 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnboard MuJoCo-based Model Predictive Control for Shipboard Crane with Double-Pendulum Sway Suppression
Mar 17, 2026Transferring heavy payloads in maritime settings relies on efficient crane operation, limited by hazardous double-pendulum payload sway. This sway motion is further exacerbated in offshore environments by external perturbations from wind and ocean waves. Manual suppression of these oscillations on an underactuated crane system by human operators is challenging. Existing control methods struggle in such settings, often relying on simplified analytical models, while deep reinforcement learning (RL) approaches tend to generalise poorly to unseen conditions. Deploying a predictive controller onto compute-constrained, highly non-linear physical systems without relying on extensive offline training or complex analytical models remains a significant challenge. Here we show a complete real-time control pipeline centered on the MuJoCo MPC framework that leverages a cross-entropy method planner to evaluate candidate action sequences directly within a physics simulator. By using simulated rollouts, this sampling-based approach successfully reconciles the conflicting objectives of dynamic target tracking and sway damping without relying on complex analytical models. We demonstrate that the controller can run effectively on a resource-constrained embedded hardware, while outperforming traditional PID and RL baselines in counteracting external base perturbations. Furthermore, our system demonstrates robustness even when subjected to unmodeled physical discrepancies like the introduction of a second payload.
Overcoming Deceptiveness in Fitness Optimization with Unsupervised Quality-Diversity
Apr 02, 2025
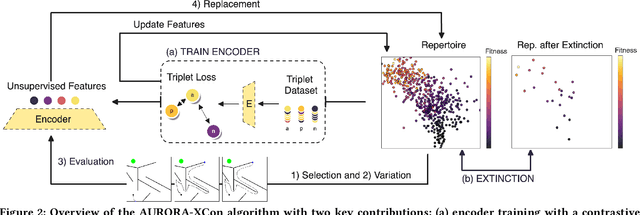
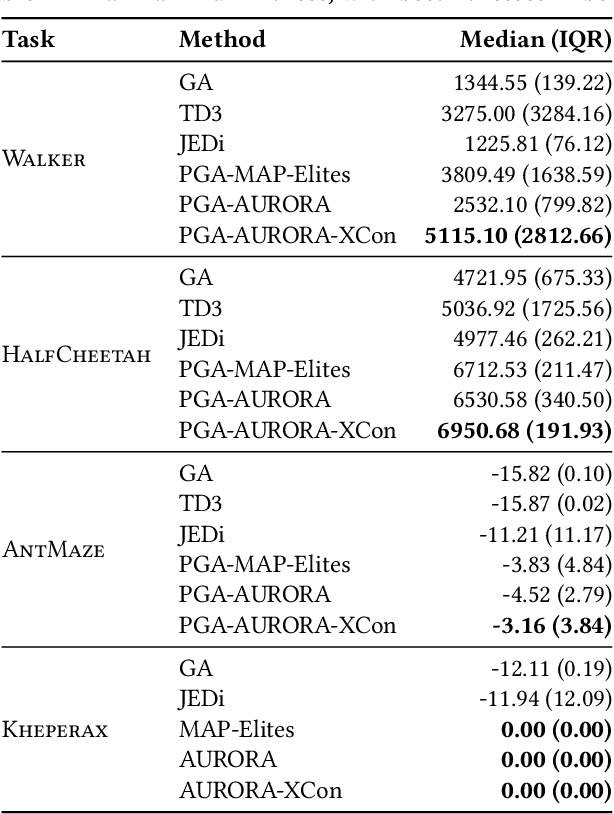
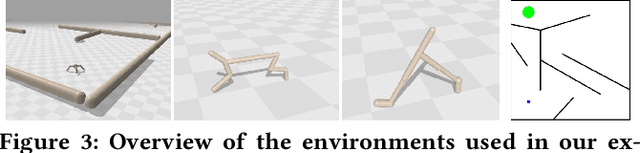
Policy optimization seeks the best solution to a control problem according to an objective or fitness function, serving as a fundamental field of engineering and research with applications in robotics. Traditional optimization methods like reinforcement learning and evolutionary algorithms struggle with deceptive fitness landscapes, where following immediate improvements leads to suboptimal solutions. Quality-diversity (QD) algorithms offer a promising approach by maintaining diverse intermediate solutions as stepping stones for escaping local optima. However, QD algorithms require domain expertise to define hand-crafted features, limiting their applicability where characterizing solution diversity remains unclear. In this paper, we show that unsupervised QD algorithms - specifically the AURORA framework, which learns features from sensory data - efficiently solve deceptive optimization problems without domain expertise. By enhancing AURORA with contrastive learning and periodic extinction events, we propose AURORA-XCon, which outperforms all traditional optimization baselines and matches, in some cases even improving by up to 34%, the best QD baseline with domain-specific hand-crafted features. This work establishes a novel application of unsupervised QD algorithms, shifting their focus from discovering novel solutions toward traditional optimization and expanding their potential to domains where defining feature spaces poses challenges.
