 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data for Robust Runway Detection
Oct 23, 2025Deep vision models are now mature enough to be integrated in industrial and possibly critical applications such as autonomous navigation. Yet, data collection and labeling to train such models requires too much efforts and costs for a single company or product. This drawback is more significant in critical applications, where training data must include all possible conditions including rare scenarios. In this perspective, generating synthetic images is an appealing solution, since it allows a cheap yet reliable covering of all the conditions and environments, if the impact of the synthetic-to-real distribution shift is mitigated. In this article, we consider the case of runway detection that is a critical part in autonomous landing systems developed by aircraft manufacturers. We propose an image generation approach based on a commercial flight simulator that complements a few annotated real images. By controlling the image generation and the integration of real and synthetic data, we show that standard object detection models can achieve accurate prediction. We also evaluate their robustness with respect to adverse conditions, in our case nighttime images, that were not represented in the real data, and show the interest of using a customized domain adaptation strategy.
Style Transfer with Diffusion Models for Synthetic-to-Real Domain Adaptation
May 22, 2025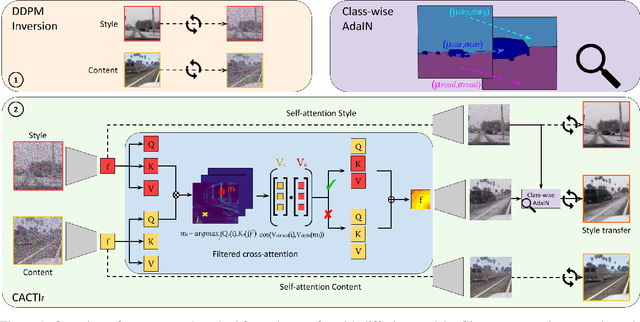
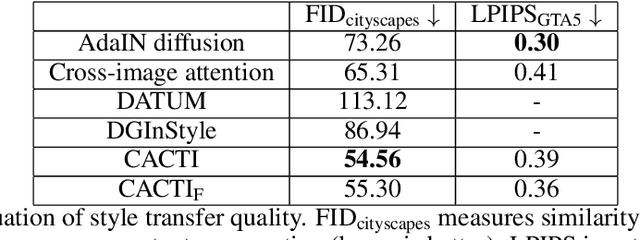

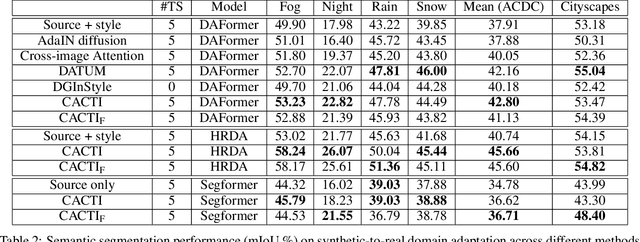
Semantic segmentation models trained on synthetic data often perform poorly on real-world images due to domain gaps, particularly in adverse conditions where labeled data is scarce. Yet, recent foundation models enable to generate realistic images without any training. This paper proposes to leverage such diffusion models to improve the performance of vision models when learned on synthetic data. We introduce two novel techniques for semantically consistent style transfer using diffusion models: Class-wise Adaptive Instance Normalization and Cross-Attention (CACTI) and its extension with selective attention Filtering (CACTIF). CACTI applies statistical normalization selectively based on semantic classes, while CACTIF further filters cross-attention maps based on feature similarity, preventing artifacts in regions with weak cross-attention correspondences. Our methods transfer style characteristics while preserving semantic boundaries and structural coherence, unlike approaches that apply global transformations or generate content without constraints. Experiments using GTA5 as source and Cityscapes/ACDC as target domains show that our approach produces higher quality images with lower FID scores and better content preservation. Our work demonstrates that class-aware diffusion-based style transfer effectively bridges the synthetic-to-real domain gap even with minimal target domain data, advancing robust perception systems for challenging real-world applications. The source code is available at: https://github.com/echigot/cactif.
Exploration by Running Away from the Past
Nov 21, 2024



The ability to explore efficiently and effectively is a central challenge of reinforcement learning. In this work, we consider exploration through the lens of information theory. Specifically, we cast exploration as a problem of maximizing the Shannon entropy of the state occupation measure. This is done by maximizing a sequence of divergences between distributions representing an agent's past behavior and its current behavior. Intuitively, this encourages the agent to explore new behaviors that are distinct from past behaviors. Hence, we call our method RAMP, for ``$\textbf{R}$unning $\textbf{A}$way fro$\textbf{m}$ the $\textbf{P}$ast.'' A fundamental question of this method is the quantification of the distribution change over time. We consider both the Kullback-Leibler divergence and the Wasserstein distance to quantify divergence between successive state occupation measures, and explain why the former might lead to undesirable exploratory behaviors in some tasks. We demonstrate that by encouraging the agent to explore by actively distancing itself from past experiences, it can effectively explore mazes and a wide range of behaviors on robotic manipulation and locomotion tasks.
Exploration by Learning Diverse Skills through Successor State Measures
Jun 14, 2024



