 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning in Branch-and-Bound: Model-Based Reinforcement Learning for Exact Combinatorial Optimization
Nov 19, 2025
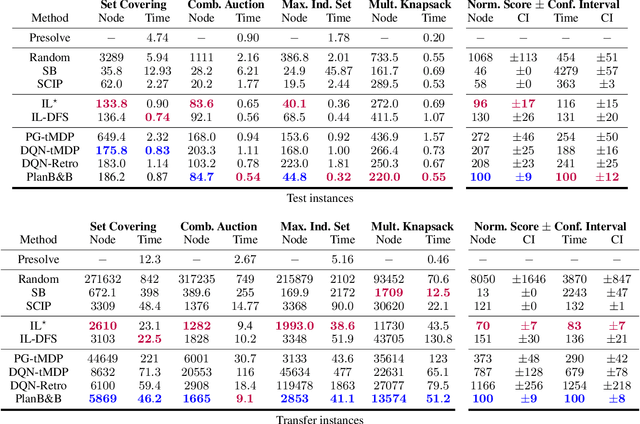


Mixed-Integer Linear Programming (MILP) lies at the core of many real-world combinatorial optimization (CO) problems, traditionally solved by branch-and-bound (B&B). A key driver influencing B&B solvers efficiency is the variable selection heuristic that guides branching decisions. Looking to move beyond static, hand-crafted heuristics, recent work has explored adapting traditional reinforcement learning (RL) algorithms to the B&B setting, aiming to learn branching strategies tailored to specific MILP distributions. In parallel, RL agents have achieved remarkable success in board games, a very specific type of combinatorial problems, by leveraging environment simulators to plan via Monte Carlo Tree Search (MCTS). Building on these developments, we introduce Plan-and-Branch-and-Bound (PlanB&B), a model-based reinforcement learning (MBRL) agent that leverages a learned internal model of the B&B dynamics to discover improved branching strategies. Computational experiments empirically validate our approach, with our MBRL branching agent outperforming previous state-of-the-art RL methods across four standard MILP benchmarks.
Influence branching for learning to solve mixed-integer programs online
Oct 05, 2025On the occasion of the 20th Mixed Integer Program Workshop's computational competition, this work introduces a new approach for learning to solve MIPs online. Influence branching, a new graph-oriented variable selection strategy, is applied throughout the first iterations of the branch and bound algorithm. This branching heuristic is optimized online with Thompson sampling, which ranks the best graph representations of MIP's structure according to computational speed up over SCIP. We achieve results comparable to state of the art online learning methods. Moreover, our results indicate that our method generalizes well to more general online frameworks, where variations in constraint matrix, constraint vector and objective coefficients can all occur and where more samples are available.
Exploration by Running Away from the Past
Nov 21, 2024



The ability to explore efficiently and effectively is a central challenge of reinforcement learning. In this work, we consider exploration through the lens of information theory. Specifically, we cast exploration as a problem of maximizing the Shannon entropy of the state occupation measure. This is done by maximizing a sequence of divergences between distributions representing an agent's past behavior and its current behavior. Intuitively, this encourages the agent to explore new behaviors that are distinct from past behaviors. Hence, we call our method RAMP, for ``$\textbf{R}$unning $\textbf{A}$way fro$\textbf{m}$ the $\textbf{P}$ast.'' A fundamental question of this method is the quantification of the distribution change over time. We consider both the Kullback-Leibler divergence and the Wasserstein distance to quantify divergence between successive state occupation measures, and explain why the former might lead to undesirable exploratory behaviors in some tasks. We demonstrate that by encouraging the agent to explore by actively distancing itself from past experiences, it can effectively explore mazes and a wide range of behaviors on robotic manipulation and locomotion tasks.
