 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Dynamic Retargeting for Humanoid Imitation Learning from Videos
May 22, 2026Imitation Learning from monocular video demonstrations provides a scalable approach for teaching complex skills to humanoid robots. However, translating human motion to humanoids requires overcoming significant morphological mismatches. Standard approaches rely on Geometric Retargeting or Indirect Dynamic Retargeting pipelines. We identify that these intermediate kinematic projections introduce a geometric bias, restricting the search space and yielding suboptimal dynamic behaviors. In this paper, we propose Direct Dynamic Retargeting (DDR), a novel single-stage framework that generates high-fidelity, dynamically feasible trajectories directly from expert videos. By formulating the problem in the task space and leveraging a sampling-based Model Predictive Control solver within a physics simulator, DDR natively optimizes over complex contact sequences while mitigating input drift. Our experiments demonstrate that bypassing the geometric bias allows DDR to outperform state-of-the-art baselines in demonstration tracking accuracy. Furthermore, we establish that providing such physically viable references to RL agents accelerates training convergence and enhances the final execution of agile and balancing behaviors. Source code will be made publicly available.
On Neural Consolidation for Transfer in Reinforcement Learning
Oct 05, 2022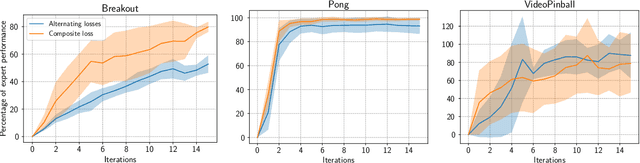
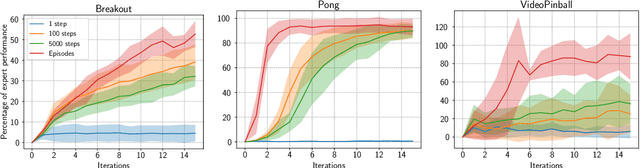
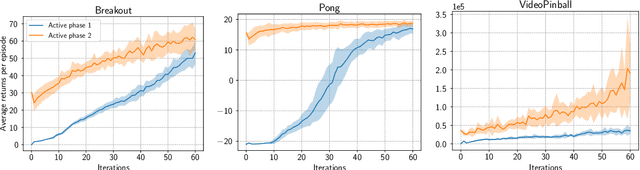
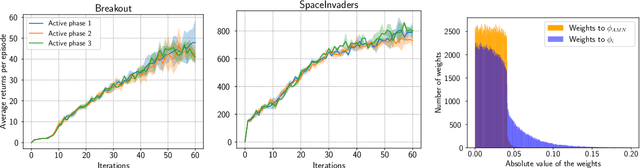
Although transfer learning is considered to be a milestone in deep reinforcement learning, the mechanisms behind it are still poorly understood. In particular, predicting if knowledge can be transferred between two given tasks is still an unresolved problem. In this work, we explore the use of network distillation as a feature extraction method to better understand the context in which transfer can occur. Notably, we show that distillation does not prevent knowledge transfer, including when transferring from multiple tasks to a new one, and we compare these results with transfer without prior distillation. We focus our work on the Atari benchmark due to the variability between different games, but also to their similarities in terms of visual features.
Neural Distillation as a State Representation Bottleneck in Reinforcement Learning
Oct 05, 2022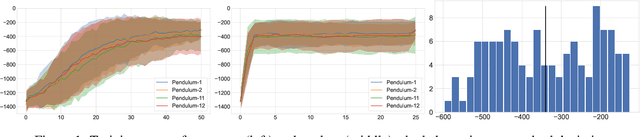

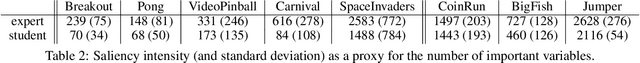

Learning a good state representation is a critical skill when dealing with multiple tasks in Reinforcement Learning as it allows for transfer and better generalization between tasks. However, defining what constitute a useful representation is far from simple and there is so far no standard method to find such an encoding. In this paper, we argue that distillation -- a process that aims at imitating a set of given policies with a single neural network -- can be used to learn a state representation displaying favorable characteristics. In this regard, we define three criteria that measure desirable features of a state encoding: the ability to select important variables in the input space, the ability to efficiently separate states according to their corresponding optimal action, and the robustness of the state encoding on new tasks. We first evaluate these criteria and verify the contribution of distillation on state representation on a toy environment based on the standard inverted pendulum problem, before extending our analysis on more complex visual tasks from the Atari and Procgen benchmarks.