The ability to perform different skills can encourage agents to explore. In this work, we aim to construct a set of diverse skills which uniformly cover the state space. We propose a formalization of this search for diverse skills, building on a previous definition based on the mutual information between states and skills. We consider the distribution of states reached by a policy conditioned on each skill and leverage the successor state measure to maximize the difference between these skill distributions. We call this approach LEADS: Learning Diverse Skills through Successor States. We demonstrate our approach on a set of maze navigation and robotic control tasks which show that our method is capable of constructing a diverse set of skills which exhaustively cover the state space without relying on reward or exploration bonuses. Our findings demonstrate that this new formalization promotes more robust and efficient exploration by combining mutual information maximization and exploration bonuses.
Quality with Just Enough Diversity in Evolutionary Policy Search
May 07, 2024



Evolution Strategies (ES) are effective gradient-free optimization methods that can be competitive with gradient-based approaches for policy search. ES only rely on the total episodic scores of solutions in their population, from which they estimate fitness gradients for their update with no access to true gradient information. However this makes them sensitive to deceptive fitness landscapes, and they tend to only explore one way to solve a problem. Quality-Diversity methods such as MAP-Elites introduced additional information with behavior descriptors (BD) to return a population of diverse solutions, which helps exploration but leads to a large part of the evaluation budget not being focused on finding the best performing solution. Here we show that behavior information can also be leveraged to find the best policy by identifying promising search areas which can then be efficiently explored with ES. We introduce the framework of Quality with Just Enough Diversity (JEDi) which learns the relationship between behavior and fitness to focus evaluations on solutions that matter. When trying to reach higher fitness values, JEDi outperforms both QD and ES methods on hard exploration tasks like mazes and on complex control problems with large policies.
Genetic Drift Regularization: on preventing Actor Injection from breaking Evolution Strategies
May 07, 2024Evolutionary Algorithms (EA) have been successfully used for the optimization of neural networks for policy search, but they still remain sample inefficient and underperforming in some cases compared to gradient-based reinforcement learning (RL). Various methods combine the two approaches, many of them training a RL algorithm on data from EA evaluations and injecting the RL actor into the EA population. However, when using Evolution Strategies (ES) as the EA, the RL actor can drift genetically far from the the ES distribution and injection can cause a collapse of the ES performance. Here, we highlight the phenomenon of genetic drift where the actor genome and the ES population distribution progressively drift apart, leading to injection having a negative impact on the ES. We introduce Genetic Drift Regularization (GDR), a simple regularization method in the actor training loss that prevents the actor genome from drifting away from the ES. We show that GDR can improve ES convergence on problems where RL learns well, but also helps RL training on other tasks, , fixes the injection issues better than previous controlled injection methods.
Kartezio: Evolutionary Design of Explainable Pipelines for Biomedical Image Analysis
Feb 28, 2023An unresolved issue in contemporary biomedicine is the overwhelming number and diversity of complex images that require annotation, analysis and interpretation. Recent advances in Deep Learning have revolutionized the field of computer vision, creating algorithms that compete with human experts in image segmentation tasks. Crucially however, these frameworks require large human-annotated datasets for training and the resulting models are difficult to interpret. In this study, we introduce Kartezio, a modular Cartesian Genetic Programming based computational strategy that generates transparent and easily interpretable image processing pipelines by iteratively assembling and parameterizing computer vision functions. The pipelines thus generated exhibit comparable precision to state-of-the-art Deep Learning approaches on instance segmentation tasks, while requiring drastically smaller training datasets, a feature which confers tremendous flexibility, speed, and functionality to this approach. We also deployed Kartezio to solve semantic and instance segmentation problems in four real-world Use Cases, and showcase its utility in imaging contexts ranging from high-resolution microscopy to clinical pathology. By successfully implementing Kartezio on a portfolio of images ranging from subcellular structures to tumoral tissue, we demonstrated the flexibility, robustness and practical utility of this fully explicable evolutionary designer for semantic and instance segmentation.
Curiosity creates Diversity in Policy Search
Dec 07, 2022