Solving robust MDPs as a sequence of static RL problems
Oct 08, 2024
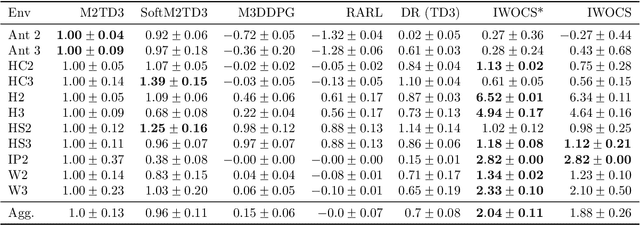
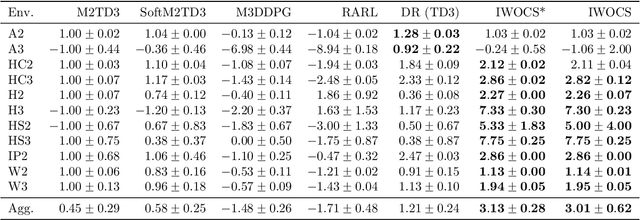
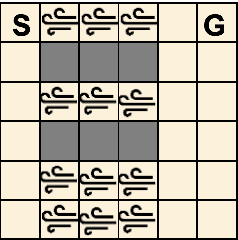
Designing control policies whose performance level is guaranteed to remain above a given threshold in a span of environments is a critical feature for the adoption of reinforcement learning (RL) in real-world applications. The search for such robust policies is a notoriously difficult problem, related to the so-called dynamic model of transition function uncertainty, where the environment dynamics are allowed to change at each time step. But in practical cases, one is rather interested in robustness to a span of static transition models throughout interaction episodes. The static model is known to be harder to solve than the dynamic one, and seminal algorithms, such as robust value iteration, as well as most recent works on deep robust RL, build upon the dynamic model. In this work, we propose to revisit the static model. We suggest an analysis of why solving the static model under some mild hypotheses is a reasonable endeavor, based on an equivalence with the dynamic model, and formalize the general intuition that robust MDPs can be solved by tackling a series of static problems. We introduce a generic meta-algorithm called IWOCS, which incrementally identifies worst-case transition models so as to guide the search for a robust policy. Discussion on IWOCS sheds light on new ways to decouple policy optimization and adversarial transition functions and opens new perspectives for analysis. We derive a deep RL version of IWOCS and demonstrate it is competitive with state-of-the-art algorithms on classical benchmarks.
The Overfocusing Bias of Convolutional Neural Networks: A Saliency-Guided Regularization Approach
Sep 25, 2024Despite transformers being considered as the new standard in computer vision, convolutional neural networks (CNNs) still outperform them in low-data regimes. Nonetheless, CNNs often make decisions based on narrow, specific regions of input images, especially when training data is limited. This behavior can severely compromise the model's generalization capabilities, making it disproportionately dependent on certain features that might not represent the broader context of images. While the conditions leading to this phenomenon remain elusive, the primary intent of this article is to shed light on this observed behavior of neural networks. Our research endeavors to prioritize comprehensive insight and to outline an initial response to this phenomenon. In line with this, we introduce Saliency Guided Dropout (SGDrop), a pioneering regularization approach tailored to address this specific issue. SGDrop utilizes attribution methods on the feature map to identify and then reduce the influence of the most salient features during training. This process encourages the network to diversify its attention and not focus solely on specific standout areas. Our experiments across several visual classification benchmarks validate SGDrop's role in enhancing generalization. Significantly, models incorporating SGDrop display more expansive attributions and neural activity, offering a more comprehensive view of input images in contrast to their traditionally trained counterparts.
Exploration by Learning Diverse Skills through Successor State Measures
Jun 14, 2024



The ability to perform different skills can encourage agents to explore. In this work, we aim to construct a set of diverse skills which uniformly cover the state space. We propose a formalization of this search for diverse skills, building on a previous definition based on the mutual information between states and skills. We consider the distribution of states reached by a policy conditioned on each skill and leverage the successor state measure to maximize the difference between these skill distributions. We call this approach LEADS: Learning Diverse Skills through Successor States. We demonstrate our approach on a set of maze navigation and robotic control tasks which show that our method is capable of constructing a diverse set of skills which exhaustively cover the state space without relying on reward or exploration bonuses. Our findings demonstrate that this new formalization promotes more robust and efficient exploration by combining mutual information maximization and exploration bonuses.
Time-Constrained Robust MDPs
Jun 12, 2024Robust reinforcement learning is essential for deploying reinforcement learning algorithms in real-world scenarios where environmental uncertainty predominates. Traditional robust reinforcement learning often depends on rectangularity assumptions, where adverse probability measures of outcome states are assumed to be independent across different states and actions. This assumption, rarely fulfilled in practice, leads to overly conservative policies. To address this problem, we introduce a new time-constrained robust MDP (TC-RMDP) formulation that considers multifactorial, correlated, and time-dependent disturbances, thus more accurately reflecting real-world dynamics. This formulation goes beyond the conventional rectangularity paradigm, offering new perspectives and expanding the analytical framework for robust RL. We propose three distinct algorithms, each using varying levels of environmental information, and evaluate them extensively on continuous control benchmarks. Our results demonstrate that these algorithms yield an efficient tradeoff between performance and robustness, outperforming traditional deep robust RL methods in time-constrained environments while preserving robustness in classical benchmarks. This study revisits the prevailing assumptions in robust RL and opens new avenues for developing more practical and realistic RL applications.
