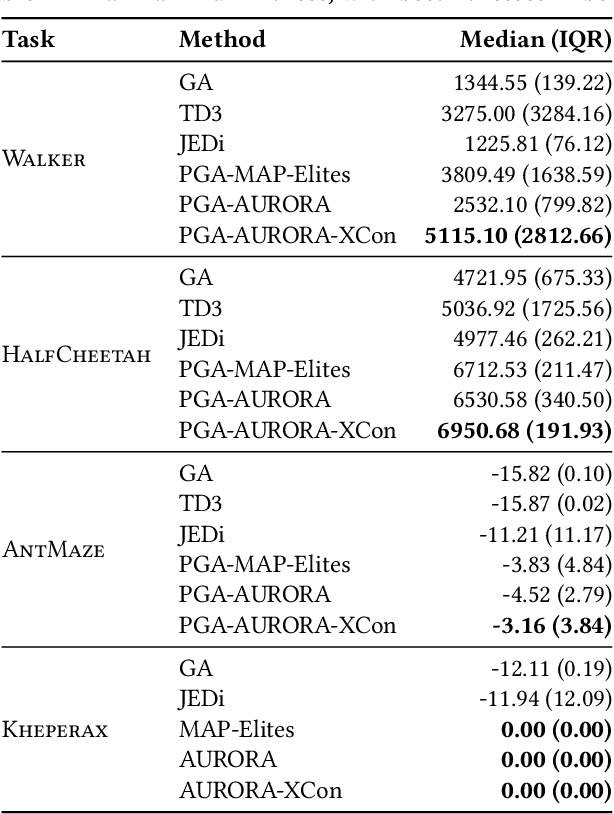
Policy optimization seeks the best solution to a control problem according to an objective or fitness function, serving as a fundamental field of engineering and research with applications in robotics. Traditional optimization methods like reinforcement learning and evolutionary algorithms struggle with deceptive fitness landscapes, where following immediate improvements leads to suboptimal solutions. Quality-diversity (QD) algorithms offer a promising approach by maintaining diverse intermediate solutions as stepping stones for escaping local optima. However, QD algorithms require domain expertise to define hand-crafted features, limiting their applicability where characterizing solution diversity remains unclear. In this paper, we show that unsupervised QD algorithms - specifically the AURORA framework, which learns features from sensory data - efficiently solve deceptive optimization problems without domain expertise. By enhancing AURORA with contrastive learning and periodic extinction events, we propose AURORA-XCon, which outperforms all traditional optimization baselines and matches, in some cases even improving by up to 34%, the best QD baseline with domain-specific hand-crafted features. This work establishes a novel application of unsupervised QD algorithms, shifting their focus from discovering novel solutions toward traditional optimization and expanding their potential to domains where defining feature spaces poses challenges.
Extract-QD Framework: A Generic Approach for Quality-Diversity in Noisy, Stochastic or Uncertain Domains
Feb 10, 2025



Quality-Diversity (QD) has demonstrated potential in discovering collections of diverse solutions to optimisation problems. Originally designed for deterministic environments, QD has been extended to noisy, stochastic, or uncertain domains through various Uncertain-QD (UQD) methods. However, the large number of UQD methods, each with unique constraints, makes selecting the most suitable one challenging. To remedy this situation, we present two contributions: first, the Extract-QD Framework (EQD Framework), and second, Extract-ME (EME), a new method derived from it. The EQD Framework unifies existing approaches within a modular view, and facilitates developing novel methods by interchanging modules. We use it to derive EME, a novel method that consistently outperforms or matches the best existing methods on standard benchmarks, while previous methods show varying performance. In a second experiment, we show how our EQD Framework can be used to augment existing QD algorithms and in particular the well-established Policy-Gradient-Assisted-MAP-Elites method, and demonstrate improved performance in uncertain domains at no additional evaluation cost. For any new uncertain task, our contributions now provide EME as a reliable "first guess" method, and the EQD Framework as a tool for developing task-specific approaches. Together, these contributions aim to lower the cost of adopting UQD insights in QD applications.
Discovering Quality-Diversity Algorithms via Meta-Black-Box Optimization
Feb 04, 2025



Quality-Diversity has emerged as a powerful family of evolutionary algorithms that generate diverse populations of high-performing solutions by implementing local competition principles inspired by biological evolution. While these algorithms successfully foster diversity and innovation, their specific mechanisms rely on heuristics, such as grid-based competition in MAP-Elites or nearest-neighbor competition in unstructured archives. In this work, we propose a fundamentally different approach: using meta-learning to automatically discover novel Quality-Diversity algorithms. By parameterizing the competition rules using attention-based neural architectures, we evolve new algorithms that capture complex relationships between individuals in the descriptor space. Our discovered algorithms demonstrate competitive or superior performance compared to established Quality-Diversity baselines while exhibiting strong generalization to higher dimensions, larger populations, and out-of-distribution domains like robot control. Notably, even when optimized solely for fitness, these algorithms naturally maintain diverse populations, suggesting meta-learning rediscovers that diversity is fundamental to effective optimization.
Scaling Policy Gradient Quality-Diversity with Massive Parallelization via Behavioral Variations
Jan 30, 2025