When searching for policies, reward-sparse environments often lack sufficient information about which behaviors to improve upon or avoid. In such environments, the policy search process is bound to blindly search for reward-yielding transitions and no early reward can bias this search in one direction or another. A way to overcome this is to use intrinsic motivation in order to explore new transitions until a reward is found. In this work, we use a recently proposed definition of intrinsic motivation, Curiosity, in an evolutionary policy search method. We propose Curiosity-ES, an evolutionary strategy adapted to use Curiosity as a fitness metric. We compare Curiosity with Novelty, a commonly used diversity metric, and find that Curiosity can generate higher diversity over full episodes without the need for an explicit diversity criterion and lead to multiple policies which find reward.
Architectural Optimization over Subgroups for Equivariant Neural Networks
Oct 11, 2022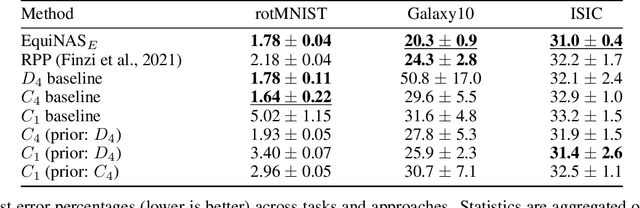
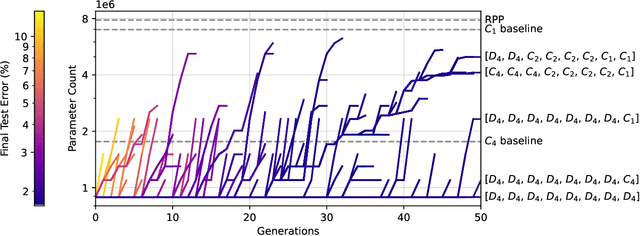

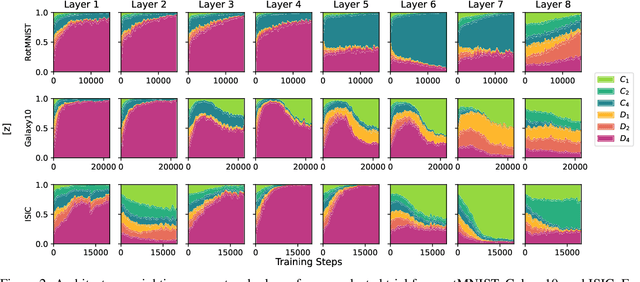
Incorporating equivariance to symmetry groups as a constraint during neural network training can improve performance and generalization for tasks exhibiting those symmetries, but such symmetries are often not perfectly nor explicitly present. This motivates algorithmically optimizing the architectural constraints imposed by equivariance. We propose the equivariance relaxation morphism, which preserves functionality while reparameterizing a group equivariant layer to operate with equivariance constraints on a subgroup, as well as the $[G]$-mixed equivariant layer, which mixes layers constrained to different groups to enable within-layer equivariance optimization. We further present evolutionary and differentiable neural architecture search (NAS) algorithms that utilize these mechanisms respectively for equivariance-aware architectural optimization. Experiments across a variety of datasets show the benefit of dynamically constrained equivariance to find effective architectures with approximate equivariance.
On Neural Consolidation for Transfer in Reinforcement Learning
Oct 05, 2022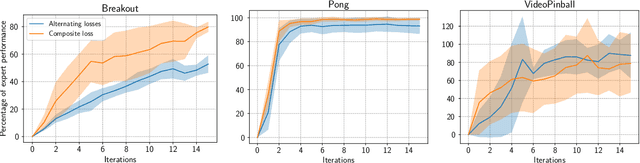
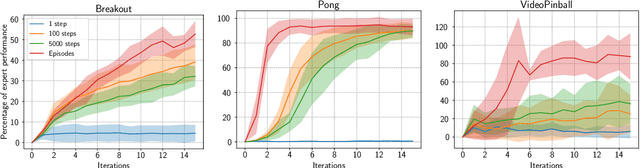
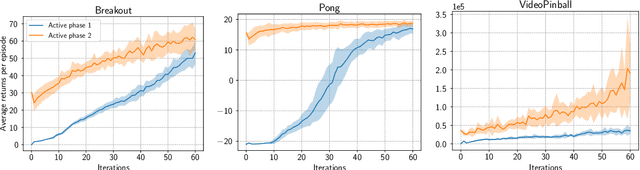
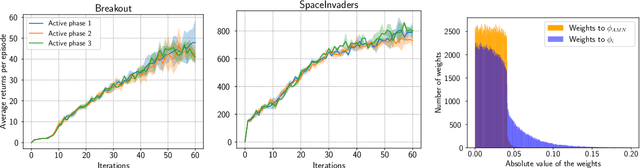
Although transfer learning is considered to be a milestone in deep reinforcement learning, the mechanisms behind it are still poorly understood. In particular, predicting if knowledge can be transferred between two given tasks is still an unresolved problem. In this work, we explore the use of network distillation as a feature extraction method to better understand the context in which transfer can occur. Notably, we show that distillation does not prevent knowledge transfer, including when transferring from multiple tasks to a new one, and we compare these results with transfer without prior distillation. We focus our work on the Atari benchmark due to the variability between different games, but also to their similarities in terms of visual features.