RRLS : Robust Reinforcement Learning Suite
Jun 12, 2024Robust reinforcement learning is the problem of learning control policies that provide optimal worst-case performance against a span of adversarial environments. It is a crucial ingredient for deploying algorithms in real-world scenarios with prevalent environmental uncertainties and has been a long-standing object of attention in the community, without a standardized set of benchmarks. This contribution endeavors to fill this gap. We introduce the Robust Reinforcement Learning Suite (RRLS), a benchmark suite based on Mujoco environments. RRLS provides six continuous control tasks with two types of uncertainty sets for training and evaluation. Our benchmark aims to standardize robust reinforcement learning tasks, facilitating reproducible and comparable experiments, in particular those from recent state-of-the-art contributions, for which we demonstrate the use of RRLS. It is also designed to be easily expandable to new environments. The source code is available at \href{https://github.com/SuReLI/RRLS}{https://github.com/SuReLI/RRLS}.
Bootstrapping Expectiles in Reinforcement Learning
Jun 06, 2024
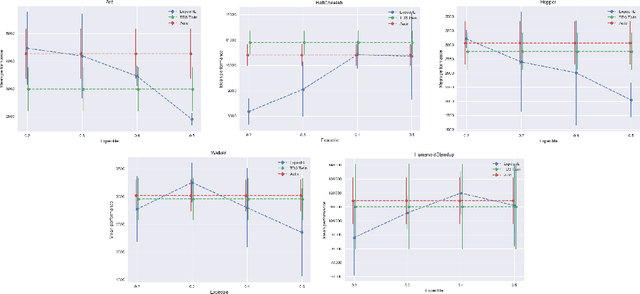
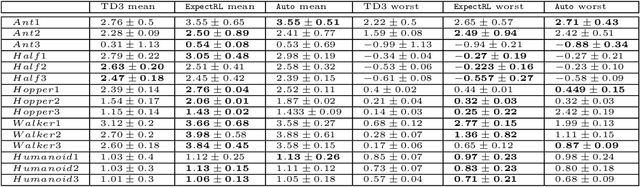
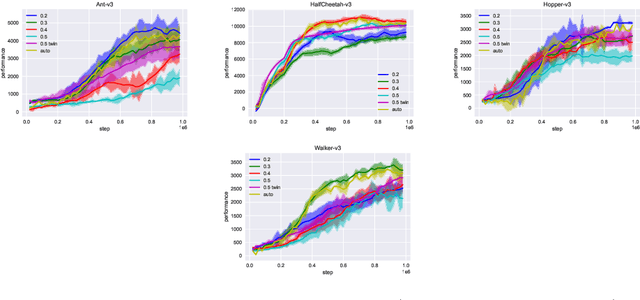
Many classic Reinforcement Learning (RL) algorithms rely on a Bellman operator, which involves an expectation over the next states, leading to the concept of bootstrapping. To introduce a form of pessimism, we propose to replace this expectation with an expectile. In practice, this can be very simply done by replacing the $L_2$ loss with a more general expectile loss for the critic. Introducing pessimism in RL is desirable for various reasons, such as tackling the overestimation problem (for which classic solutions are double Q-learning or the twin-critic approach of TD3) or robust RL (where transitions are adversarial). We study empirically these two cases. For the overestimation problem, we show that the proposed approach, ExpectRL, provides better results than a classic twin-critic. On robust RL benchmarks, involving changes of the environment, we show that our approach is more robust than classic RL algorithms. We also introduce a variation of ExpectRL combined with domain randomization which is competitive with state-of-the-art robust RL agents. Eventually, we also extend \ExpectRL with a mechanism for choosing automatically the expectile value, that is the degree of pessimism
Quality with Just Enough Diversity in Evolutionary Policy Search
May 07, 2024



Evolution Strategies (ES) are effective gradient-free optimization methods that can be competitive with gradient-based approaches for policy search. ES only rely on the total episodic scores of solutions in their population, from which they estimate fitness gradients for their update with no access to true gradient information. However this makes them sensitive to deceptive fitness landscapes, and they tend to only explore one way to solve a problem. Quality-Diversity methods such as MAP-Elites introduced additional information with behavior descriptors (BD) to return a population of diverse solutions, which helps exploration but leads to a large part of the evaluation budget not being focused on finding the best performing solution. Here we show that behavior information can also be leveraged to find the best policy by identifying promising search areas which can then be efficiently explored with ES. We introduce the framework of Quality with Just Enough Diversity (JEDi) which learns the relationship between behavior and fitness to focus evaluations on solutions that matter. When trying to reach higher fitness values, JEDi outperforms both QD and ES methods on hard exploration tasks like mazes and on complex control problems with large policies.