 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration by Learning Diverse Skills through Successor State Measures
Jun 14, 2024



The ability to perform different skills can encourage agents to explore. In this work, we aim to construct a set of diverse skills which uniformly cover the state space. We propose a formalization of this search for diverse skills, building on a previous definition based on the mutual information between states and skills. We consider the distribution of states reached by a policy conditioned on each skill and leverage the successor state measure to maximize the difference between these skill distributions. We call this approach LEADS: Learning Diverse Skills through Successor States. We demonstrate our approach on a set of maze navigation and robotic control tasks which show that our method is capable of constructing a diverse set of skills which exhaustively cover the state space without relying on reward or exploration bonuses. Our findings demonstrate that this new formalization promotes more robust and efficient exploration by combining mutual information maximization and exploration bonuses.
Qualitative Possibilistic Mixed-Observable MDPs
Sep 26, 2013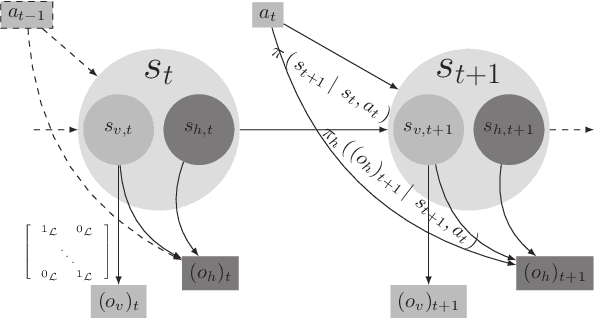

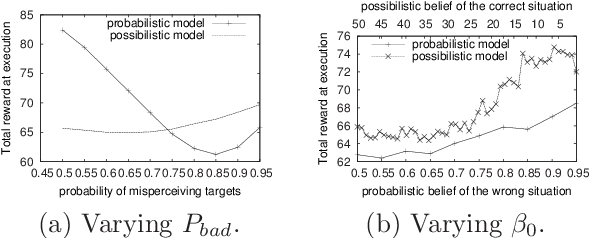
Possibilistic and qualitative POMDPs (pi-POMDPs) are counterparts of POMDPs used to model situations where the agent's initial belief or observation probabilities are imprecise due to lack of past experiences or insufficient data collection. However, like probabilistic POMDPs, optimally solving pi-POMDPs is intractable: the finite belief state space exponentially grows with the number of system's states. In this paper, a possibilistic version of Mixed-Observable MDPs is presented to get around this issue: the complexity of solving pi-POMDPs, some state variables of which are fully observable, can be then dramatically reduced. A value iteration algorithm for this new formulation under infinite horizon is next proposed and the optimality of the returned policy (for a specified criterion) is shown assuming the existence of a "stay" action in some goal states. Experimental work finally shows that this possibilistic model outperforms probabilistic POMDPs commonly used in robotics, for a target recognition problem where the agent's observations are imprecise.