Quality with Just Enough Diversity in Evolutionary Policy Search
May 07, 2024



Evolution Strategies (ES) are effective gradient-free optimization methods that can be competitive with gradient-based approaches for policy search. ES only rely on the total episodic scores of solutions in their population, from which they estimate fitness gradients for their update with no access to true gradient information. However this makes them sensitive to deceptive fitness landscapes, and they tend to only explore one way to solve a problem. Quality-Diversity methods such as MAP-Elites introduced additional information with behavior descriptors (BD) to return a population of diverse solutions, which helps exploration but leads to a large part of the evaluation budget not being focused on finding the best performing solution. Here we show that behavior information can also be leveraged to find the best policy by identifying promising search areas which can then be efficiently explored with ES. We introduce the framework of Quality with Just Enough Diversity (JEDi) which learns the relationship between behavior and fitness to focus evaluations on solutions that matter. When trying to reach higher fitness values, JEDi outperforms both QD and ES methods on hard exploration tasks like mazes and on complex control problems with large policies.
Genetic Drift Regularization: on preventing Actor Injection from breaking Evolution Strategies
May 07, 2024Evolutionary Algorithms (EA) have been successfully used for the optimization of neural networks for policy search, but they still remain sample inefficient and underperforming in some cases compared to gradient-based reinforcement learning (RL). Various methods combine the two approaches, many of them training a RL algorithm on data from EA evaluations and injecting the RL actor into the EA population. However, when using Evolution Strategies (ES) as the EA, the RL actor can drift genetically far from the the ES distribution and injection can cause a collapse of the ES performance. Here, we highlight the phenomenon of genetic drift where the actor genome and the ES population distribution progressively drift apart, leading to injection having a negative impact on the ES. We introduce Genetic Drift Regularization (GDR), a simple regularization method in the actor training loss that prevents the actor genome from drifting away from the ES. We show that GDR can improve ES convergence on problems where RL learns well, but also helps RL training on other tasks, , fixes the injection issues better than previous controlled injection methods.
Searching Search Spaces: Meta-evolving a Geometric Encoding for Neural Networks
Mar 20, 2024In evolutionary policy search, neural networks are usually represented using a direct mapping: each gene encodes one network weight. Indirect encoding methods, where each gene can encode for multiple weights, shorten the genome to reduce the dimensions of the search space and better exploit permutations and symmetries. The Geometric Encoding for Neural network Evolution (GENE) introduced an indirect encoding where the weight of a connection is computed as the (pseudo-)distance between the two linked neurons, leading to a genome size growing linearly with the number of genes instead of quadratically in direct encoding. However GENE still relies on hand-crafted distance functions with no prior optimization. Here we show that better performing distance functions can be found for GENE using Cartesian Genetic Programming (CGP) in a meta-evolution approach, hence optimizing the encoding to create a search space that is easier to exploit. We show that GENE with a learned function can outperform both direct encoding and the hand-crafted distances, generalizing on unseen problems, and we study how the encoding impacts neural network properties.