 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Distillation as a State Representation Bottleneck in Reinforcement Learning
Paper and Code
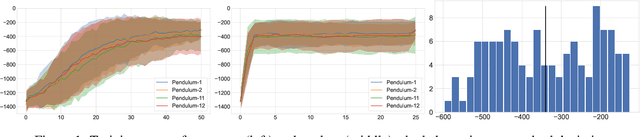

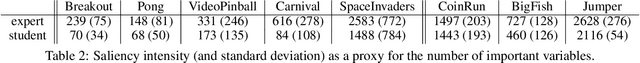

Learning a good state representation is a critical skill when dealing with multiple tasks in Reinforcement Learning as it allows for transfer and better generalization between tasks. However, defining what constitute a useful representation is far from simple and there is so far no standard method to find such an encoding. In this paper, we argue that distillation -- a process that aims at imitating a set of given policies with a single neural network -- can be used to learn a state representation displaying favorable characteristics. In this regard, we define three criteria that measure desirable features of a state encoding: the ability to select important variables in the input space, the ability to efficiently separate states according to their corresponding optimal action, and the robustness of the state encoding on new tasks. We first evaluate these criteria and verify the contribution of distillation on state representation on a toy environment based on the standard inverted pendulum problem, before extending our analysis on more complex visual tasks from the Atari and Procgen benchmarks.