Quality-Diversity optimization comprises a family of evolutionary algorithms aimed at generating a collection of diverse and high-performing solutions. MAP-Elites (ME), a notable example, is used effectively in fields like evolutionary robotics. However, the reliance of ME on random mutations from Genetic Algorithms limits its ability to evolve high-dimensional solutions. Methods proposed to overcome this include using gradient-based operators like policy gradients or natural evolution strategies. While successful at scaling ME for neuroevolution, these methods often suffer from slow training speeds, or difficulties in scaling with massive parallelization due to high computational demands or reliance on centralized actor-critic training. In this work, we introduce a fast, sample-efficient ME based algorithm capable of scaling up with massive parallelization, significantly reducing runtimes without compromising performance. Our method, ASCII-ME, unlike existing policy gradient quality-diversity methods, does not rely on centralized actor-critic training. It performs behavioral variations based on time step performance metrics and maps these variations to solutions using policy gradients. Our experiments show that ASCII-ME can generate a diverse collection of high-performing deep neural network policies in less than 250 seconds on a single GPU. Additionally, it operates on average, five times faster than state-of-the-art algorithms while still maintaining competitive sample efficiency.
Preference-Conditioned Gradient Variations for Multi-Objective Quality-Diversity
Nov 19, 2024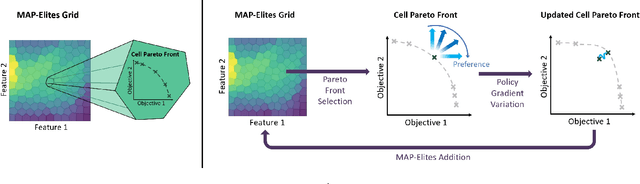
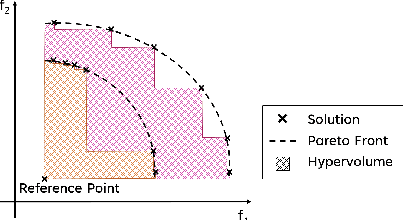
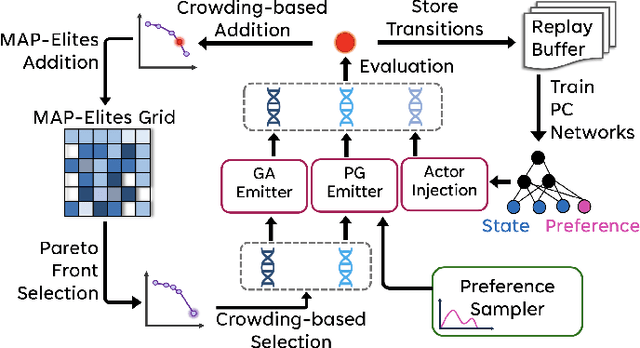
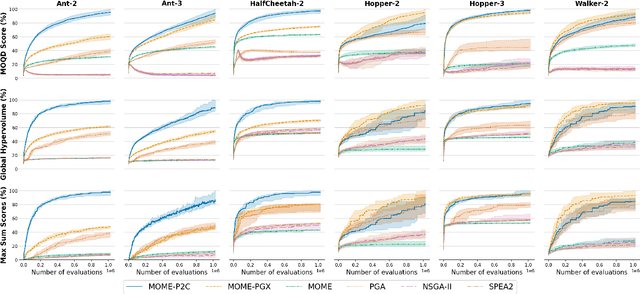
In a variety of domains, from robotics to finance, Quality-Diversity algorithms have been used to generate collections of both diverse and high-performing solutions. Multi-Objective Quality-Diversity algorithms have emerged as a promising approach for applying these methods to complex, multi-objective problems. However, existing methods are limited by their search capabilities. For example, Multi-Objective Map-Elites depends on random genetic variations which struggle in high-dimensional search spaces. Despite efforts to enhance search efficiency with gradient-based mutation operators, existing approaches consider updating solutions to improve on each objective separately rather than achieving desired trade-offs. In this work, we address this limitation by introducing Multi-Objective Map-Elites with Preference-Conditioned Policy-Gradient and Crowding Mechanisms: a new Multi-Objective Quality-Diversity algorithm that uses preference-conditioned policy-gradient mutations to efficiently discover promising regions of the objective space and crowding mechanisms to promote a uniform distribution of solutions on the Pareto front. We evaluate our approach on six robotics locomotion tasks and show that our method outperforms or matches all state-of-the-art Multi-Objective Quality-Diversity methods in all six, including two newly proposed tri-objective tasks. Importantly, our method also achieves a smoother set of trade-offs, as measured by newly-proposed sparsity-based metrics. This performance comes at a lower computational storage cost compared to previous methods.